
在这个日新月异的科技发展时代,机器学习领域每月每日甚至于每分每秒,都在刷新着人们的认知。前沿的算法帮助企业挖掘数据中深层次情报,打造人工智能开放平台,促进商业智能的可扩展性,为各行各业带来了革命性的进步。但在实际应用中,找到最优的模型结构往往需要大量的调试,并且对于一个新的数据集仍然需要投入同样的资源重新搜索,纯人工的方式显然有些力不从心。于是,2018年AutoML横空出世,正式拉开了一个全新时代的序幕:人工智能点开了“繁衍”的新技能。
如今,自动化的机器学习平台已然落地变成了拍拍贷风控系统构建中重要的一环。它让机器学习不再依赖于程序员构建的框架,使模型实现了自我创造,自我更新,自我升级,甚至在很多场景下将一众设计同类算法的“调参”工程师甩在身后,不但大大节约了人力,也在模型精度和效率方面有了极大的提升。
概念如此大行其道,但自动化机器学习真的有那么神奇吗?人工智能是否真的实现了“繁衍”,获得了作为生命被定义的入场券?今天让我们一起为自动化机器学习平台去神秘化,走近它的探索之路。
揭秘AutoML
AutoML的主要任务是帮助数据科学家自动创造深度网络结构,完全超参数优化,来训练一个高质量的模型。我们可以先看看传统情况下我们是怎么逐步改进深度学习模型的:


如上图所示,在一般情况下,研究员会先根据自己的经验及思考设计模型结构,然后实现算法并评估效果,从而根据实验结果来验证或更新自己的想法,开始下一次的尝试。
而现在AutoML采用的技术来自于强化学习,它可以通过不断的学习和尝试,让自己变成算法专家,对应用环境做出实时反馈,动态重构整套模型。

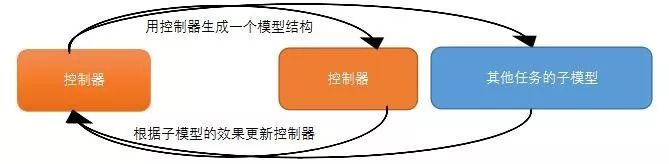
通过AutoML的示意图(上图),我们会发现它的结构和我们平时工作的流程非常相似,整个的训练流程是一个强化学习过程。左边的橙色框代表的是强化学习的控制器(主模型),它的任务是输入一个子模型结构T,并预测出相应概率P,对于越优质的子模型T,输出的P值越高。另一边蓝色框中的模型就是子模型T,是我们实际用来完成机器学习任务的模型。其预测精度R可视为强化学习中的奖励,优质的子模型结构T,总能得到更高的奖励。伴随着训练的持续进行,主模型的判断能力会逐步提升,并最终找出一个适应当前任务的模型结构(如同研究员在不断试验中快速积累经验,并最终成长为模型专家)。
生成子模型T的过程使用随机采样的方式,控制器认为越优质的模型有越大被采样到的概率,而更新控制器的方法则是梯度下降。这是一个经典的强化学习流程。整套流程的难点之一在于如何训练一个有效的主模型来预测概率P。因为现实应用中神经网络的结构往往是及其复杂,不定大小的。在一般框架下并不容易将这样动态的结构作为机器学习过程的输入。为了解决这个问题,AutoML通过编码技巧将神经网络编码成一个串,然后用RNN来预测这个串所代表神经网络应有的概率P。就好像我们先把一个网络结构描述成一段话,再用RNN去处理这一段话一样。
流程的另一难点在于,当主模型给出一个新的子模型结构时,模型需要重新训练才能得到最后的奖励R。针对这一问题,利用遗传算法,参数共享等思路的应用,在不改变整个训练大框架的前提下,将之前子模型训练得到的较好的参数分享给之后结构差不多的子模型,从而加速之后的子模型的训练速度,提高了整个强化学习算法的效率。
AutoML在拍拍贷
作为国内首家纯信用平台,拍拍贷一直以其精准稳健的风险管理称道于业界,自主研发了依托集大数据、云计算和人工智能等科技为一体的“魔镜”大数据风控系统,持续贯彻“科技为金融赋能”的理念。现今,拍拍贷紧随时代潮流,开发Auto ML(这里不是谷歌的AutoML,是拍拍贷内部算法平台,idea上向大佬看齐。)平台,推动AI民主化。服务于自身业务,不断提高自身的技术水平。
拍拍贷内部开发Auto ML平台主要出于两个目的的考虑。
第一点,我们希望拍拍贷内部的分析师们可以通过Auto ML平台满足自身的建模需求。随着拍拍贷的各个业务线都从数据模型中得到各种各样的好处,越来越多的建模需求来到数据挖掘和数据研发部门。其中很多需求都非常相似,于是我们把应对这些相似需求的算法做好封装,发布到Auto ML平台中。通过使用Auto ML平台上的算法,可以让业务方的商业分析师自助建模,从而很好地减轻了数据挖掘和数据研发部门的模型开发压力,使之可以集中精力开发技术要求更高且应用更广泛的模型和算法。并将其中一部分沉淀入机器学习平台,形成良性循环。
第二点,我们希望向Amazon,阿里建云的过程学习,通过建立这个平台,先服务自身,逐渐积累服务金融场景下全自动模型算法的经验和数据。为之后更广泛地服务整个金融行业做准备。我们通过平台收集业务方的建模信息,同时通过算法来调整自己的结构和参数,优化自身的自动建模服务。在一次次的不断建模过程中为AutoML算法(一个自优化算法,但拍拍贷内部尚未使用ENAS,大结构类似。)提供数据,不断提高模型性能。另外在建立平台之后,我们也经常发现我们提供的功能并不是业务方需要的,而业务方需要的一些功能我们并不提供,这时我们就可以及时调整,避免闭门造车的情况发生。
在当前,拍拍贷的机器学习平台以提供Jupyter Notebook环境为主。环境中内置了经过优化和封装的基础算法和各种小工具并预装了数据分析需要的主流工具。由有代码能力的商业分析师自行取用就可以了。工具能够自动收集必要的信息自我优化。随着平台的逐渐成熟,我们也希望能推广它的使用范围。现在开发部门正在开发图形化界面,未来将有GUI提供给并没有编程能力的小伙伴。
正在开发中的GUI界面:
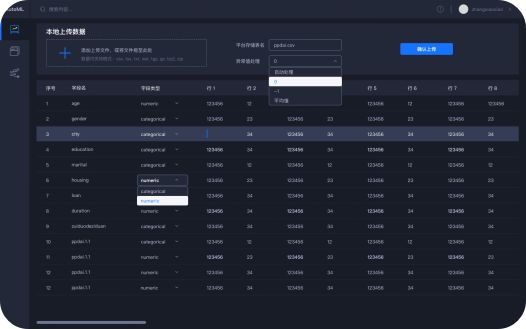
Auto ML平台能很大地帮助了商业分析师。以最常见的逾期率预测为例。当分析师准备好数据之后就可以直接建模了。在模型训练阶段,算法能够实现缺失值,类型型变量,非平衡数据,以及无标签数据(拒绝推断)和图关系嵌入的全自动傻瓜式处理,并自动匹配合适的模型,完成架构设计和超参数优化,将效率提升2倍以上的同时精度提高15%。除此之外,值得一提的是平台自带金融属性,和其他现有自动机器学习训练平台不同,我们会格外关注模型在时间上的稳定性,因此在设计之初就能单独选择数据的时间维度,并且可以自动跟踪时间上特征和目标的偏移,最后在建模的时候自动消除。
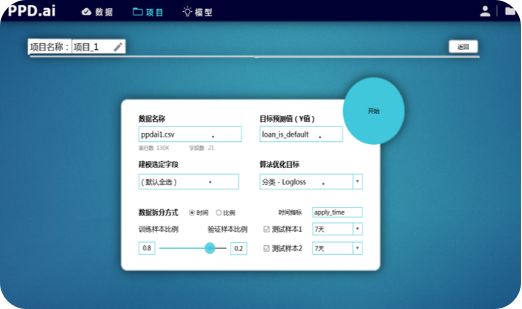
当建模完成后,平台会返回丰富的且专业的模型报告。操作人员可以通过报告,看到模型结构细节和参数设置,检验模型合理性及运行效果,从而利用模型结论发掘与阐释新规则,极大地提高模型迭代效率。
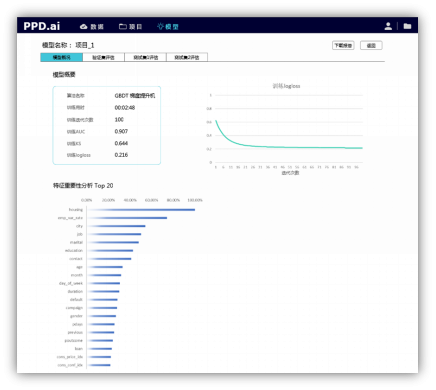
当然,平台有着更多种多样的功能,以满足更细节的分析需求,我们可以通过选择来自定义模型报告的模块内容及相关图表。比如,我们可以在其中添加一张特征交叉表,用来找寻特征间的非线性关系。如下图
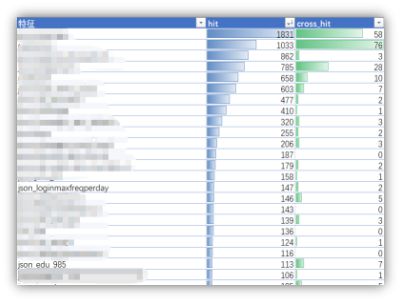
考虑GBDT模型下额度与各变量的交叉关系可以发现,登录频次和逾期相关但和给额交叉小,学历信息虽然对逾期影响不那么大但是和额度交叉大。这是符合业务逻辑的,登录频次对欺诈风险更重要而学历对信用风险更重要。
未来的MLPlat
虽然从大框架来看,这套系统所需要的计算量消耗巨大。在当前的ML框架中,抽取一次子模型,完成一轮训练,便能通过预测分给主模型一次奖励。而在自举框架中,可能要完成整个特定任务后才能得到一次反馈,如何加强信息的利用就变得十分关键。
但技术发展是瞬息万变的。犹记得AlphaGo刚刚击败樊麾的时候是在2015年10月,却在一年之后便完胜世界排名第一的柯洁,60余场与人类顶级高手的对决,无一败绩。而在2017年10月,谷歌紧接着发表的AlphaGo Zero,短短两年时间内已经成长成为一个全能的棋类算法,在围棋,国际象棋,将棋游戏中都击败了世界最高水平。同理,或许再过不足一年半载,自主学习平台就可以真正意义上实现自我创造,自我评估,自我更新,在多个机器学习领域全面展开应用,占据主导地位了。
而拍拍贷一直致力于紧跟前沿潮流,坚持自主研发,以技术赋能金融为支点,开拓更多场景应用,从而服务于全行业乃至全社会。相信,未来我们会让风控更简单。
![]()
![]()
ⅰ Neural Architecture Search with Reinforcement Learning, Barret Zoph, Quoc V. Le. International Conference on Learning Representations, 2017.
ⅱ Ronald J. Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. In Machine Learning, 1992.
ⅲ Efficient Neural Architecture Search via Parameter Sharing,Pham, Hieu; Guan, Melody Y.; Zoph, Barret; Le, Quoc V.; Dean, Jeff,02/2018
ⅳ Randal S. Olson, Ryan J. Urbanowicz, Peter C. Andrews, Nicole A. Lavender, La Creis Kidd, and Jason H. Moore (2016). Automating biomedical data science through tree-based pipeline optimization