
本文简单介绍了一些社区发现算法,希望各位读者能够对于关系网络的人群切分有一些初步的了解。
首先我们解释一下什么是社区发现。举个简单的例子,一个班级中有些同学喜欢数学,有些同学喜欢文学,我们现在想把所有的同学分成有限个团体,有相同爱好的同学会相处得很融洽,并且很容易碰撞出火花。很自然的,分完之后就会出现一个新的问题,如何界定你的分法到底是好还是不好呢,等着慢慢看同学们的表现可能显得有些延迟与消极了。
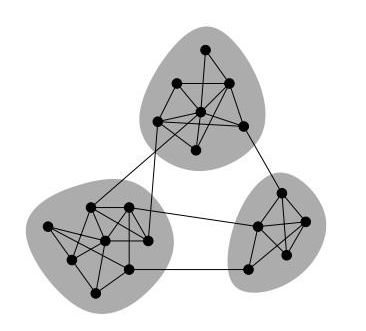

在上个世纪60年代,Herbert Simon 首先提出了复杂系统具有模块结构特性的概念,而针对社区的研究实际上是从子图分割问题演化而来,Kernighan-Lin 提出的二分算法使得子图分割问题逐渐成为当时图挖掘领域关注的重点。
简单解释一下模块度:Modularity是指网络中连接社区结构内部顶点的边所占的比例与另外一个随机网络中连接社区结构内部顶点的边所占比例的期望值相减所得到的差值
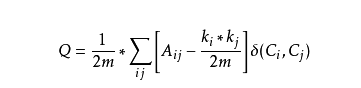
有了模块度这个度量标准,我们很自然就可以开始切割网络了,随便怎么切,反正一定能切出一个Q最高的情况:)。当然数学家们比较专业一点,Kernighan-Lin算法使用了贪婪算法,具体策略是,将社区结构中的结点移动到其他的社区结构中或者交换不同社区结构中的结点。从初始解开始搜索,直到从当前的解出发找不到更优的候选解,然后停止。但是这种方法必须事先指定两个字图的大小,所以很快被淘汰。
在这之后,又出现了一个算法叫谱二分算法。这个算法说起来比较简单,算一个Laplace矩阵的特征向量就搞定了,所有正元素对应的节点归一类,负元素对应的节点归另一类。而这个Laplace矩阵也不复杂,对邻接矩阵进行一些变换就行了(邻接矩阵就是对应图节点,有连接是1,没连接是0的矩阵)。但是同样这个算法有些小毛病,他一次只能划分两个社区,对于多社区的问题,不但效率会降低,准确度也会下降。
也许有人要问了,除了前面说的模块度,有没有其他比较新奇的变量可以用来描述网络的特征啊。这里再介绍一个边介数的概念,它比上面那个公式奇怪的Q好理解多了,它是网络中任意两个节点通过此边的最短路径的数目。那么什么又是最短路径呢?很直观的,图上的任意两点,你最少通过多少个中间节点可以把他们连起来。那么这个边介数又为什么比较重要呢,设想一下,河上有一座桥,桥两边的人如果要过河一定要走这座桥,所以这座桥的边介数很高,而它确实把河两岸的人分成了两个社区。
从边介数的概念出发,很自然的我们可以想到一个算法,我把所有边的边介数都算出来,然后去掉边介数最大的那条边,重新计算边介数,如此循环。这个就是有名的GN算法了,下图给了GN算法的一个应用实例。
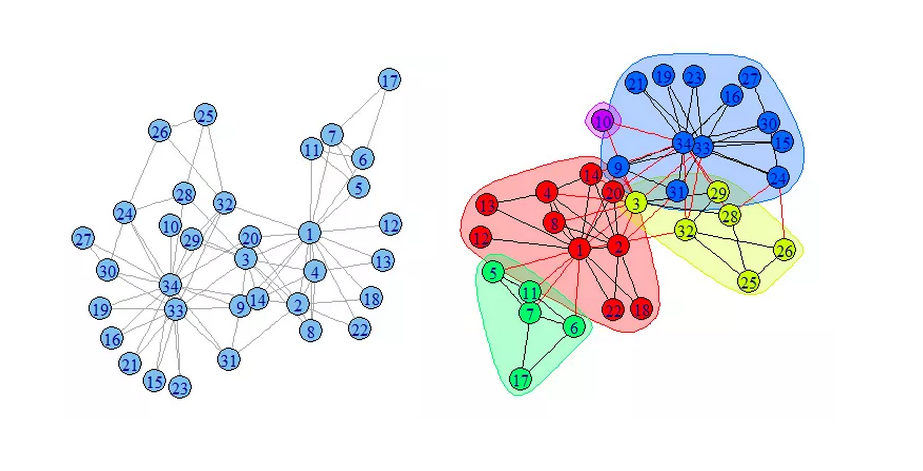
GN算法的计算复杂度实在是太高了,后来人们提出了一种改进的思路:首先将网络中的每个顶点设为一个单独社区,然后选出使得模块度Q的增值最大的社区对进行合并;如果网络中的顶点属于同一个社区,则停止合并过程。整个过程是自底向上的过程,且这个过程最终得到一个树图,即树的叶子节点表示网络中的顶点,树的每一层切分对应着网络的某个具体划分,从树图的所有层次划分中选择模块度值最大的划分作为网络的有效划分。

大家可能对于这个图比较眼熟,因为感觉好像和clustering聚类一模一样啊。。。但是它有个帅气的名字叫FastNewman算法,提一句,之前的GN算法是指Girvan和Newman两个人,不知道Girvan去哪了。
下面再简单介绍两个算法,说太多大家估计也懒得看。一个叫派系过滤算法,什么是派系呢,如果一群人,他们两两之间全部都有连接,那么他们就被称为一个派系。那这个要求就比较高了,N个人就需要有nC2条边。这个算法就是先找到图里面的各个派系,然后把这些派系当作新的点构成一个新的图,然后在这个新图上进行研究。
最后重点讲一个基于标签传播的LPA算法。最原始的LPA如下:
第一步: 为所有节点指定一个唯一的标签;
第二步: 逐轮刷新所有节点的标签,直到达到收敛要求为止。对于每一轮刷新,节点标签刷新的规则如下:
对于某一个节点,考察其所有邻居节点的标签,并进行统计,将出现个数最多的那个标签赋给当前节点。当个数最多的标签不唯一时,随机选一个。
这个我实在没有什么好多说的呀,就是邻居咋样我咋样啊。可能这些搞研究的人也发现这样太简单了,显示不出他们的水平,于是他们又进行了改进(就是让你看不懂)。这次算法的名字变成了SLPA。
SLPA 中引入了 Listener 和 Speaker 两个比较形象的概念,你可以这么来理解:在刷新节点标签的过程中,任意选取一个节点作为listener,则其所有邻居节点就是它的 speaker 了,speaker 通常不止一个,一大群 speaker 在七嘴八舌时,listener 到底该听谁的呢?这时我们就需要制定一个规则。
在 LPA 中,我们以出现次数最多的标签来做决断,其实这就是一种规则。只不过在 SLPA 框架里,规则的选取比较多罢了(可以由用户指定)。
我们可以这么理解,一个节点在不断刷新,因为他的邻居总是在变,所以导致它自己也跟着变,他们它本身变化的这个过程是不是可以构成一个序列呢,我们取整个序列中出现次数最多的分类当作最终结果就ok了。当然,这个是我的简化版本,真正的SLPA是一种重叠性的社区发现算法,比这要复杂多了。不过如果你要用,直接装软件包,SLPA 现在改名叫 GANXiS了。
吹牛到此为止,希望大家喜欢。