
日常生活中,我们往往在社交,媒体,新闻等各种平台上收到各种各样不同的营销信息。有卖面膜的,有推销假冒球鞋的,也有些海淘代购的,其中不乏一些灰色产业乃至黑色产业的个人或机构。而在拍拍贷的风控等业务场景下,尤为重要的任务是,如何在茫茫多的社交文本中,排除正常的日常交流,挖掘出灰黑产的营销信息,以及进一步发现一些具有不良特征的中介机构、代办团伙。不同于社区发现算法,在具体的营销沟通文本中,我们更倾向于寻找的是一些黑产作案的实锤,从而可以达到快速拉黑和保全资金的目的。此时,这个任务就可以首先归为文本分类问题。请看下边的社交文本记录:

作为NLP领域最为经典的场景之一,文本分类已经是很成熟的技术,并积累了从简单方法到复杂模型的许多实现方式。本文将分成3种主流的方法来展开。
- 基于规则的系统
- 基于简单模型的系统
- 基于深度模型的系统
在进入具体的文本分类方法之前,还是先用很小的篇幅来说一下文本的预处理。相信做过实际NLP任务的同学,一定了解文本预处理的重要性。在将文本丢进后面分类系统前,有许多事情要做。就拿从社交网站上爬取的一些留言来举例。预处理就涉及到:数据清洗,统一文本的编码、全角半角格式,去除文本中的一些特殊符号、表情、异体字等等;再到一些数据处理,例如中文的分词,一些特定词组的替换(比如在营销信息中往往会提及到的一些短网址,微信号,qq号),以及西文的统一大小写、词干提取等操作。充分的预处理,往往会对后面分类模型效果的提升起到事半功倍的效果。
基于规则的文本分类系统,是基于一系列的手工语言规则来实现的。这种方法往往需要对于目标类别的文本特征有着比较清晰的理解。通过对词典和规则的积累叠加,可以对识别的精度有比较好的提升。此外,这种方法不受数据集标签数量的影响,在数据集缺少标签的情况下,利用规则的方法可以快速的标记出一批较为准确的标签。在挖掘营销信息的过程中,利用“办理贷|借款”和“加|+微|v”等组合可以快速的将文本进行粗分类。
基于规则的方法虽然简洁快速,但是仍然有非常大的局限性。首先,规则的建立者需要对目标分类的领域有着比较深刻的理解。例如,“高炮”“黑白户”等专业词往往需要业务专家来进行添加。其二,规则系统需要大量且持续的人力和时间成本来建立并且维护它。为了应对不断变化的话术,往往需要不断地添加新的规则以避免系统效果的衰退。在有了大量的规则后,规则与规则之间的交叉影响也需要被重视。其三,规则系统往往有着不错的准确率,但是召回率往往难以尽如人意。例如在总结话术规则时,通常都有强烈的长尾效应,难以以很简洁优美的形式枚举全部的话术,此时就又回到了第二条的问题。
除了依靠手工的规则,在深度模型方法出来以前,也还有不少的机器学习算法实现了文本分类。当然,为了使文本适应于机器学习算法,就有一个文本表示的问题。也就是说,在机器学习训练一个分类模型之前,需要将一段段文本转化成为数值表示的向量。最为常见的方法是词袋(bag of words, BOW)的方法。所谓BOW,是忽略文本中的词序和语法、句法关系,将其仅仅看做是一个词的集合,或者说是词的一个组合,按照词频汇集成一个高维向量。有时为了提升效果,往往也还会和n-gram(n个连续的词)的方法相结合,从而从一定程度上考虑词序的影响。为了兼顾模型效果与性能,往往会取到2-gram或者3-gram。
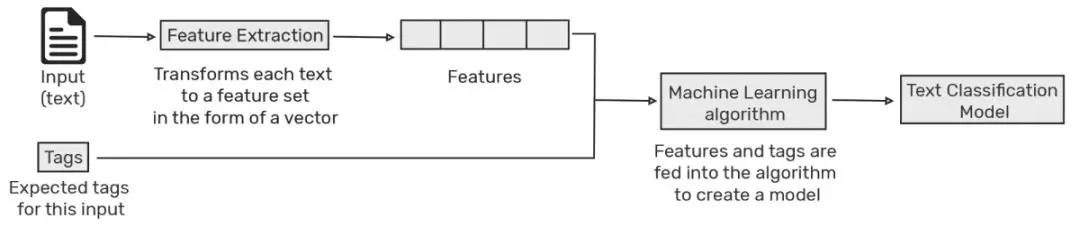
一旦我们有了文本的向量表达和标签,我们就可以选择合适的模型来拟合模型了。比较流行的方法有像朴素贝叶斯,SVM等等。在深度学习(DL)的方法流行之前,常利用TF-IDF(词频-逆文档频率)进行特征权重的计算,对需要处理的数据进行归一化处理,再将加权后的特征向量输入SVM模型中进行模型训练,往往能取得不错的效果。在SVM中核函数的选取上,如果数据量特别少可以选择线性核,如果数据量还可以,选择RBF(径向基函数)往往会有更好的效果。利用SVM建立文本分类模型,不需要特别大量的数据,即可给出不错的效果。即使在DL模型大行其道的今天,在有文本分类任务的时候,也可以选用SVM快速拟合一版简单模型作为benchmark与别的模型进行比较。
随着深度学习的发展,利用深度模型来做文本分类也有不短的历史了。从早期利用fasttext简单粗暴的进行分类,到Text-CNN,Text-RNN,LSTM一些精巧的设计,再到现在利用(google推出的)bert预训练的语言模型去做迁移学习。如果分类的类别相差比较大,粗暴的fasttext的学习速度快,效果还是不错的。但是,如果分类的类别较为细小且数据量较大的情况下,是可以祭出一些复杂模型的。
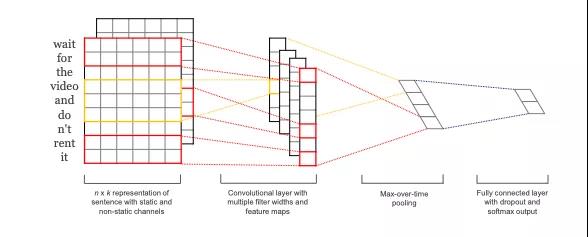
比较常见的有2014年Yoon Kim提出TextCNN。将卷积神经网络CNN应用到文本分类任务,利用多个不同size的kernel来提取句子中的关键信息(类似于多窗口大小的n-gram),从而能够更好地捕捉到局部相关性。以及2016年提出的“Attention-Based Bidirectional LSTM Networks for Relation Classification”(用于关系抽取的基于注意力机制的双向LSTM网络),它是来做Relation Classification(关系抽取)的,但是原理同样适合用来做文本分类。我们以营销信息为例,将模型学到的attention结果做一个可视化可以看出,attention模型学出了一些如微信,客服等营销相关的关键词。下图中越是高亮的词就代表了对营销的attention越大的权重。

最后,回到我们最初的目的,对营销文本进行分类。针对这一目标,我们尝试了多种模型,包括有TF-IDF特征+SVM分类,Text-CNN分类和基于attention的LSTM分类。简单的比较一下几个模型的效率以及性能。
| 模型 | 准确率 | 训练时间 |
| TF-IDF + SVM | 97.62% | 20min(CPU) |
| Text-CNN | 98.53% | 30min(P40 单卡) |
| ATT-LSTM | 98.85% | 210min(P40 单卡) |
可以看到,在比较明显的分类问题上,简单模型与复制模型的准确率相差不大,但是训练时间却大幅减小。至于生产上线,则既要满足准确率的要求,也要符合实际推断的算力资源,其中的利弊权衡需要按照实际情况的去判断。在生产使用中,实际往往还会使用模型+规则的复合系统来完成一部分文本分类任务。并且,在模型给出的结果上,还可以利用规则去对一些模型难以判断的文本进行微调和兜底,使得整个文本分类的系统更加精准和鲁棒。
在实际的生产生活中,文本分类有着十分广大的应用场景。除了本文描述的案例,营销信息的识别以外,情感分类,意图识别,话题识别等等都是文本分类十分经典的应用场景。文章讲了一些基础的文本分类的方法,应用中往往需要结合各种方式与技巧。欢迎大家讨论。