
导语
传统的风控模型往往仅采用用户个人维度的多种变量,几乎不评估关联关系对风险的影响。使得逾期用户比较容易通过信息的伪装、更替和仿冒来绕过信用审核,成功借款,在早期极难被发觉。同时,还容易潜伏着一个隐患——团伙作案,其特点在于有组织规划地施行欺诈,几乎同一时间段爆发,破坏力大,所涉范围广泛,且往往数额巨大。
随着大数据时代的到来,基于关联关系的知识图谱慢慢走入了大家的视野,它突破了现有关系型数据库的限制,释放出巨大的数据挖掘潜力。本文就将主要介绍一下,我们如何利用复杂异构网络,对庞大的关联图谱进行挖掘和解析,在金融场景中进行实际的拓展与应用。
在现实生活中,人与人之间往往具有着复杂且多样的关联关系。而宏观环境下,更多的时候我们是通过他们在客观世界中的某种交互,发现两人的关联关系的,比如,两人微博互相关注、共用同一台电子设备等。如果将所有的人抽象成一个端点,而连接的媒介成为节点(如电话号码、imei等),那么端点与端点、端点与节点、节点与节点之间的关系便抽象为一条边,而所有的端点、节点和边则构成了一整幅关联图谱,也就是我们常说的社交网络。

这种图谱是相互连接用户及其关系的一种结构化表达,是最接近真实世界的数据组织结构。通过关联图谱,我们可以将所有的数据连接起来,即时地传达信息,易于揭示复杂的关系模式。然而它却难以直接分析,进行应用。通常,我们关注的是端点的属性(比如用户是否逾期),但一个端点与多个节点关联(一个人可以有多个手机号,使用多个imei登录等),每一种关联都带来不同程度的影响,而一个节点又与多个端点相连(一个imei同时被多人登录),从而富含多元而复杂的信息。

如上图所示,这是一个指数级膨胀并多元传播的信息链。在实际应用中,面对亿万级别的数据、几十种关联关系和非结构化的数据形式,一般就意味着分析非常依赖人工,工程计算量庞大且信息利用率低下。
基于上述的问题,我们采用了复杂异构网络,用高度定制化的结构将不同来源的非结构化数据进行融合,与用户的个人维度信息相互补充,以用户逾期为target,完成了端到端的训练过程。其具体结构如下图:
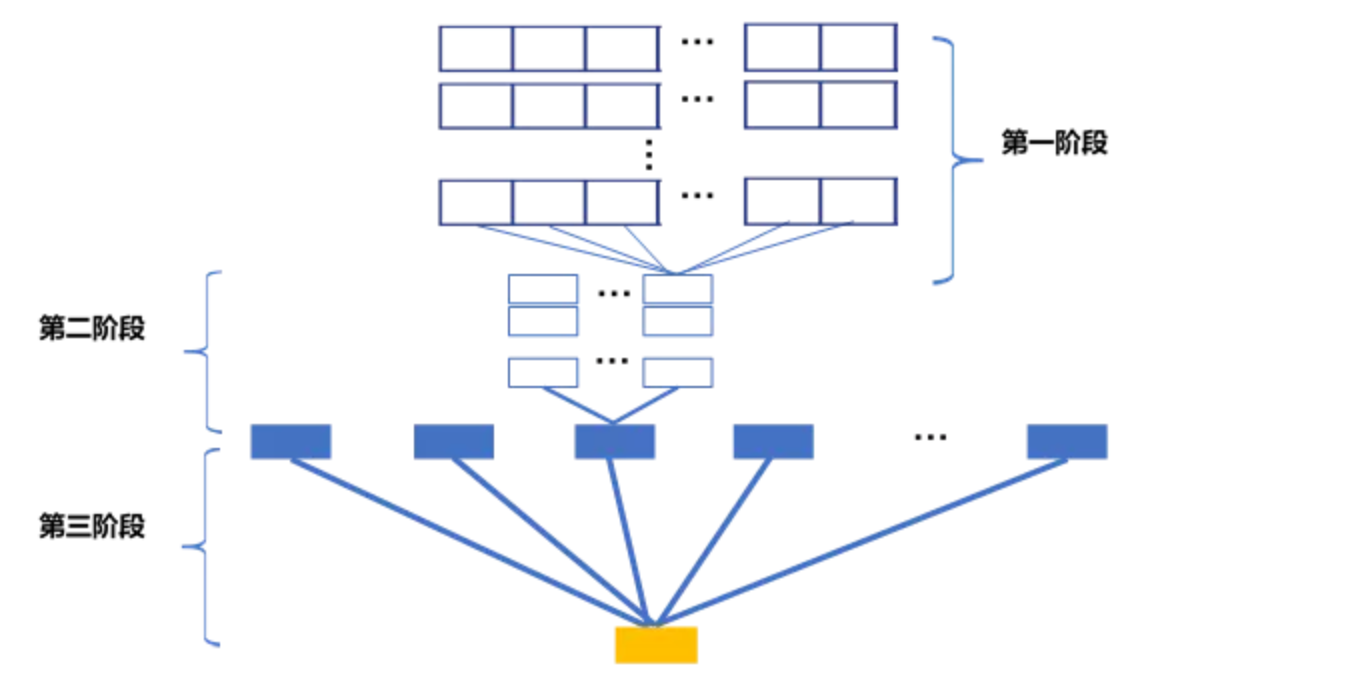
在第一阶段网络中,我们收集节点维度的可用信息和专家变量,通过多层神经网络(以下我们称为子网络A),将每个节点上的信息压缩为一个或少量几个值。对于同一个用户,不同种类的节点信息通过不同的子网络A,而相同种类的多个节点通过相同的子网络A。这样,我们就实现了动态可缩放输入,可以输入的信息模式多样。
在第二阶段中,我们将每种关系子网络得出的多个值,分别结合其与该用户的亲密程度,通过多层神经网络(以下我们称为子网络B),聚合为该种关系对用户的逾期影响。
最后,我们将不同关联关系所得进行并联,通过第三阶段的多层神经网络(以下我们称为子网络C),得到该用户的逾期概率。
整个网络可完全自定义,适应多种场景,端到端的训练模式最大程度上保留了信息的完整性,避免了过多人为主观的影响。
现有的网络结构虽然极大的提高了信息的利用率,实现了自动化训练。但在实际应用过程当中,面对百万级用户和亿万级的关系数据,其庞大而复杂的特点,使我们不得不面对内存和计算多重压力。如何在线上快速完成对多个用户的打分,成了我们下一步要考虑的主要问题。
由于在应用场景中,我们一般已经保有了庞大的关联图谱,需求是对新入用户进行预测。因此,异构网络的结构特性使得我们在完成训练之后,可以将第一阶段网络拆分出来,进行线下的计算:
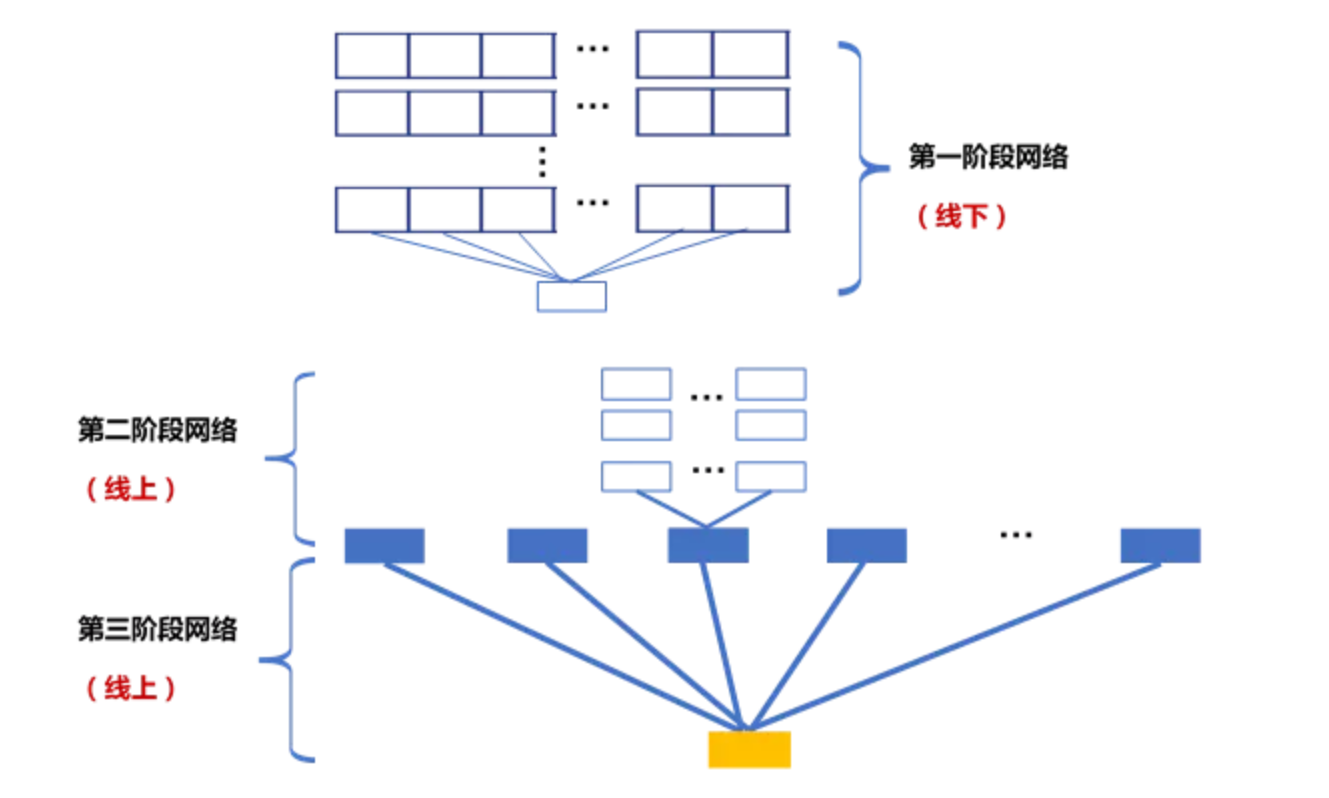
在线下,我们可以建立并维护一个节点库,将每个节点所连接到的信息通过子网络A进行压缩和打分。而在线上,我们仅将对于节点的所打分数传递给用户。对于我们要预测的新用户,只需要进行关联关系的检索和匹配,将匹配到的节点所得分数直接代入计算,通过子网络B和C,就可以得到该用户的逾期预测分数。这样极大地俭省了计算和线上内存,实现了线上多个用户并发,在更好的查找逾期用户的同时,无须担心延误线上申请流程,影响用户体验。
感谢在每一环节给予过帮助和支持的小伙伴,谢谢大家。