
背景
以前有文章介绍过明镜系统,一个基于复杂网络的反欺诈系统,我们在持续开发明镜后续功能的时候,发现了反欺诈业务的另外一些痛点
- 原有的明镜作为贷后调查系统,在业务上的价值相对较低,不能够在贷前发挥全自动拦截作用。
- 在调查过程中,根据人力调查情况发现和总结规律较为困难,经验丰富的反欺诈专员在总结和实现规则方面不一定是最专业的,让反欺诈专员花费大量时间在SQL编写和数据分析脚本编写上,显然是一种优质资源的浪费。
- 反欺诈规则上线困难,由于反欺诈规则有高时效性和易过期的特点,所以业务方希望反欺诈规则能够上线、下线迅速,流程简单。而传统的瀑布式研发流程显然不能满足这种需求。
- 上线后的变量和离线分析的变量结果不一致,导致线上线下变量差异大。由于线下分析通常是SQL的,而线上应用则是Java或者python的,很容易导致变量计算结果不统一,从而出现巨大的显著性差异。
基于以上这些业务需求,我们开发了新一代的明镜系统,流式明镜系统。除了明镜原有的功能,流式明镜还具有以下的优势
- 实时性。整个数据计算流程都是实时触发的,业务方可以在借款流程中的任意环节触发风控规则,不但能够做到贷前反欺诈,也可以应对虚假注册、恶意撞库等多种问题。具体来说,主要有以下三方面实时:
1)复杂网络实时更新实时图数据库:节点和关系都应该被实时识别出来,并落地到图数据库。
2) 实时变量:所有风控和反欺诈变量实时计算,按需计算,计算时间点可以由业务方配置。
3)实时决策: 可根据业务配置,实时触发决策,阻断任何高危流程。 - 可视化配置。为了能够降低规则上下线的成本,整个系统通过可视化界面配置的方式来实现变量。作为业务方,可以毫无技术背景,就能够通过我们提供的模板配置出线上反欺诈规则,配置完毕后立刻生效。现阶段我们提供公式型变量、复杂网络变量、时间变量、名单命中变量、地理位置变量等几种模板,能够满足用户70%的变量需求。
- 变量支持可回溯。拍拍贷的业务特色是用数据说话,所以在制定规则时需要数据支撑。传统的办法是变量上线后,积累一段时间的变量,然后再分析变量可行性。但这种方法有两个显著的问题,一个是周期过长,另外一个是发现变量效果不佳就是浪费研发资源。所以我们在可配置的基础上支持变量回溯(基于MR),方便用户在上线前通过历史数据观察规则或变量的有效性。
- 2和3两点的结合,给我们的系统带来了另外一个优势,就是离线数据和在线计算数据完全一致,不会出现线上、线下数据差异,可以大大减少开发资源浪费。
对于这样一个复杂的系统,单体应用显然已经不再合适,因此在架构上我们选择了基于事件驱动的软件架构,用消息队列解耦各个模块。我们引入了rabbitmq作为我们的消息中心,这是一个成熟且流行的消息系统。下图是我们整个系统的一个架构。
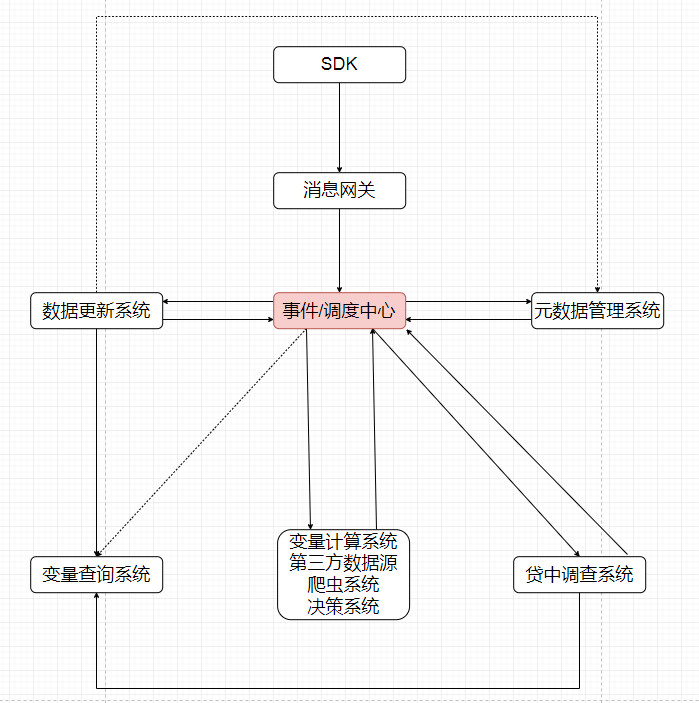

几个子模块的作用介绍
元数据管理
负责管理配置,包括定义事件,变量,节点,边,决策。以及他们之间的关系,比如一个事件是否触发创建节点,应该触发哪些变量计算。
网关
负责对外提供接受业务时间的接口,承担校验,解密,过滤,削峰填谷。并且将合法的业务事件写入消息队列等待后续处理。同时也承载着关系网络的解析。
调度模块
监听有效业务事件的消息队列,根据配置生成计算请求,写入消息队列。调度模块不关心怎么计算变量,只关心变量和变量之间的依赖关系,调用顺序等,当某个变量依赖的变量不存在,调度模块来负责触发前置变量的计算。调度模块同时负责管理计算状态,监控计算结果,是否需要重试等。
计算模块
是我们的核心模块,也是负载压力最重的模块,通过把与计算无关的功能都剥离出去,计算模块本身是轻量的无状态的,所以可以轻松的通过横向扩展提升计算模块的算力。计算模块决定了我们支持什么样的变量计算,目前支持的计算能力有表达式计算,时间窗口计算,复杂网络关系计算等。决策的计算也是在这里。
读取和写入模块
就是负责读取和写入各种数据,他们存在的意义是将具体的底层存储方案与其他模块隔离开来,其他模块只需要访问他们的接口即可。比如图数据库,我们就经历过从titan到hugegraph的迁移,这个迁移对于其他模块来说完全就是透明的。从Titan迁移到hugegraph的主要原因是Titan的实时写入性能达不到我们的性能要求,所以更换为百度最近开源的hugegraph.
流式明镜是一个可配置的系统,所以首先要做的就是配置,配置由元数据管理模块负责,绝大部分配置项我们都做好了前端页面,下图是一个复杂网络变量的配置页面。
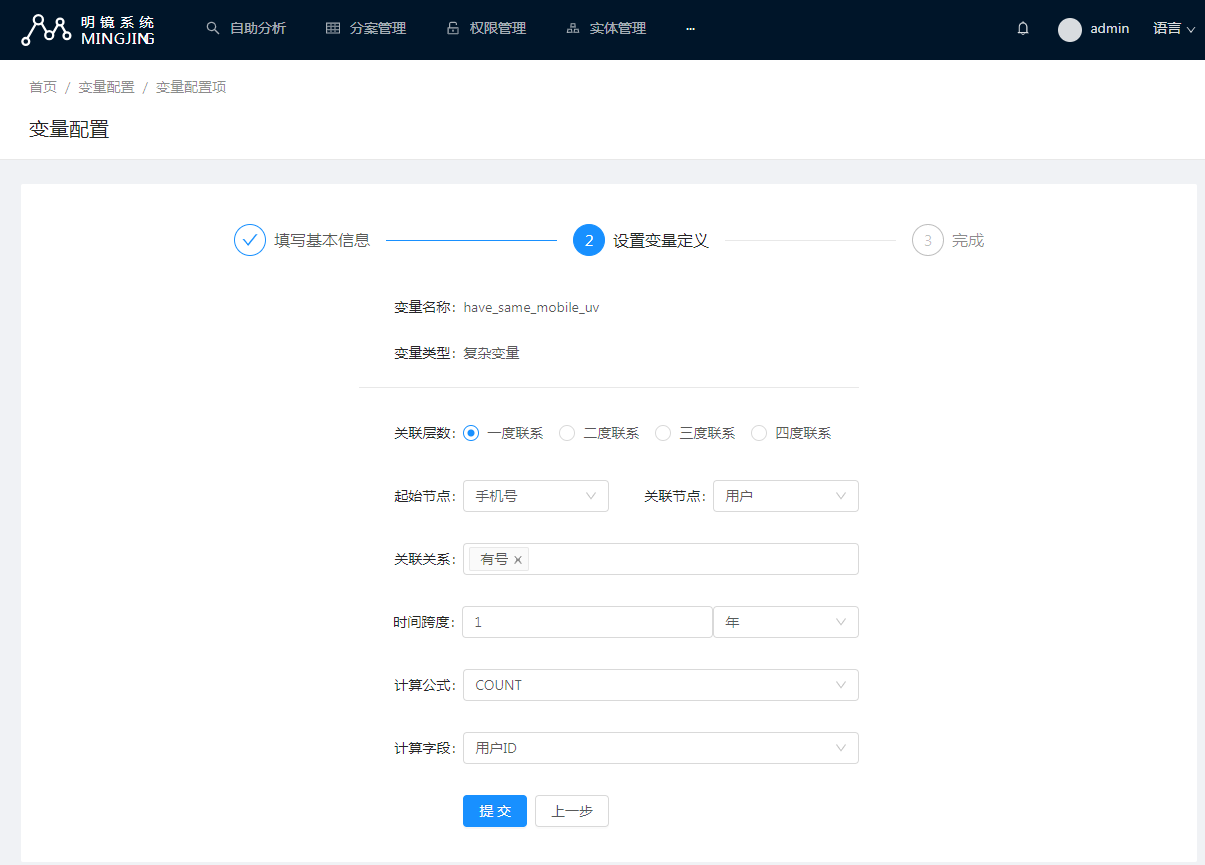
对于变量的配置,有一项重要的工作就是环检测。一个变量的计算,必然也要依赖另一个变量,依赖的起点是由事件带入的原始字段。所有变量的依赖图,应该是一个有向无环图。如果出现了环,就是导致我们在由事件生成变量计算队列时出现无限循环,因此必须保证变量配置不要出现环。
另外一个重要的点,其他模块的工作都依赖配置,所以配置完成后需要及时的通知其他模块更新。通过消息队列我们可以很方便的做到这一点
- 用户修改配置
- 配置服务发送配置更新事件到消息队列
- 其他服务监听消息队列发现有更新
- 服务访问元数据服务获取新的配置
配置完成以后我们系统就可以工作了,网关是我们系统对外的接口,提供了接收业务事件的接口,当一个业务事件达到网关,会经过解密,校验,解析生成节点,关系,并马上将其持久化,我们会持久化每一个事件,这是为了回溯和离线调度时使用。
随后事件将由调度系统接收,调度系统负责触发变量计算,即组装好变量计算请求并放入变量计算的队列,调度系统还要负责失败重试等功能,这里不做详述。
变量计算系统的工作内容很简单,就是计算变量,并将结果放入写入请求队列。这么设计的原因一来职责明确,使整个系统更易于理解,二来易于横向扩展,作为整个系统最繁忙的模块,变量计算系统是最容易成为性能瓶颈的,这样的设计可以让我们简单的通过加实例来提升运算能力,没有心理压力。
变量计算系统的实现,是一个策略模式的运用,我们定义了一个基类算子,通过继承实现了不同类型变量的计算方法,在程序的主逻辑不变的情况下替换不同的子类实现不同类型的变量计算。
变量计算的主逻辑如下:
- 准备入参
- 开始计算
- 计算结果写入缓存
- 插入计算完成队列以通知调度系统计算完成
- 插入写入队列以通知写入系统写入结果
对于不同的变量类型,准备入参的过程,和计算过程各有各的不同。这里详细说下我们支持的Aviator表达式变量和复杂网络变量。
在我们立项初期,第一个任务就是选择一个合适的表达式引擎,这样才可以对表达式动态求值。java下可用的表达式引擎很多,对我们来说,轻量小巧,易上手,支持自定义函数,功能够用同时又性能良好的Aviator是各很不错的选择。
支持自定义函数是一个很重要的特性,比如我们要实现gps比较,日期转换等功能,都可以实现自定义函数,这样用户就可以通过配置使用了。
表达式类型的变量的计算就是一个表达式求值的过程,很简单,而复杂网络变量就不一样了,就像上面关于复杂网络变量的截图,在准备入参的过程中,需要通过配置的起始节点,关系节点,关系类型,时间跨度和关联层数,通过复杂网络查询找到关系网中所有的节点,然后提取出需要计算的字段。
然后根据配置的计算公式,目前支持min/max/sum/avg/count/countDistinct,计算出对应的结果。
对于系统的介绍已经写了很多了,还有很多细节就不展开了。
我们选择了docker swarm作为集群环境,虽然现在k8s更流行,但是swarm对于我们来说够用了。
选择了spring-cloud作为我们的微服务框架。消息系统我们选择rabbitmq,缓存系统选择了Redis,elasticsearch作为事件存储,hugegraph作为图数据存储,Hbase作为变量存储。正是有了这些成熟的开源框架,让我们的开发事半功倍。
流式明镜的开发,对我们来说是一个跨度比较大的尝试,整个过程并不顺利,在这个过程中团队不断的学习和成长,收获很大,期望未来我们能做的更好。