
语速模型的应用背景
语速,顾名思义,描述的是一个人的说话速度。量化的表示,就是一个人一分钟内说话的字数。一个人平均说话语速是100-200字每分钟,正常语速在每分钟150字左右。
在实际业务需求中,不同的场景下,对于语速的要求也各不相同。如:催收场景下,一般会采用较快的语速,从而体现出催收的压迫感;借出场景下,采用较为平和的语速,能达到较好的沟通效果。此外,在对于各个场景下的录音进行转写文本分析时,合适的语速能够有效地提高语音转写的准确率,进而提升文本分析的准确率。因此,基于语速选择合适的语音进行转写,能够在有限的语音转写时长下,获得更好的分析效果。
基于上述需求,获得一个能够衡量语速的指标,对于进一步改善相应场景业务,具有重要的意义。本文下面将介绍,基于神经网络训练语速模型,实现对于一段音频文件的语速评估。
语速模型预处理
1. 语速模型训练数据集
语速模型的训练主要基于Aishell-1公开数据集,该数据包含来自340个人共12万,采样率为16KHZ的中文普通话音频文件。且每个音频文件包含对应转写的中文文本。
2. 数据集预处理
Aishell-1数据集均为16KHZ的语音文件,我们话务系统采用的是8KHZ,为与实际语音想匹配,需要对于语音文件进行采样率调整,因此训练时,会将语音文件调整为8KHZ。
此外,由于语速的计算与说话时长密切相关,静音的影响对于语速模型的训练较为严重。因此,在训练前,基于语音活动检测(Voice Activity Detection, VAD)提取有效的语音段,能有效的提高语速评估的准确率。
语速建模
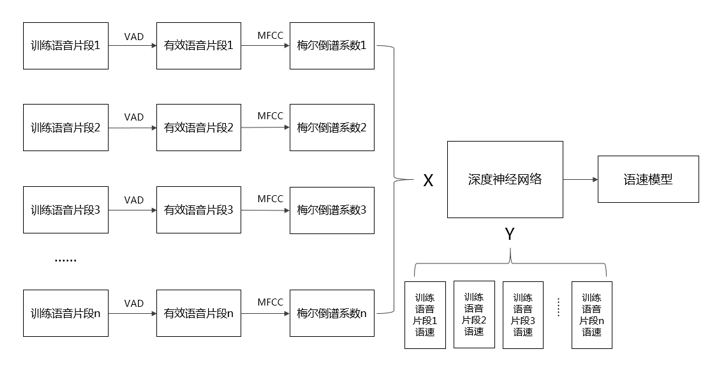

图1. 语速训练流程图
语速训练流程图如上所示,首先,会对于每段训练语音进行VAD处理,提取有效语音段。其次,对于有效语音段提取MFCC语音特征。最后,将MFCC特征作为输入,相应语音段的语速作为标签,训练神经网络,获得语速模型。
在进行训练时,模型的输入为语音的原始波形文件,且为任意长度,基于这种方式进行训练,能针对任意长度的语音获得相应的语速评估结果。语速模型的训练标签为基于语音时长及相应转写文本的字数计算获得的每秒包含的字数。
神经网络模型方面,本文采用8层Resnet,大小为32M,在基于CPU计算时,也能够保证较快的速度。
语速推断
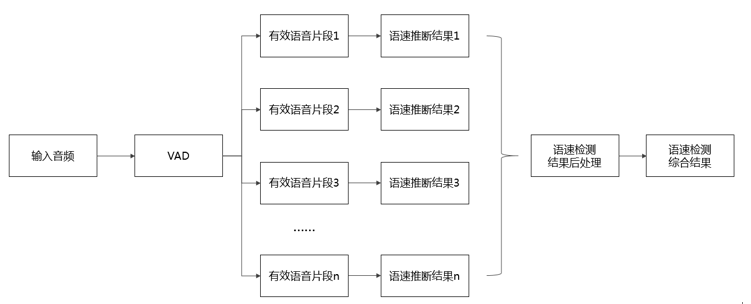
图2. 语速推断流程图
图2为语速推断流程图,流程如下:
1)获取待推断的音频文件。
2)将语音作为输入,经VAD处理,获得多个有效语音段。
3)对每个有效语音段推断,获得一个结果
4)对推断结果进行后处理,如:离群点检测等,去除与其余推断语速结果差异过大的语音段。
5)对剩余结果取平均,获得该语音段的语速估计。
该语速推断方法,能综合整段语音,获得一个比较综合的语速推断结果。此外,基于离群点检测,能够有效地去除语音段中的干扰,如:背景说话人语音的干扰。
本文训练的语速模型,在Aishell测试数据集,共7176段语音上进行测试,MSE为0.9,其中,仅44段模型预测结果与真实值误差超过0.5个字,占比0.61%。
总结
本文提出一种基于深度神经网络的语速检测方法。基于这一方法,能够实现从音频原始波形文件到语速的映射。该方法不依赖ASR转写的文本,能够方便的通过模型直接获得语速推断结果。相较于传统的基于语音能量包络统计音节个数的方法,本文的方法具有更好的抗噪声干扰能力,鲁棒性更强。最后,对于语速推断阶段的设计,能够综合整段语音,使获得的语速推断结果更加可靠。