
一、应用背景
随着互联网公司业务多元化,复杂化,业务所依赖的服务逐渐进入分布式微服务时代,大大小小的微服务如雨后春笋般崛起,因此服务和服务之间的调用依赖则日趋复杂,而这些服务软件模块却分布在不同的机器,不同的数据中心,由不同团队,语言开发而成。因此,需要工具帮助理解,分析这些系统、定位问题,做到追踪每一个请求的完整http请求调用链路,收集性能数据,反馈到服务治理中,从而链路追踪系统应运而生。
二、业界方案
分布式服务跟踪的理论基础主要来自于 Google 的一篇论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》。例如,Zipkin, Dapper, HTrace, X-Trace等皆是分布式跟踪系统的具体实现,但是他们使用不兼容的API来实现各自的应用需求。尽管这些分布式追踪系统有着相似的API语法,但各种语言的开发人员依然很难将他们各自的系统(使用不同的语言和技术)和特定的分布式追踪系统进行整合,而OpenTracing 提供了一套平台无关、厂商无关的 API,所以在OpenTracing API 的规范下,不同的组织,开发人员就能够更加方便的添加或更换追踪系统的实现。受Dapper和Zipkin的启发,Jaeger正是诸多追踪系统下遵循OpenTracing 的一个开源实现。
三、Jaeger系统
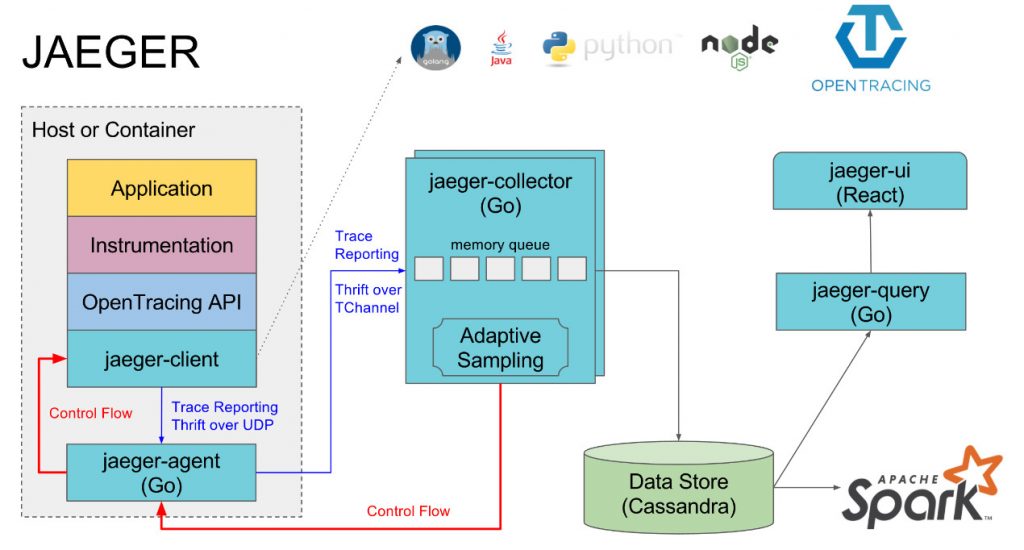

- jaeger-client
(OpenTracing API 各语言的实现,用于在应用中塞入信息采集点)
- jaeger-agent
(负责发送的进程,对 spans 进行处理并发送给 collector,监听 spans 的 UDP 发送。设计这层是为了作为基础组件部署到主机上,从 client 中抽象出了 collector 的发现和路由)
- jaeger-collector
(收集追踪 spans,并通过管道对追踪数据进行处理。当前的管道支持追踪的验证、索引、转换,最后存储数据)
- data store
(追踪信息的存储Cassandra)
- jaeger-query
(从存储中检索追踪信息并通过 UI 展示)
- jaeger-ui
(UI 展示层,基于 React)
经过测试发现,当采样率为100%,也就是上报服务产生所有请求的链路信息时,jaeger-UI的链路数据查询会有一定的延迟,而事实上很多时候确实想要实时捕获请求的所有状态信息,方便问题定位,于是做了这样的一个简单改造。
jaeger-client直接采集服务站点的链路数据,统一发送到Kafka消息队列,Kafka消费端go-server直接对数据进行消费,存储Cassandra。
UI的链路查询不变。Kafka的高吞吐,低延迟,可以横向拓展,golang语言天生适合并发任务的处理,而后端存储依然使用Cassandra集群,方便日后数据量增大,横向拓展。

以上是一条链路的记录信息,调用过程,以及调用耗时一览无余。
四、结束语
目前阶段,我们只提供Python和golang的链路client,下一阶段,在遵守OpenTracing API的标准下,我们将会开发支持Node,Java等其他语言直推Kafka的client。随着链路计算的复杂性,Kafka消费端也将引入Flink流式计算引擎,以此来提高整个系统整体的可用性,流畅性,以及实时性。