背景
随着业务场景的不断丰富,基于T+1天的数据决策显得捉襟见肘,而深度分析与挖掘的实时性要求也越来越强烈。当数据规模较小时,使用事务性数据库(Oracle, Mysql)进行数据分析,仍是一种不错的选择。但当数据达到一定的量级,传统数据库无法有效存储时,我们就需要寻找一种分析型数据库,既可以满足较大规模数据存储,又可以提供实时地插入/更新/查询等操作。而Apache Kudu就可以很好的满足这种需求。
Kudu是Cloudera开源的新型列式存储系统,是Hadoop生态圈成员之一,专门为了快速更新和实时分析的场景而设计的。它是一款介于HDFS和HBase的性能特点之间的一个系统,填补了Hadoop存储层HDFS数据不可变,无法满足实时分析的缺陷。Kudu可以集成Impala/Spark SQL等查询引擎,使用SQL操作Kudu数据,这大大降低了分析师的使用门槛。
实时同步架构
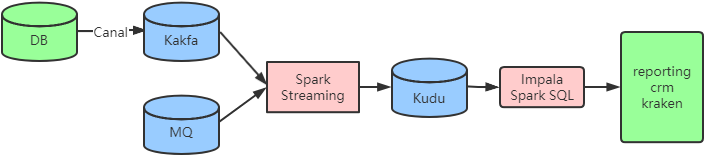
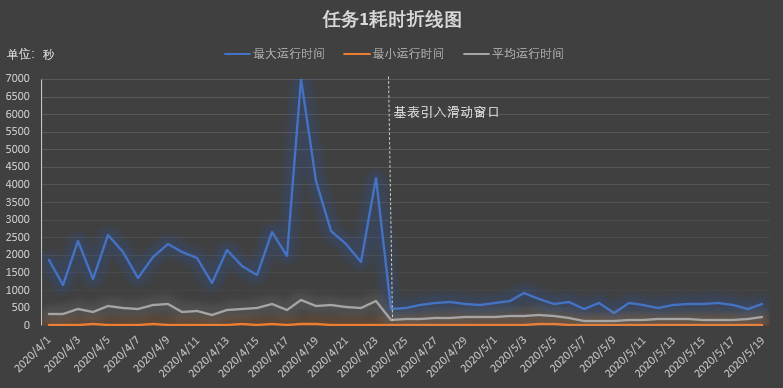
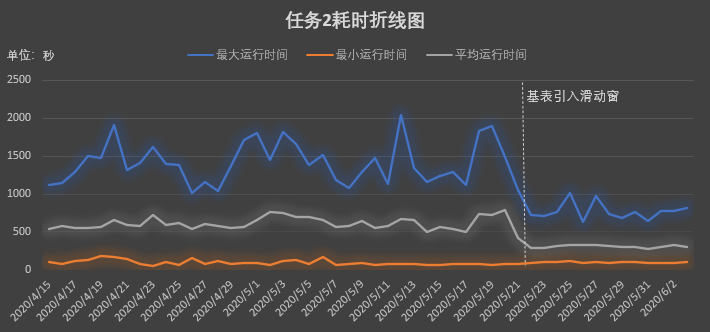
使用Spark Streaming将数据源源不断的写入Kudu,并根据Kudu表的主键实现幂等性和更新操作,之后Impala可以查询Kudu上的实时数据,以满足实时分析的需求。但该简单粗暴的模式存在一个缺陷,随着Kudu表的数据不断增长,最终会影响Kudu服务的响应时间和稳定性。基于超大Kudu表的任务时间不断增加,最终影响业务的实时性。
引入滑动窗口模式
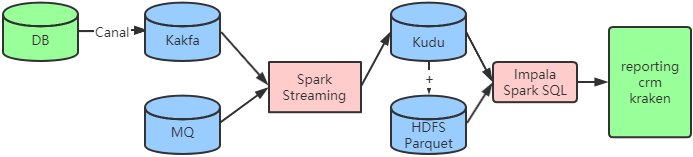
引入HDFS,将Kudu中的历史数据移动到HDFS。借助HDFS以低成本获得无限可伸缩性的特性,并配合Parquet文件格式,可以使Impala on HDFS获得极高的吞吐量和访问效率。一般情况下,这些表按时间单位进行分区滑动,通常使用每日、每月或每年。然后创建View,将Kudu和HDFS联合起来呈现完整的数据。数据分析师通过view进行查询,既可以满足实时性的要求,又避免了数据的缺失。
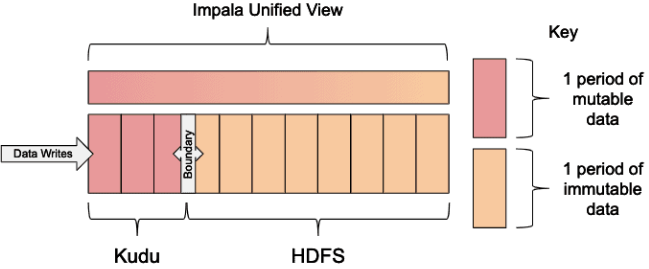
这里有两个窗口:一个是Kudu和HDFS数据移动的分区滑动窗口,一个是View联合两大存储的分区滑动窗口。我们以天为Range分区字段,对滑动窗口模式进行详细剖析:
第一步:建立带有Range时间分区字段的Kudu表和HDFS表。
CREATE TABLE table_kudu
(
……
PRIMARY KEY(id, time)
)
PARTITION BY
HASH(id) PARTITIONS 2,
RANGE(time) (
PARTITION ‘2020-06-01’ <= VALUES < ‘2020-06-02’,
PARTITION ‘2020-06-02’ <= VALUES < ‘2020-06-03’,
PARTITION ‘2020-06-03’ <= VALUES < ‘2020-06-04’,
……
)
STORED AS KUDU;
CREATE TABLE table_parquet
(
Id STRING,
time STRING,
……
)
STORED AS PARQUET;
第二步:将Kudu表数据拷贝到HDFS
insert overwrite table table_parquet
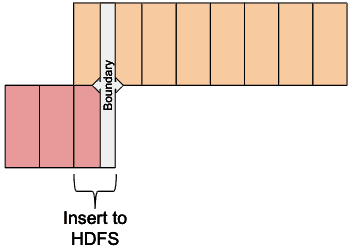
SELECT *
FROM table_kudu
WHERE time >= date_add(“${var:new_boundary_time}”, -1)
AND time < “${var:new_boundary_time}”
UNION ALL
SELECT *
FROM table_parquet;
第三步:修改view的滑动窗口,使其包含新增的HDFS数据,不包含旧的Kudu
ALTER VIEW my_iview AS
SELECT *
FROM table_kudu
WHERE time >= “${var:new_boundary_time}”
UNION ALL
SELECT *
FROM table_parquet;
第四步:新增Kudu明日分区、删除Kudu最老的分区
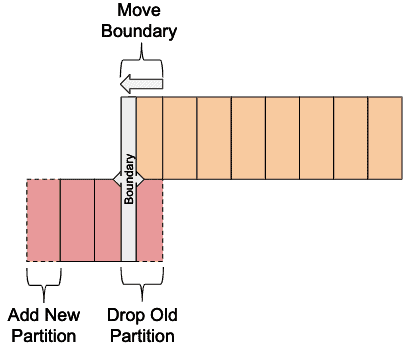
第五步:将第二到第四步放到一个定时任务中。
总结
基于滑动窗口模式的实时同步架构,可以充分利用Kudu和HDFS的两种存储系统的优势:
1.实时数据实时查询;
2.Kudu自身支持更新操作;
3.HDFS保证了数据的完整性,提供了高吞吐量,降低了存储的成本。
结合查询引擎Impala/Spark SQL,能够为数据分析师提供实时的快速查询分析的能力。并且该模式,相较于数据全量存入Kudu的模式,任务耗时明显降低。