


该智能化调用策略是实现了数据接口的异步调用,不需要调用完所有数据之后才能进行预测生产,针对异常接口,同时可以智能识别,选择更合适的数据模型进行预测。该技术的实现具体分两步:
由于不同接口提供的不同数据源在数据模型中的重要性不尽相同,重要性越高的数据,越能够保证数据模型预测的效果和稳定性,所以理论来说应该优先调用高重要性的数据源。但是除了重要性,数据成本也是生产实际中的重要考虑因素,往往越重要的数据源也越贵,需要进行权衡。除了特征重要性,数据源价格,还需要考虑很多因素,例如,数据源的缺失比率,数据接口历史稳定性,数据特征分布的方差。
本发明针对不同的角度,将不同数据源进行比较打分,打分方式直接是该数据源在所有数据源中的顺序,并且除以总数据源数,这样得到一个0~1的小数,数值越小,表明在这个衡量标准下越重要。根据开发人员的实验证明,总得分 = 0.45特征重要性+0.18数据源价格+0.12数据源缺失比率+0.15数据接口历史稳定性+0.1数据特征方差。按照总得分从低到高按顺序调用外部数据源,能够尽可能得保证节省数据调用的时间和费用,同时也尽可能减少接口异常的影响。
在确定了外部数据源的调用关系后,训练多组模型,以保证数据源异步调用下的模型稳定性和效果,具体步骤如下:
1) 假设外部数据源共有N种,调用顺序为1->2->3->…->N。
2) 利用大量历史样本进行实证推导,每条样本信息包括N个数据源提供的特征信息以及该样本的逾期标签(0-1变量)。可以利用特征和标签进行机器学习建模,得到预测预测逾期概率的模型,用于后续样本的预测工作。
3) 根据调用顺序,训练基于不同数据源的逾期模型,例如仅仅基于数据源1的逾期模型和基于数据源1和2的逾期模型等等。为防止接口异常的出现,也需要训练剔除模型数据源的模型,例如接口2故障率较高,则需要训练基于数据源1和数据源3的模型,方便在数据接口2出现故障时,其他数据依然可以稳定高效得进行预测工作。
4) 根据上一步,我们得到在不同的阶段下的可选模型。然后根据这些模型在实证样本上进行预测打分,得到每个模型的逾期预测的概率分布。理论上来说,使用所有的数据源进行的逾期概率预测是最精确的,但是有时候部分的数据源,就已经可以标记出足够好/坏的样本了,也就是说如果一个样本在M个数据源下被预测出有99%的概率逾期,那么即使使用全部N个数据源,预测出它实际有100%或者98%的概率逾期,后续数据源的调用也没有特别大的意义,因为变动幅度太小了。但是如果M个数据源的逾期概率只有60%,那么后续的数据源可能会对该样本有更好的定义,后续数据源的调用就是必不可少的了。所以后面的步骤需要去确定,在每个步骤下,逾期概率满足什么条件时可以定义为足够好/坏的样本。
5) 利用动态规划的方法,在每个阶段实证分析逾期概率的筛选限制值,以保证在可接受的模型表现损失的情况下,如下图,在阶段K,将样本按照预测的逾期概率值从小到大排列,选出最小的前m%的样本认定为好样本,选出最大的前n%的样本认定为坏样本,好坏样本都不在进入下一轮数据调用,所以阶段k+1只使用阶段k的(1-m-n)的样本量。这里需要考虑两个部分,首先是好坏样本中错误率,其次是后续的计算成本,两个指标相互之间呈负相关关系,当m和n较小时,错误率较低但是流转到下一步的样本数量大引起成本增加。这里针对不同阶段的m和n,利用计算机在一定范围内进行了穷举操作,模拟了不同阶段不同取值下,样本的筛选过程,分别计算不同情况下,模型的整体表现(错误率),以及模型完成所有样本预测时的总成本。最终模拟得到每个阶段最优的m和n取值。
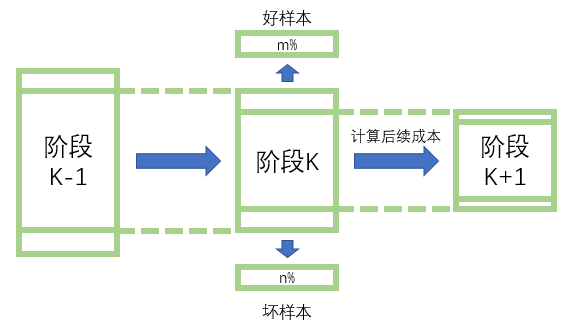
6) 在以后的生产环境中,m和n就是已经固定好的取值,只要正常按照流程进行分阶段预测即可,如果在阶段k,某样本满足了该阶段m或n的筛选条件,则直接跳出流程,给出一个极端好/坏样本的预测值。这种方式减少了数据调用量和时间,加快了预测工作。
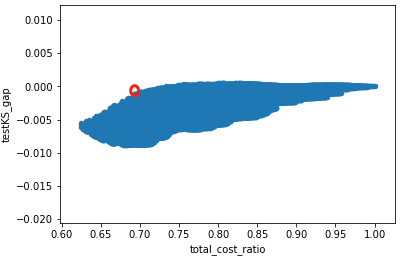
1. 在保证模型效果的同时极大节省成本:如下图是在穷举不同阶段不同m和n值时,模型表现和成本节省的关系分布,红圈位置是目前来说最优选择点。该图纵坐标为KS变化值(柯尔莫哥洛夫-斯米尔诺夫检验(Колмогоров-Смирнов检验)基于累计分布函数,用以检验两个经验分布是否不同或一个经验分布与另一个理想分布是否不同),横轴为该方案下成本与原版成本之间的比值。从红圈位置可以看到,在KS下降0.1%左右的情况下,成本可以节省30%。实际生产中KS下降1%都被认为是可以接受的模型变化。
2. 简易性:整个数据源调用技术,仅仅只需要在生产上线之间进行一次大规模的实证分析和测试,确定m和n之后,在以后的生产实践中不再需要更多的人为干预,就能正常运转。
3. 自动化:整套技术分析方法,都是可以利用编程技术固定在计算机上自动实现,即使后期出现新的外部数据源,亦或者是老数据源效果/价格的变化,依然可以用系统进行自动的迭代更新,保证了整体技术实现的统一性,不受人工误差的影响。