
自从互联网大数据开始崭露头角之际,爬虫与反爬虫就成了业界永恒的话题,在这个资讯爆炸的时代占有一席之地。
有道是“道高一尺,魔高一丈”。你有动态验证,我有请求伪装。你有动态渲染,我有浏览器注入。你有ip限制,我有无限代理池。你有验证码,我有机器学习。
反爬虫必须要考虑真实用户的实际体验,而爬虫只需关注速度,先天的弱势条件使我们不得不尝试另辟蹊径(天外音:我们不和爬虫斗了)。
那么人相比普通的机器的优势在哪里呢?我们看看下面这句话:
研表究明,汉字序顺并不定一影阅响读!事证实明了当你看这完句话之后才发字现都乱是的。
人还是可以正常的阅读这些文字,但是机器却由于各种语义问题而陷入混乱。
当然我们不可能缺德到让用户都阅读这样的文字,只要能影响到机器的语义识别就足够了。虽然我们不能替换文字序列,但可以对文字本身进行乾坤大挪移,这就是我们今天要介绍的字体替换大法。
字体的开发工具有很多,这里我们作为演示选择adobe的AFDKO(https://www.adobe.com/devnet/opentype/afdko.html),首先我们使用其附带的ttx工具把要进行替换的字体文件解析成原始的font table。
接下来我们来了解下Font Table的规范:
Font Table的本质是一个xml的格式定义,这里我们重点要看的是其中的字体样式表
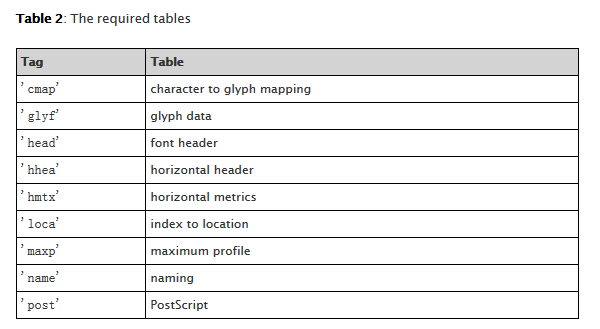

字体替换在这里有两种做法,一种是在cmap里做字体映射,但是这么做会存在生成的字体被反向出码表的隐患,所以我们需要完整的在glyf区段对字体的glyph内容进行替换。
我们先来做个简单的测试,打开微软雅黑的字体文件,我们能看到这样的字体预览

把全球两字的字模替换成世界,具体来说就是
全(U+5168)—— 世(U+4E16)
球(U+7403)—— 界(U+754C)
我们在glyf区段把他们对应的码表互换一下,然后用ttx重新编译字体,重新预览生成的字体文件就能完美展现我们需要的结果

在实际使用中,我们需要根据实际需要来决定需要打乱的字符集。然后对照混淆前后的码表对文字进行逐字替换。
对于普通用户来说,经过混淆后爬虫爬取的数据都是加密的信息,但是由于有自定义字体这层“密码本”,普通用户却可以完全无感知的阅读所有内容。
从本质上来说,这种做法是比较古典的传统字典加密法。英文由于只有26个字母,通过概率预测还是比较容易还原字典的。但是汉字的博大精深使得破解的成本大幅度提高,这便是字体加密立足的根基。