
风险控制恒久以来就是金融服务中非常关键的环节,随着移动互联网和消费互联网的发展,金融的业态发生了变化,需要越来越多地关注线上的用户体验,需要提高服务流程的效率,更加自动化和实时化的风险决策,另外随着AI技术新浪潮的来临,也给风控增加了新的方法,使得可以通过深度学习等技术提高风险决策效果。
不变的是透过一些观察来预判风险,这些观察最终可以抽象成数据,可以是结构化的,也可以是非结构化的,例如在中小企业授信中的“三品三表”和零售信贷中的“征信”,预判风险是指预测发生风险事件的概率或者损失,例如信用卡的逾期概率。所以想花点时间来“考古”一下传统风险模型里面的两个有趣问题,对于我们如何理解和使用模型或许也有借鉴意义。
01 逻辑回归与WOE
逻辑回归(logistic regression)长期都是风险预测的主要模型,用神经网络的角度来看其实是一个激活函数为Sigmoid的一层网络,与之相伴的一个数据预处理方法是WOE(Weight of Evidence)编码,这个编码也是和评分卡紧密相关的,有耳熟能详如下的一些好处
- 标准化:自变量编码后具备了标准化的性质,不同变量的WOE变量具有可比性;
- 异常值处理:变量的极值变化后,成为非异常值;
- 线性相关:通常转化后的WOE编码与因变量(Log Odds)呈线性相关,一层网络是无法捕获原始变量的非单调性的;
那逻辑回归和WOE编码还有没有更本质的联系?为什么就像设计好的一样?为什么不直接使用分组(buckets/bins)里的坏样本率?我们来看看逻辑函数(Log Odds)的如下展开成总体坏样本率的Log Odds与坏好样本上自变量条件概率商的对数的和
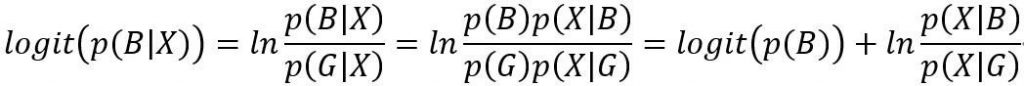

其中X表示自变量,B表示判断是否为坏样本,G表示判断是否为好样本,做如下假设
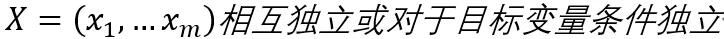
则有以下分解
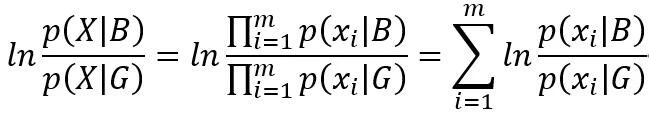
从而有等式,可以看到红色部分即每个自变量的WOE编码
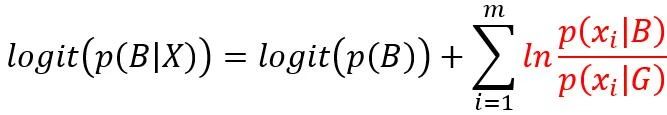
注意到以上的红色部分是连续条件概率密度函数,另外有自变量对于因变量相互独立的假设,所以在更加普适的情况下,需要WOE前的参数和截距项来更好地拟合Log Odds,通过以上分析我们可以清楚的看到WOE是设计出来能够适配逻辑回归的。
02 采样后的样本还原
在训练模型的时候我们常常会使用采样技术来应对类别不平衡的问题,可以有欠采样、过采样、SMOTE方法等。采样带来了样本分布的变化,根据采样后的样本训练的模型,在真实样本分布下的模型推论往往需要做相应的还原操作,那还原背后的逻辑是什么?我们以欠采样/过采样为例
令X为采样前样本的特征,根据Bayes公式有如下等式
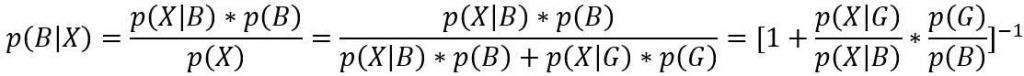
因此有
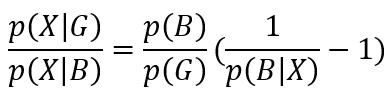
相应的对于采样后的样本
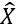
有如下等式
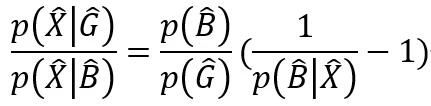
因为采样前后不改变特征对于分类的条件概率,即有以下恒等式
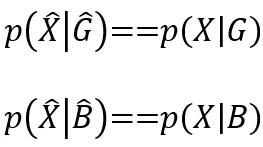
因此有以下等式
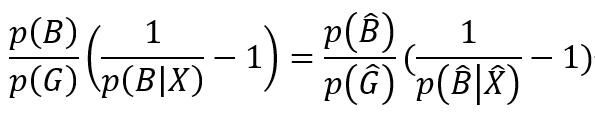
从而在采样前的样本上的推断概率为
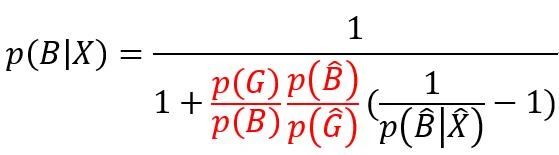
从红色的部分可以发现采样前后的类别分布在调节样本还原,再试试看加上Log Odds,可以发现
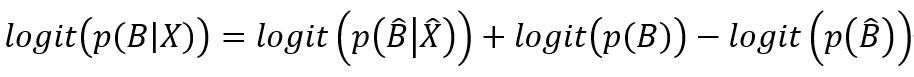
及逻辑回归的截距发生了变化,其他参数没有变化。
03 结束语
现今热门的机器学习基本是起源自经典传统模型,依托于计算机强大的算力,从海量数据中发现复杂规律,并利用规律对未来、未知情况进行预判。深入了解传统经典模型解决了什么问题、如何解决问题,将非常有助于业务实践,并能反哺于更高阶、更抽象地技术学习和应用。