
近日,智慧金融研究院科学顾问Joseph Milana博士发表了“风险信用模型的历史和展望”的专题演讲。
Milana博士是大数据风险决策领域的世界级领军人物。拥有超过20年的分析、建模、数据挖掘、机器学习的经验。早年作为核心建模成员,他开发了美国费埃哲(FICO)的Falcon反欺诈系统(目前在北美市场接近100%占有率)。


Milana博士拥有美国费埃哲12年履职经历,曾历任研发中心高级副总裁(领导了年销量超过1亿美元的反欺诈类产品线的研发和产品化);首席科学家(领导费埃哲研发部,推动基于数据模型进行决策管理的新兴领域创新,建立了费埃哲的核心知识产权库)等核心职位,并在信用风险、反欺诈、营销、数据传输等领域拥有超过20项核心技术专利。
智慧金融研究院特别全文刊载Milana博士演说内容以飨读者,以下是演讲原文。
我今天来讲信用风险建模的故事,如果没有信用风险建模的话我们就没有办法做借贷了。我们看美国过去的十五年借贷情况,最大的一块就是抵押贷款。另外,信用卡的份额已经达到了一万亿美金,这是有史以来的第一次。
信用风险已经回到了09年大萧条之前的水平,尤其是在美国发生的大萧条。那个时候的逾期贷款比例非常高,当然我们并没有风险建模,那个时候有很多风险评估原则都被大家放弃了,因此当时有大量的不良贷款产生,这就是我们说的逆向选择,这里面有一些固有原因。关于金融架构有很多书,比如说《大空头》(The Big Short),讲了大萧条背后的很多原因。幸运的是我们之后有了好的风险评估机制,不良贷款又回到可管控的水平。
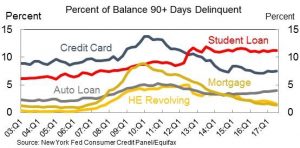
2009年美国各类贷款产品90天以上的违约率
讲到美国的信用风险以及其他国家的信用风险,我们必须要介绍一下FICO公司的历史。FICO在1956年创立的时候只是一个咨询公司,那个时候专门做运营研究,创始人之前在SRI工作。
在1958年,FICO发明了信用评分。在七十年代,美国国会推出了公平信用评分法案,法规要求进行贷款评估的时候必须确保信息是准确的;此外,如果贷款申请遭到拒绝,这个结果必须能被解释。
1974年,平等信用机会法案正式出台,法案要求信贷必须要根据能力评估,不能根据性别或者说种族来评估。1975年,FICO开发了第一个系统来预测现有客户的信用风险。基于他们现在的行为,比如说使用信用卡的行为习惯,对人的信用风险做出评估。
1987年FICO公司上市。他们想创建一种商业解决方案,利用神经网络或者说大脑的工作机制来帮助解决问题。1989年,FICO推出了自己的信用评分机制,现在这个机制已成为消费者贷款的通用评分机制。

再说跟FICO密切相关的HNC。1992年HNC推出了自己的“猎鹰”(Falcon)软件,通过对每笔交易进行评估来探测信用卡违约的可能。由于解决方案推广的很快,行业很快便普遍使用。
1995年,HNC上市,随后在1997年推出“PMAX”软件,通过交易触发机制来对每个信用卡账户进行信用评估。在此之前,FICO提供了一种月度监控机制的解决方案。在1997年的解决方案里,每次和客户接触时都会对客户进行信用风险评估。
2001年,myFico.com网站上线。这是一个面向消费者的网站,让每个用户了解自己的FICO分数是多少,提供了信用分数的透明性,帮助消费者很好地管理自己的信用分数。
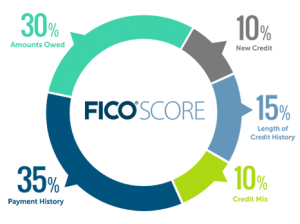
FICO 分数组成
2002年,FICO收购了HNC。2003年FACTA法案通过,强制让消费者可以了解信用部门提供的信用分数,有了更强的信用透明性,让消费者可以看到自己的信用评分。2009年,FICO改成了现在的名字。目前,全球有25亿信用卡受到了FICO评级的保护。
MyFico可以让消费者很好地了解模型里面讲的是什么,输入的是什么,信用分数是基于什么的,比如说基于信用历史。这里提供一个个性化的分数,评估本人的信用分数,让借款人有机会调整自己的行为,从而提高自己的分数,消费者就可以更好地评估风险。
透明性能够让消费者了解信用提供方是怎么样做决策,也影响了使用模型的类型。比如说七十年代通过的法案,不管什么时候想要做拒绝的决定,必须要做出解释才行。对FCRA法案来说,首先建立一个线性模型,通过这种线性模式解释如何做出一个负面信用决策。

还有一个法案叫做ECOA法案,不能使用某些信息,比如性别、种族以及宗教信息等等。这些因素不能植入模型里面,必须全部刨除出去,但可以使用邮局邮编信息,并将其他维度纳入模型。
下面很快解释一下负面评分决策,人们通常关注模型是如何运作的。一开始,FICO设立了一个非常清楚的方法,解释之前说的线性模型,里面有输入的变量,还有相关的概率值,所以必须要把这个函数和概率链接起来。
在建模的时候必须考虑到逻辑回归和概率的关系。一个人分数为什么不高,必须要看这里面变量是如何产生的,什么样的变量或者因素会贡献负的变量,或者说得分比较低的变量。
首先去掉这个尺度,因为这是一个线性的模型,但对神经网络是非常重要的,接着减去平均值,然后重新评估你的评分。分析哪个变量给线性模型贡献的变量最大,这里面可能有两个变量有相互关系,比如收入、成本两个变量,你就知道你的利润等于收入减成本;如果只看收入或者只看成本,评估结果可能非常不全面。
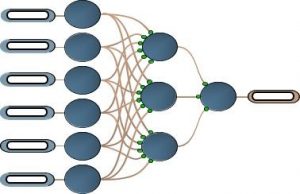
神经网络形成
解决方案就是你把有意义、可以解释的变量都放入子集里,根据子集的总量对总模型贡献来进行排序。要构建一个有意义的或者可解释的子集,这是一个关于线性模式的解释。
对于刚才的非线性模型,神经网络怎么做,方法就和线性模型不太一样。神经网络并不依赖于线性模型,隐藏节点也未必很多层,可以是单层的。在这里面输出模型,必须决定输入量是什么。
有两种方法来决定:第一种就是把每个子集的变量全部设置为平均值,如果所有都是平均值的话,新的量要怎么处理,要把新的变量和平均值进行比较,这样的子集会对总分产生一个非常大的变化,可以根据总分变化来排名,这是我们今天用得比较多的模型。
此外也可用单独的模型,一次可以删除一个子集,然后构建一个单独的模型,再根据单独的模型进行评分。接着再看子集里面哪个变量会产生对模型变量最大的贡献,然后对此进行分析。

我们之前讲了信用风险,最早是在保险方面用得最多。在七八十年代分析客户风险,你可以知道保险公司对此有许多应用,有一本书《醉汉走路》(The Drunkard’s Walk) 非常好地描述了风险应用。
再比如说电信网络方面,怎么样减少风险、评估风险,电信网络会不会有一些故障等。根据一些标签很少的数据集,我们用无监督的学习方法来评估里面的风险,当中必须构建比较好的模型。

我们现在也用人工智能去解决网络安全方面的问题,比如黑客攻击,必须要做一些渗透测试以及怎么从网络中提取信息,这些都是我们从事风险建模时可做非常多贡献的地方。
技术问题非常有意思,有时候数据没有做标签,你不知道网络是否被入侵了,我们要做平衡,有标签和无标签,有监督和无监督必须要平衡。
我们一直讲深度学习,有一个朋友领导了一个团队,他们在社交媒体上很有名,他们用深度学习机制来识别网上的视频、图像中隐含的色情、暴力内容。他们建立了这样一个数据库,数据库里面都是不健康的上传内容,利用数据库来对人工智能进行训练。