
【前言】
作为风控的最后一环,强大的催收能力,对于银行和互联网金融公司而言,都意义重大。特别是随着互联网金融的普及,以及借贷渠道的线上化,传统的催收模式已经无法匹配不良资产的扩张规模。同时,上半年催收自律公约的出台,表明社会对催收行业的规范化需求日益增加。行业的数字化运营,正逢其时。
另一方面,作为与借款人沟通的直接渠道,催收电话的内容实际上可以反映借款人非常多额外的有用信息。从借款人近况、亲友关系,到情绪识别和施压点挖掘,庞大的历史催收录音,实际上有很大的想象空间。以往对于这一块庞大的非结构化数据,我们并没有善加利用。而随着ASR以及NLP技术的日趋成熟,对这些数据的商业运用也成为可能。
“催记补完计划”,就是在这样的背景下诞生的!
【什么是催记】
催记,是催收人员在每通电话之后,对于通话结果的记录。在我们着手对这些录音进行深挖之前,这些人工标注是我们对于每通电话录音的唯一信息保存。催记对于整体催收业务有非常重要的意义,主要包括:
1. 记录用户有效信息,包括约定还款时间,答应转告等,便于后续用户跟进;
2. 对于后续模块的催收,比如M2、M3,前期的催记能够帮助催收人员对于电话另一端的欠款人有更丰富的历史信息和用户画像,这样话术和施压点都可以做针对性的定制;
3. 催记对用户的描述和刻画,对于后期基于催收场景的数据分析和建模,都可以提供更加丰富和重要的变量,包括配合度、还款意愿、用户性格等。
实际落地实施的时候,也会遇到一些问题:
1. 除了一些基本的催记,很多额外的信息,经办没有精力和激励来保证催记质量;
2. 降低了催收人员日拨打次数;
3. 不同经办对催记理解不一;
4. 一通电话的有效信息往往不止一个。
正是基于此,对催收录音进行有效信息的自动提取,成为了天然而迫切的需求。以往由于技术不成熟,这一块没有特别多进展。但近期ASR和NLP技术的成熟,使得上述构想成为可能。
截至目前,我们在三个主要催记的预测精度上,都优于人工标签。并且,算法本身还有可以优化的空间。下面,我们会对所用到的方法进行简要的介绍。
【算法介绍】
“催记补完计划”的整体流程如下: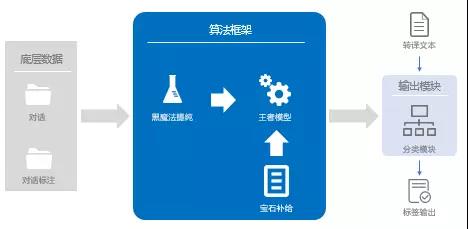

其中,在中间的算法框架内,“王者零号机”部分,实现基于对话记录的多标签分类;“黑魔法提纯”解决现有对话标注准确率较低的问题;“宝石补给”部分,实现对“王者零号机”关键短语的相关推荐。下面会基于这三个部分做进一步的展开。
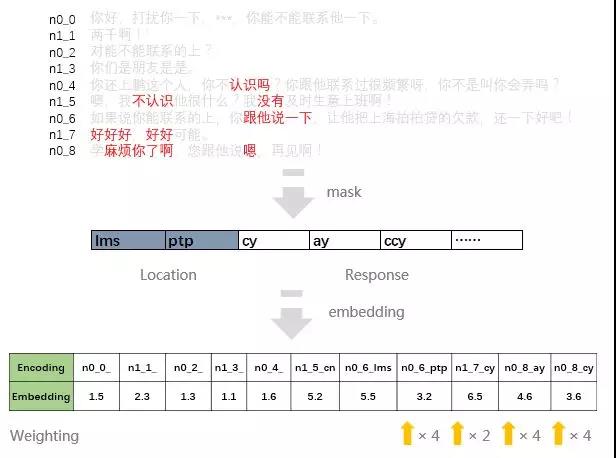
王者零号机的输入端,就是对话文本和对应的催记。比如下面的一段对话文本:
对应的催记标签是“PTP”,即“承诺3日内还款”。从例子中可以看出,我们在建模过程中会遇到两个难点:
1. 数据是语音转写数据,翻译准确率有限,且方言的转译准确率较低。
2. 数据是QA对,不是文章。往往需要从提问的角度确定标签的种类,从回答的内容确定标签的子类,如,从QA中找到提问是否愿意转告的相关问题,确定此标签种类为转告类型,再从相应回复中判断是否转告,即转告或者不转告。但是实际数据中QA往往不是一一对应的,并且由于是多轮会话,存在指代歧义的问题。
针对以上两点难点,我们采用如下的算法流程进行解决,这也是我们的“王者零号机”框架(图中的NOST,OPTP,LMS 分别表示“未达成还款协议”,“愿意代为偿还”和“愿意留言转告):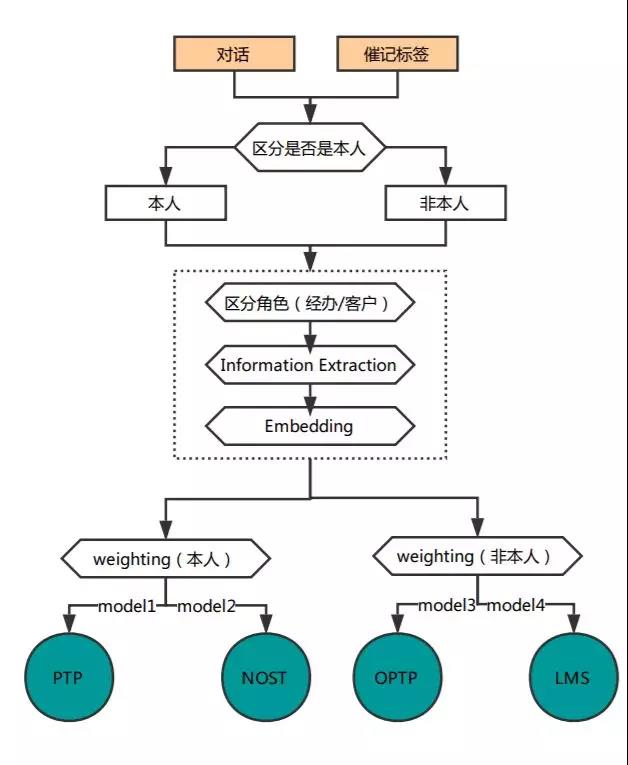
对于第一个难点,由于转译质量的问题,我们选择使用关键信息抽取(Information Extraction)的方式,即根据滑窗 (Moving Window) 来找到我们指定的关键短语,并且打上相关的标签。这样做既可以尽可能的避免无关的语义转写错误给模型带来的影响,又能将有效信息尽量压缩整合。
而第二个难点,我们采用将事先准备的关键短语标签分成两种类型,Location,即用来定位相关用户问题,和Response,即用来标记回答类型。具体内容如下图:
另外,在提取信息的过程中,同时考虑了声道和顺序 seq_id。将三者信息拼接起来,如n0_0_ptp, 标识了n0角色在对话最开始的位置发起了ptp的提问。由于对话长短不一,我们在拼接前根据对话长度对seq_id做归一化处理。
整体的文字处理部分,即从Information Extraction,到embedding的部分,示意如下:
上述文本处理完之后,我们选用的模型是NB-LR (Naïve-Bayes – Logistic Regression)。由于训练标签的准确性较低,不能直接用于训练模型(尝试使用这些标签训练模型,在测试集上target的recall为6/140)。在不过多引入人力标记的情况下,我们借鉴了TSVM (Transductive Support Vector Machines) 的思想,用半监督模型来“提纯”现有标签。
TSVM, 即根据部分有标记的数据对未标记的样本进行各种可能的标记指派。基于该思想,我们用部分有准确标记的样本对‘伪标记’(标签很有可能不准确) 的样本进行指派,结合指派结果,将指派标记和‘伪标记’不同的样本更换模型样本(使用指派标记和“伪标记”相同的样本集合)再次指派,重复此步骤,直到达到停止条件。
从模型表现来看,使用提纯之后的样本点(表2),模型表现要优于直接使用原始数据(表1),同时表现也好于人工的催记(表3)
由于第一部分中指定关键词需要人工总结,工作量较大,所以采用正则+距离相似度+n-gram的方式,根据已有标签下的关键短语,来推荐相关的关键短语。这里分为两个步骤:
首先,将需要查找的语料按照标点符号分句,生成短句集合,之后用所选标签类型(如lms,ptp等)的关键短语对短语集合进行逐字匹配。根据匹配的集合字数占被匹配关键短语字数的占比和匹配的集合字数占被匹配短句字数的占比,对匹配短句做初步筛选。
随后,基于预训练的word_level 的word2vec对每个关键短语和初筛出的短句集合计算距离相似度,这里用的是欧式距离。之后根据相似度做再次筛选,针对每个关键短语对应的短语集合做自定义n-gram的词频统计,按照词频统计,在 n-gram短语中挑选符合的关键短语。依据上述逻辑,从语料中找到的额外关键短语。
这里以“听不清楚”为例: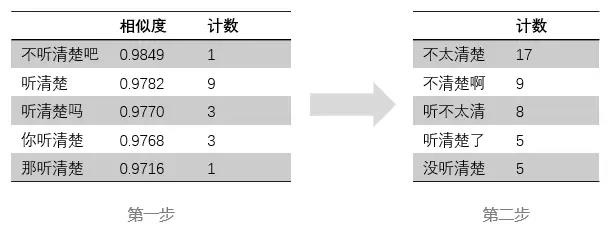
可以看到,可以通过我们的方式,获得更多额外的和“听不清楚”相似的短语。
通过此工具,我们对原本基于人工总结的配置文件进行了扩充,PTP模型的recall在precison不变的情况下从85%提高到了95%。

【未来计划】
从上面的结果可以看出,目前的“催记补完计划 1.0”,已经可以达到现有人工的标记精度。这就意味着,只要在工程上能够解决时效性,现有的模块能够真正解放催收人员的双手。另外,上述方式只需要对“宝石补给”部分进行定制化的修改,就能够扩展到其他关键点的预测,比如“经济困难”、“恶意欠款”等。在有了丰富的关键信息之后,基于这些信息的催收话术推荐,也有了实现的数据积淀。
【后记】
在提出构想到最后实现功能模块的过程中,我们深刻体会到,业务需求导向才是模型算法的根基。不论是标签的选取和制定,产品的时效性要求,还是终端用户的产品展示形态,都是在我们和业务方的频繁沟通下,才最终敲定的。正是业务方从始至终的深入参与,才保证了我们的道路没有跑偏,最终的产出不是一个华而不实的空中楼阁。
【参考文献】
[1] Wang, S., Manning, C.D. : Baselines and Bigrams: Simple, Good Sentiment and Topic Classification. In: Proceedings of the 50th ACL: short Papers, vol. 2,pp.90-94 (2012)