
为什么选择Spark
随着业务的发展, 现行数仓的一些工作模式已经无法满足新的业务场景, 这些问题促使我们开始尝试使用一些新的技术和工具。
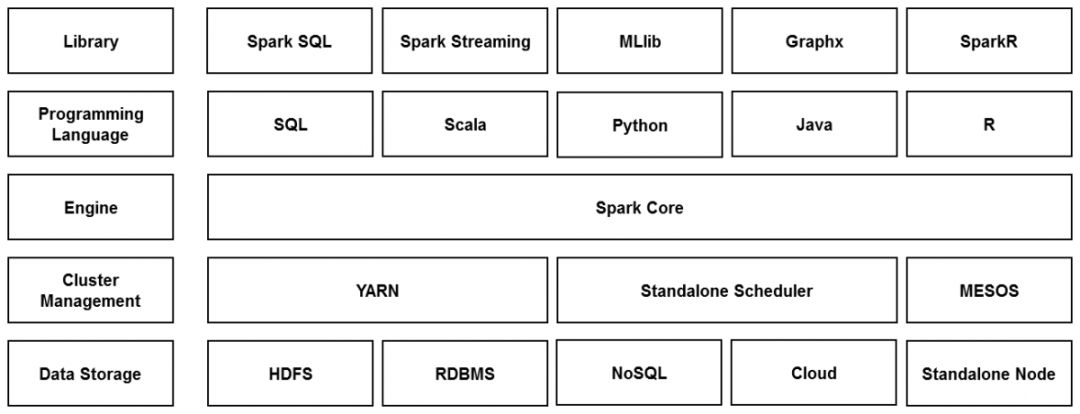

Apache Spark是专为大规模数据处理而设计的快速通用的计算引擎。
- Spark把运算的中间数据存放在内存,迭代计算效率更高;
- 易于使用,支持SQL,Scala,Python,Java等多语言;
- 兼容性强,Spark提供了一个强大的技术栈, 实现一体化 多元化的大数据处理平台,轻松应对大数据处理的查询语言Spark SQL,机器学习工具Mllib,图计算工具GraphX,实时流处理工具Spark Streaming无缝连接;
- Spark与Hadoop集群相互集成,支持Hadoop YARN,Apache Mesos及其自带的独立集群管理器。
总而言之,Spark拥有一站式数据处理的能力。
从未来技术战略上看,Spark将是最广泛使用的一个工具,除了做批处理,我们还需要有能力处理实时数据,图计算和机器学习。
Spark实战
集群环境
- Spark: 2.2.0
- Hadoop: 2.6.0-cdh5.12.1
- Hive: 1.1.0-cdh5.12.1
- Mysql数据库的驱动Jar包: mysql-connector-java-5.1.47.jar
- Kudu的驱动Jar包: kudu-spark2_2.11-1.4.0-cdh5.12.2.jar
- Eleasticsearch的驱动Jar包: elasticsearch-spark-20_2.11-5.0.2.jar
- Phoenix的驱动Jar包: phoenix-4.14.0-HBase-1.2-client.jar
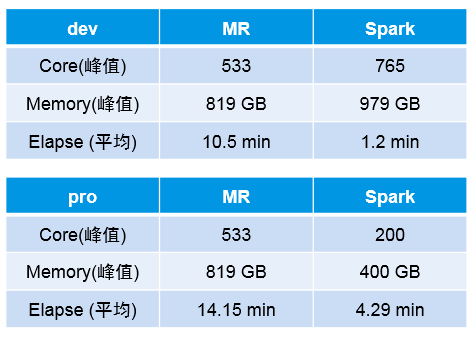
SparkSQL取代Hive的查询引擎, Spark取代MapReduce做计算。我们找了一个案例,最终导出的数据集有3800多万条,有一定逻辑复杂度和时间需求。
在sbt配置文件中添加依赖:
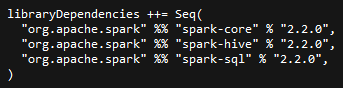
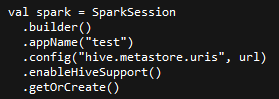
Spark2连接hive的使用方法:
下面是测试集群和生产集群的对比,生产集群对spark的资源做了限制:
Kudu是对HDFS和HBase功能上的补充, 为构建实时BI系统做准备。智能后台老客CRM基础数据通过MR导入,表映射HDFS文件。智能后台新客CRM的基础数据通过Spark导入Kudu,实现与Kudu直接交互。
在sbt配置文件中添加依赖:
![]()
![]()
Spark连接Kudu及数据操作:

下面是新老任务的对比:
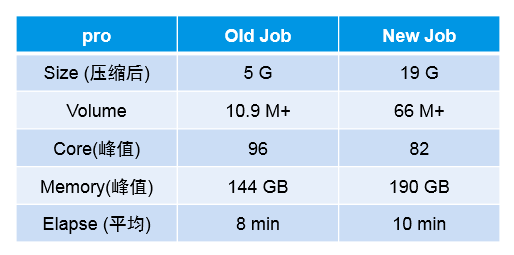
Elasticsearch为我们提供更多场景:动态写入ES索引多个不同的buckets;处理ES文档的元数据;从ES索引读取数据。
从hive导入Elasticsearch数据,我们一直是通过建映射表,跑MR任务写入。以前也尝试通过python导入,但是python无法很好控制线程,而且连接很不稳定, 导致后来弃用。 现在,Spark可以实现直接与Elasticsearch交互,无需做映射表,而且很方便调整线程数量。
Spark连接Elasticsearch,写入和读取:
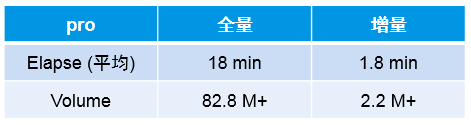
下面是全量和增量的对比:
相比sqoop,spark可以更灵活的控制逻辑转化,还提供定制化;相比MR来说,spark代码更简洁。
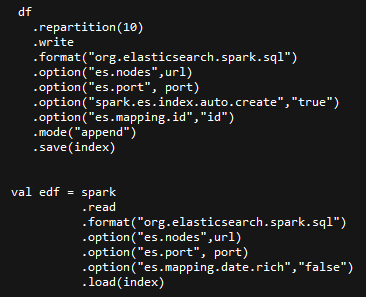
Sparkt通过JDBC连接RDBMS:
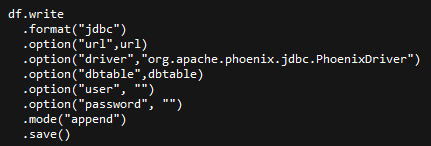
Apache Phoenix是构建在HBase上的一个SQL层,能让我们用标准的JDBC APIs而不是HBase客户端APIs来创建表,插入数据和对HBase数据进行查询。Phoenix-Spark1 APIs到了Phoenix-Spark2基本都被弃用,新的API也有不少问题,目前我们使用JDBC的接口与Phoenix交互。Spark直接操作Hbase相对会复杂些,配置较多,这里就此略过。
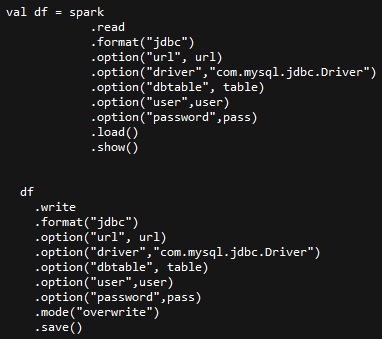
Spark1通过Phoenix API写入:

Spark2通过JDBC写入:
MapReduce迁移Spark
目前基本的数据仓库任务有成百上千的作业和脚本,如果手动迁移,时间和人工将是很大的开销。所以,用Spark SQL取代Hive SQL,尽可能保留脚本不改变,表结构不改变,表和作业之间的依赖关系不改变,会大大减少迁移的时间。
我们尝试用Spark平滑切换hive:
- 封装spark-hive utility jar包
- 部署spark接入hive源数据
- 利用hive作业脚本, 建立spark作业脚本
- 执行任务的Job step, 切换spark作业脚本
Spark SQL是Apache Spark最广泛使用的一个组件,虽然提供了非常友好的接口处理结构化的数据, 但我们在实践当中仍然遇到一些技术挑战:
- Spark有个概念叫shuffle partition数,来自参数spark.sql.shuffle.partition,它类似MR作业每个reduce阶段的任务数量,它也决定了最终生成文件的数量。这个参数的默认值是200,这样即使是很小的任务,最终也会生成200个文件。其次,这个参数不会像MR根据数据块的大小或者数据行数自动设置合适的shuffle partition数,当数据量很大或者数据发生偏移的时候,Spark SQL作业很难以最佳的性能运行,而且长时间占用资源,导致集群整体利用率下降。这个挑战需要我们思考如何获取数据量信息并自动设置shuffle partition数。
- 在部分HSQL脚本中会有用户自定义的参数设置,这些参数设置在Spark SQL中运行是无效的,而且Spark的自定义参数设置主要是放在命令行。目前所有的参数在Spark SQL运行中无效,所以我们也需要考虑把某些参数转换成Spark的参数,并从脚本运行时执行。