
传统金融机构很早就在使用基于线下数据的征信模型,并催生了一大批提供征信服务的第三方机构。在信用评级领域(主体和债项评级),美国有享誉世界的三大信用评级机构:标普、穆迪、惠誉,中国也有类似的中诚信、大公国际、中债资信等。而在信用评分领域(机构和个人征信),美国有三大征信局和FICO,中国则主要是中国人民银行征信中心。
随着互联网的发展,芝麻信用、百行征信等基于线上数据的新型征信机构开始出现,代表性的金融科技企业也在大力研发和使用自主设计的信用评级与评分系统。对于线上消费、支付、社交和交易等场景来说,为何要研发新的征信模型,这些新模型又具有哪些值得称道的新花样,其在金融科技企业的业务流程中又发挥出什么样的基础性作用呢?本文将就此展开介绍。
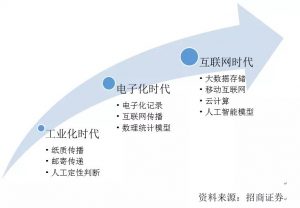

而近期随着数据存储和计算能力指数型增长,分布式云存储和大数据分析技术也高速发展,使得原本不宜获取和解析的数据具备了信息挖掘的可能,而传统征信模型实时处理这些数据的能力相对有限,正面临来自各方的挑战。以下归纳几点传统征信模型的薄弱点和网络大数据征信模型的创新特征:
其次,传统征信模型主要用于解决具有完整信用历史、高信用评分客户的信贷问题,而将大量缺少优质信贷记录的无信用评分客户和低信用评分客户排除在外。这就导致大量低收入群体和中小微企业信贷成本高昂,或者信贷额度偏低,而这一细分市场是大多数网络小贷企业专注的领域,新的网络征信模型也就此细分领域逐渐发展出一整套新型的高效能数据挖掘方法。
其次,传统信用评估模型为了保证统计模型采集和分析的数据维度相对结构化和低维度,一般只涉及二三十个变量,缺少大量非结构化和稳定性差的线上多维度复杂数据。这一方面保证了传统征信模型的结果稳定性,但另一方面也导致没法对缺少相关标准化信贷记录的客户进行风险评估,而新的网络征信模型所使用的数据维度可以高达几千个,涵盖消费者各类可搜集的基本信息和行为数据,解决了数亿被排除在传统征信之外的网民的信用评估问题。
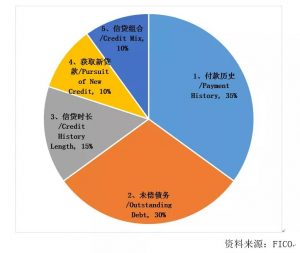
其次,传统征信模型一般仅作为传统金融机构发放贷款的参考因素,其在实践中还会大量使用专家经验进行人工审核和人工干预,以至于贷款发放与否很容易受到审核人员的主观因素干扰。这就限制了传统征信模型的应用范围,没法实现100%自动化审核和快速响应机制,因而成本和效率控制没有最优化,而新的网络征信模型往往实现了高度自动化,人力资本主要往技术开发领域集中。
其次,传统征信模型的开发机构一般都是高度规模化、体制化的成熟企业或事业单位,往往有一整套高度标准化的管理流程和较为强势的垄断地位,市场服务意识相对薄弱,所提供的产品和服务也就相对单一。这就难以充分满足各类互联网企业面临的多样化市场服务需求,也不利于实现高度定制化的专业风控支持,运行效率和客户体验相对较差,而新的网络征信模型开发机构一般都是基于各类线上场景的高科技网络化企业,直面客户的生活痛点,生态营造、商业整合和技术升级能力更强。

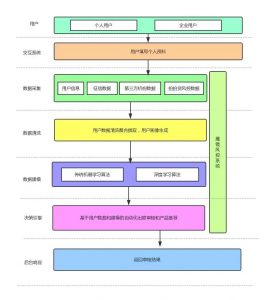

同时,网络征信也促使传统金融机构认识到科技创新和海量数据的价值,原本看似与信用不相关的数据原来也能挖掘出与传统借贷记录数据类似的效果。它也打破了传统征信机构的垄断地位,让传统的征信体系产生了危机意识,从而提升市场服务意识,并开始尝试引入金融科技企业开发的新模型新算法。
综合来看,网络征信模型在传统的征信模型基础之上进行了较大的创新,能够处理复杂结构的海量数据,并引入了新型的深度学习算法和复杂网络、神经网络分析技术,颠覆了传统的基于小样本、低频次历史数据进行统计分析的信用评估理念,能够基于各类线上场景开发出定制化的个性模型。它能够在网络小贷的各个环节中发挥作用,改进了金融科技企业的客户管理、资金管理和模型迭代流程,大幅度提升了互联网金融的经营效率和客户体验。