
大数据集群存储着各种不同类型的数据集,不同团队共享地在集群上面处理不同类型的计算任务。业务的不断增长和新的应用接入,每个数据集通过这些相同或不同的数据管道不断增长。数据的持续增长,一方面对集群的存储及扩容能力提出要求,进而导致数据存储成本的增加;另一方面数据文件的几何量级增长,存储数据元信息的单点NameNode成为集群性能的瓶颈,进而导致集群计算性能下降,也使得NameNode节点变成集群不稳定的潜在因素。
在集群磁盘资源紧张且仅能获得有限扩容补充的情况下,保证集群数据的增长可控与计算性能的快速稳定可靠,是大数据平台部门的一项重要课题。
随着集群数据的不断增长积累,对数据的访问频度也会呈现不同的巨大差异。通常情况下最近写入的数据访问频率会比很久之前的数据高很多,此时这些数据被认为是“热(HOT)”的。我们通过分析可以发现,随着时间的推移,初始写入时被认为是“热”的数据,访问频次会逐渐下降。当每周仅被访问几次时,就转变为“温(WARM)”数据。在此后的1~3个月里,当数据一次都未被访问,或频率降低到一个月几次或几个月一次时,它就被定义为“冷(COLD)”数据。最终,当数据一年之中极少用到,仅有一两次使用频率时,它的“温度”就是“冰冻(FROZEN)”的了。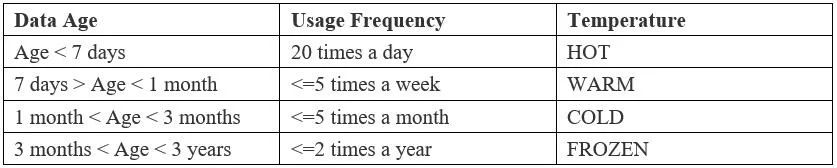

表1-冷热数据定义表
认识到数据的冷热与数据的年龄成反比,同时意识到的是,集群中的数据无论冷热,都采用了同样的存储策略,这对集群的存储资源和NameNode都是极大的浪费,那如何根据数据冷热程度对HDFS存储系统进行优化呢?
Ceph是一个开源的、弹性可扩展的、高可用的分布式存储系统。主要提供对象存储(Object Storage)、块存储(Block Storage)、文件系统(File System)三种存储服务。
Ceph存储集群中包含三种类型的角色节点:
1)OSDs:OSD守护进程的功能是存储数据,处理数据的复制、恢复、回填、再均衡,并通过检查其他OSD守护进程的心跳来向Monitors提供一些监控信息。
2)Monitors:维护展示集群状态的各种图表,包括监视器图、OSD图、归置组(PG)图、和CRUSH图。
3)MDSs:元数据服务器(MDS)用来存储元数据,CephFS要求集群内至少有一个MDS。MDS使得用户在不对Ceph存储集群造成负担的前提下,执行诸如ls、find 等基本命令。
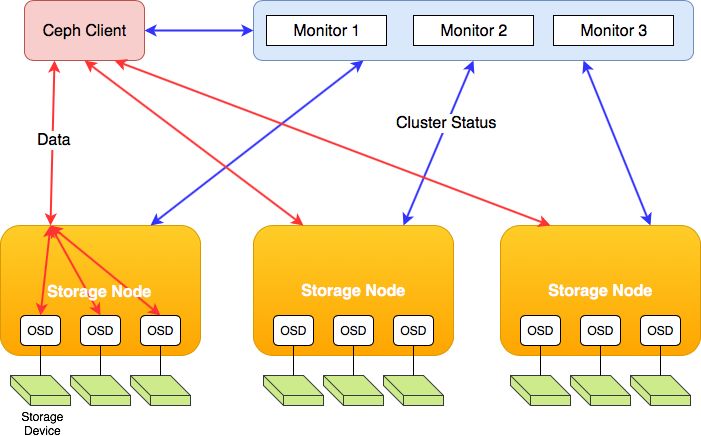
图1-Ceph角色架构
Ceph把客户端数据保存为存储池内的对象。通过使用CRUSH算法,Ceph可以计算出哪个归置组(PG)应该持有指定的对象(Object),然后进一步计算出哪个OSD 守护进程持有该归置组。CRUSH算法使得Ceph存储集群能够动态地伸缩、再均衡和修复。
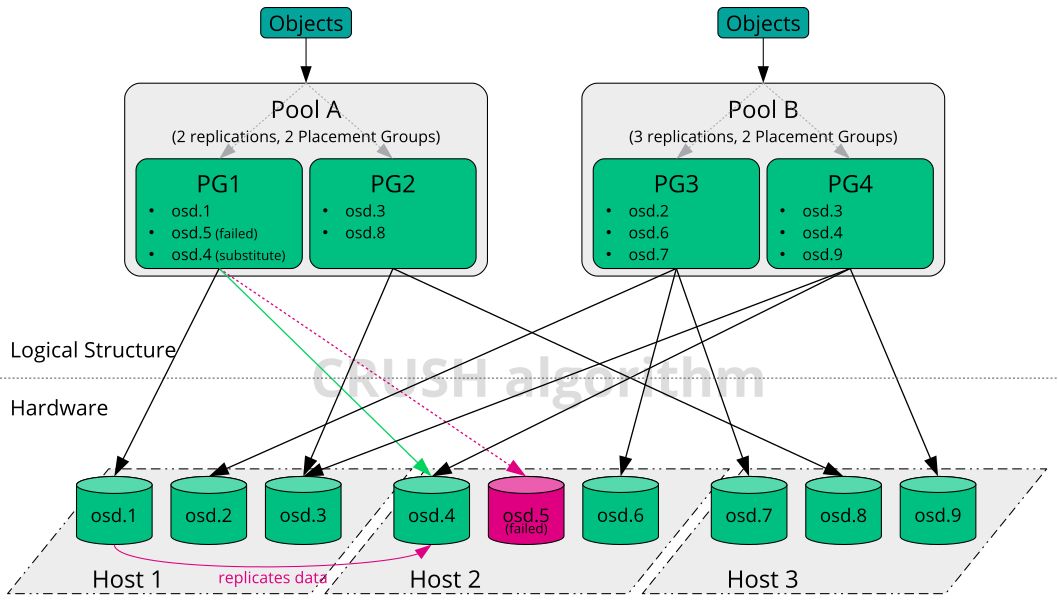
图2-Ceph数据存储过程
成也萧何败也萧何之去中心化
在谈论Ceph的优点时,去中心化设计是注定会被提及的。一是摒弃集中式存储,采用CRUSH算法,数据分布均衡,并行度更高,二是去中心化使得集群逻辑上可以无限扩展,不存在单点资源限制及单点故障。
1)并不美好的无限扩容
Ceph确实有无限扩容的能力,但需要良好的初始规划。中心化造就了扩容的上限是单台master结点的物理极限,去中心化造就了无限扩容的理论基础,但实际扩容过程也并不完美,服务质量会受严重制约。原因在于:Ceph在扩容时,去中心化使得容纳数据的PG的位置会根据crushmap的变化而调整,这个调整会导致Ceph受到“容错域”制约,部分情况下PG将无法对外提供正常读写服务。而对比中心化元数据的HDFS,在扩容时几乎无限制,你可以撒欢地扩容。此时中心化元数据在扩容与重平衡时,反而变成了一个优点。
2)并不便宜的存储成本
集群可靠利用率,即整个集群在容量达到一定阈值时无法对外服务,或者说无法保持高可用的服务。去中心化使得对象元数据“伪随机”地分配到各台物理机磁盘上,伪随机不能保证所有磁盘的完全均匀分配,总有一些磁盘的使用率会高出均值。而Ceph没法保证新的对象是否落在空盘而不落在满盘,所以Ceph选择在有盘满了时,就拒绝服务。集群整体使用率不高时没有问题,而在使用率达到70%后,集群可能进入不稳定的状态,此时需要管理员介入对容量过高的磁盘做reweight,而为了防止更糟糕的情况发生,期间Ceph集群需要停止对外的写服务。从Ceph业界同行的反馈来看,大家基本上在Ceph集群达到50%使用率时,就要开始准备扩容工作,这也导致存储资源的极大浪费,集群的数据规模越大,空置效应也越大。对比HDFS,空间使用率在95%以下,存储也能很好地对外提供服务,最坏的情况也仅是跑在HDFS上的Hadoop Job,会因为没有磁盘空间中间结果无法落盘而挂掉。
Hadoop2.3开始支持HDFS分层存储。顾名思义,HDFS分层存储就是对hdfs不同路径下的不同温度数据制定不同的存储策略,本质是将数据存储在不同的存储介质中,也称为HDFS异构存储。
HDFS支持的存储介质(类型)
1)DISK-普通磁盘
2)SSD-固态硬盘
3)RAM_DISK-内存盘
4)ARCHIVE-归档/压缩(数据被压缩存储)
基于成本,对于一般Hadoop集群,接触或更多考虑的是DISK及ARCHIVE。
存储策略
存储策略允许不同的文件存储在不同的存储类型上,存储策略可配置,可以设置为全局,也可以设置到某个文件夹。
1)Lazy_persist:一个副本保存在内存RAM_DISK中,其余副本保存在磁盘中
2)ALL_SSD:所有副本都保存在SSD中
3)One_SSD:一个副本保存在SSD中,其余副本保存在DISK中
4)Hot:所有副本保存在DISK中,默认存储策略
5)Warm:一个副本保存在DISK上,其余副本保存在ARCHIVE上
6)Cold:所有副本都保存在ARCHIVE上
存储策略包含五个属性,不同策略及属性值参考下表:
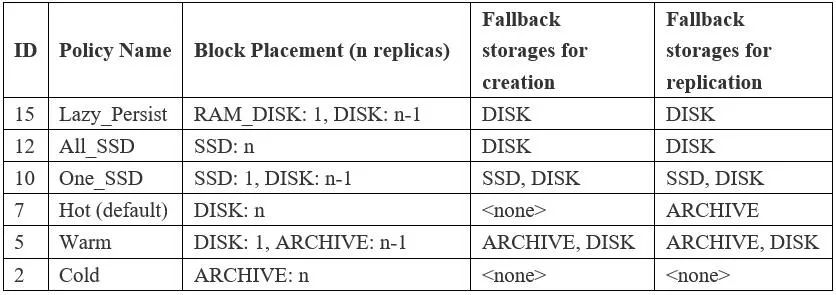
表2-HDFS存储策略属性表
HDFS提供了叫做MOVER的工具用于数据迁移归档,功能类似于Balancer。MOVER会定期扫描HDFS文件,检查文件的存放是否符合它自身的存储策略,如果数据块不符合指定策略,它会把数据移动到该去的地方。
HDFS异构存储的目的在于,根据数据冷热采取不同存储策略从而提升集群整体资源使用效率。对于访问频繁的热数据,将其保存在具有更高访问性能的存储介质上,提升其读写性能;对于极少访问的冷数据,以归档的形式保存,降低NameNode的内存压力,同时通过减少Replica数降低数据存储成本。但是,异构存储的配置需要用户对数据目录指定相应的策略,即用户需要预先知道每个目录下的文件的访问热度,而且数据的冷热也是在不断变化和增长的,这就需要经常对集群数据进行扫描统计,确认数据冷热程度从而不断调整数据存储策略,运维成本是很高的。另一方面,集群作为一个整体,不会考虑拆分部分节点作为ARCHIVE存储节点,且集群基于安全的数据策略,存储默认为3备份,归档存储仅是将数据目录文件压缩成har,缓解大量小文件对NameNode的内存消耗,但并不会减少磁盘存储资源开销。
HDFS的三备份策略提供了一种简单而健壮的冗余方式来最大化保证数据的可用性,对于较少访问的数据集,它们的第二个或者第三个副本会比较少访问,但是仍会消耗相同的存储空间(额外开销为200%)。Hadoop从3.0开始,引入纠删码(ErasureCoding简称EC)技术来代替多副本方式,它使用更少的存储却可以保证相同级别的数据容错。
纠删码与Reed-Solomon码
在存储系统中,纠删码技术主要是通过利用纠删码算法将原始的数据进行编码得到校验,并将数据和校验一并存储起来,以达到容错的目的。其基本思想是将k块原始的数据元素通过一定的编码计算,得到m块校验元素。对于这k+m块元素,当其中任意的m块元素出错(包括数据和校验出错),均可以通过对应的重构算法恢复出原来的k块数据。生成校验的过程被成为编码(encoding),恢复丢失数据块的过程被称为解码(decoding)。
Reed-Solomon(RS)码是存储系统较为常用的一种纠删码,它有两个参数k和m,记为RS(k,m)。如图3所示,k个数据块组成一个向量被乘上一个生成矩阵(Generator Matrix)GT从而得到一个码字(codeword)向量,该向量由k个数据块和m个校验块构成。如果一个数据块丢失,可以用(GT)-1乘以码字向量来恢复出丢失的数据块。RS(k,m)最多可容忍m个块(包括数据块和校验块)丢失。
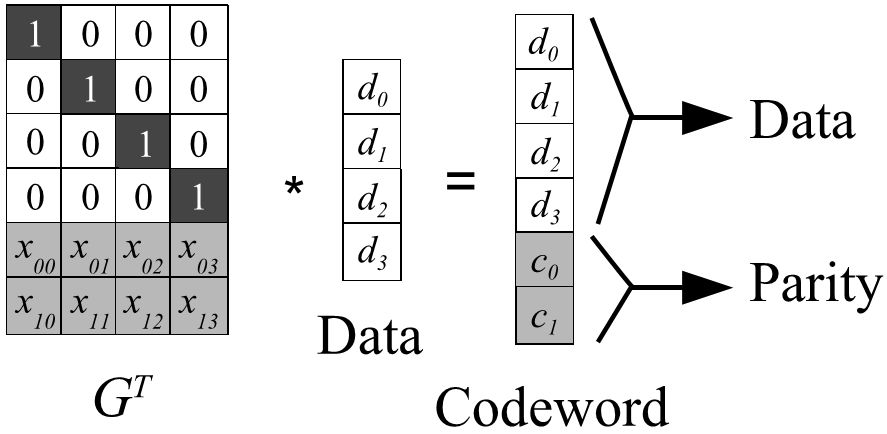
图3-RS(4,2)编码过程示意图
与多副本策略指标对比
与之前采用的HDFS副本策略相比,纠删码的优点是较高的存储利用率,缺点在于恢复时的资源开销较大且恢复所需时间较长。
表3-多副本及纠删码对比
Hadoop3.0纠删码项目进度
纠删码技术在Hadoop3.0中的实现,分两个阶段进行,如下:

其中Phase 1已经完成,主要实现功能包括用户可以读和写一个条形布局(Striping Layout)的文件;如果该文件的一个块丢失,后台能够检查出并恢复;如果在读的过程中发现数据丢失,能够立即解码出丢失的数据从而不影响读操作。Phase 2目前正在进行中,主要实现功能包括支持将一个多备份模式(HDFS原有模式)的文件转换成连续布局,以及从连续布局转换成多备份模式。以及支持将编解码器作为插件,用户可指定文件所使用的编解码器。
冷热数据分离存储的目标,可以总结为以下几个方面:
1)不降低数据可靠性容错性
2)可扩展,满足业务增长导致的海量数据存储需求
3)减少磁盘开销,有效利用集群资源,降低硬件采购成本
4)冷热数据平滑转换
5)减少数据目录、文件、块句柄,缓解NameNode内存压力,提高NameNode稳定性
6)稳定、可以驾驭,不增加团队的人力及运维成本
基于上面的技术分析及实现目标考量,并借着集群迁移升级重建的机会,我们最终选择了Hadoop3.0自带的纠删码技术作为冷热数据分离存储的最终方案,即相同集群环境下,热数据仍然以多备份策略存储,而冷数据则采用纠删码方式存储。

图4-启用纠删码及部分配置
将纠删码技术应用在HDFS冷热数据分离存储,可以保证在同等(或者更高)可靠性的前提下,将用于存储冷数据的资源利用率提高了一倍,即相同集群规模下可以存储原来两倍的冷数据,这不仅极大的缓解了集群的存储资源压力,而且有效减少部门在硬件方面的预算及开销。虽然在数据恢复阶段需要较大的资源和时间花销,但是对磁盘占比超过50%且极少访问的冷数据而言,这些消耗都是值得的可容忍的。