
随着业务的发展,拍拍贷风控系统中的模型调用链中的模型数量以及模型之间的依赖关系也出现了上升的趋势。如何解决模型之间的调用顺序,并优化整体调用时效成了拍拍贷风控系统中模型调度模块所面临的首要问题。
模型列表的图表达
如果把每个模型视为独立的节点,模型之间的依赖关系视为从一个节点指向另外一个节点的边,那么某个业务线所调用的所有模型就组成了一个有向图。特殊的,如果从这个图中任意一个节点沿着边向前出发都无法回到起点,那么这个图也被称为有向无环图(DAG, directed acyclic graph)。给定一个有向图,如果从i到j有边,则认为模型 j依赖于模型i。如果i到j有路径( 可达 ),则称模型j间接依赖于模型i。另外,我们称指向某个节点的边的个数为该节点的入度,一个节点的入度可以视为该节点所依赖的模型的个数;同时,由该节点指向其他节点边的个数为该节点的出度,某个节点的出度可以视为依赖该节点的模型的个数。


图1 一个有向无环图的示例
对于一个由多个模型组成的有向图,我们往往需要:
- 判断图中是否有环(即是否存在从一个节点出发又回到该节点的路径)
- 如何对有向图进行分层,使得层中的模型两两之间没有依赖关系
对于如图1所表示的DAG,我们希望可以将其分层为:[[m, u], [i], [n, j], [v]]。这样做的好处是:对于某层的模型列表,由于这些模型列表之间没有依赖关系,我们可以使用并发(concurrent)对这些模型进行处理,从而缩短模型运行的整体时效。
拓扑排序
在计算机科学领域,有向图的拓扑排序是其顶点的线性排序,使得对于从顶点到顶点的每个有向边(u, v),在排序中u都在v之前。对有向图的拓扑排序思想也很简单:循环检查图中的每个节点,如果某个节点的入度为0,则代表该节点不依赖任何一个模型,可以把这些入度为0的节点分为同一层级;此后从图中去掉由这些节点以及从这些节点出发到其他节点的有向边,生成新图并在生成的新图上进行下一层入度为0的模型的判断,直到所有的节点都被处理完成或者遇到无法找到入度为0的节点为止。对于后面一种情形,剩余的每个顶点都至少有一条入边,意味着剩余节点之间产生了环路。因此拓扑排序同时可以对模型之间的依赖关系进行环路检测,这样也降低了对模型依赖关系检测方面的人工成本。
对于图1所示的有向图,令r代表模型层级所组成的数组:1:只有模型m和模型u的入度为0,将模型m和u加入r中,并删除由模型m和u指向其他节点的边。r =[[m, u], ]。
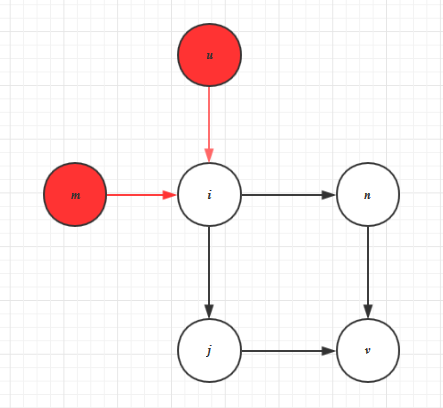
图2 解决有向图中第一层的模型层级
2:在剩下的节点中递归计算模型之间的层级,直到所有的节点都存在于r中。
3:最终获得整个模型调用链的层级:[[m, u], [i], [n, j], [v]]。
生产优化
从上面的描述可以看出,使用拓扑排序对某个业务线所调用的模型进行分层并对每个层级进行并发计算是可以缩减整体的模型调用时间的。但是我们可以做的更好。考虑如下的模型调用:
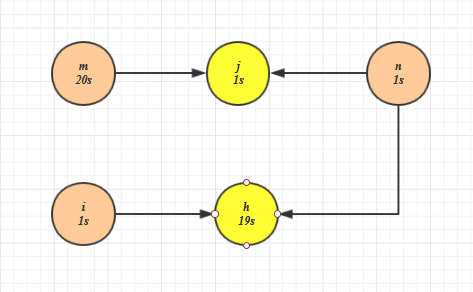
图3 模型依赖样例
模型j依赖模型m和n,模型h依赖模型i和n。按照之前的算法模型的层级可以表示为:r = [[m,n,i], [j,h]]。此时如果分别对模型的层级进行并发,会让模型j和模型h的启动时间至于模型m、n、i中的最长运行时间后。但实际上模型j或者模型h的启动时间并不完全取决于模型m、n、i中的最长运行时间。比如,假设模型m运行时间为20s,模型h的运行时间为19s,模型i、n、j的运行时间为1s。如果等待模型m、n、i运行完成后才去运行模型j和h,则整体的调度时间为20s + 19s(max(m,n,i)+max(h,j))。如果在模型i和模型n运行完成后就去触发模型h,使得模型h与模型m之间并发,则整体的调度时间可以缩短为20s+1s(max(m,max(i,j)+h)+j)。
从上面的比较可以看出,使用实时触发以及并发机制进行模型调度比单纯使用并发会具有更高的效率。
除了以上的优化外,我们还在模型调用的可配置、模型依赖检测等方面做出了部分改进。
总结
拓扑排序算法的思想虽然简单,但它在整个模型调度模块发挥了不可磨灭的作用。经过我们的优化,目前风控系统中模型调用的平均耗时下降了30%以上。