
常用的社区发现类图算法有联通子图,标签传递,Louvain Modularity及三角计数。每种算法侧重点不同,复杂度也有较大差异,实际应用中需要考虑计算时间和资源状况。针对目前项目,三角计数及标签传递算法更加便于工程落地。在实际工作中,我们对三角计数算法进行了两方面优化:1.将该算法从无向图推广到有向图;2.只对待观察的“前景点”进行计算,避免了大量的全局计算。本文将详细介绍FD-Triangle Count的原理及实现。
应用场景
(一)用于社区发现
通话网络中你的联系人中有很多人相互认识,大家的通信关系中有很多三角形,说明社区很强很稳定,大家联系比较紧密;如果一个人只呼叫了很多人,却没有形成三角形,则说明社交群体很小很松散。
(二)衡量社群耦合关系的紧密程度
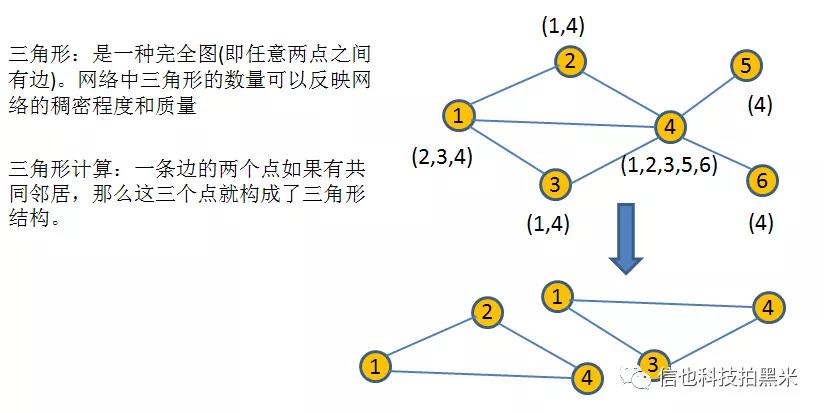
通过三角形数量来反应社区内部的紧密程度,作为一项参考指标。下图中,节点1、4的三角计数为2,节点2,3的三角计数为1。

FD-Triangle Count算法思路
- 在背景图中选取所有需要求三角计数的节点得到集合smp。
- 从smp的节点出发,沿着边(忽略方向)游走到其邻居,并在起始点的临时变量nb1中记录下邻居的ID。此时,得到了smp所有的一阶邻居的集合smpnb;
- 从smpnb的节点出发,沿着边(忽略方向)游走到其邻居,并将邻居ID记录在起始节点的临时变量nb2中。此时得到了smpnb的一阶邻居,既smp的二阶邻居;
- 从smp的节点出发,沿着(主叫)边游走到其邻居,求nb1和nb2的intersection的count,累加到smp节点的tricnt变量。
- 从smp的节点出发,沿着(被叫)边游走到其邻居,求nb1和nb2的intersection的count,累加到smp节点的tricnt变量。
时间复杂度:O(N * (E/V)^2),其中N为前景点个数,E为边的条数,V为总节点个数。
图性质:有向图
FD-Triangle Count的GSQL实现
CREATE OR REPLACE QUERY triangles(STRING fileLocation) FOR GRAPH Social{
SetAccum<INT> @nb1; //局部累加器,用来保存smp的一阶邻居的ID
SetAccum<INT> @nb2; //局部累加器,用来保存smpnb的一阶邻居的ID
SumAccum<FLOAT> @tricnt; //局部累加器,用来累加三角计数
OrAccum @flag = False; //局部累加器,用来标记节点是否已经被访问
FILE f1(fileLocation); //局部变量,用于最后输出
//在背景图中选中待观察的点smp(前景点)
all = {User.*};
smp = SELECT s
FROM all:s
WHERE s.is_sample==1
;
//游走到smp的邻居,并把邻居ID记录到@nb1
smpnb = SELECT t //选择目的点集合smpnb
FROM smp:s-()->:t //忽略边的方向,其中s和t分别为起始点和目的点的别名
ACCUM //累加器,对边进行处理
s.@nb1 += t.user_id
;
//游走到smpnb的邻居,并把邻居ID记录到@nb2
smpnb2 = SELECT t
FROM smpnb:s-()->:t
ACCUM
//为了避免重复计算,仅考虑满足条件的
IF s.user_id < t.user_id THEN s.@nb2 += t.user_id END
;
//从smp集合出发,按照主叫(linked)边收集二阶邻居信息
tmp = SELECT s
FROM smp:s-(Linked)->:t
ACCUM
IF NOT t.@flag THEN
t.@flag = True, //标记此节点已经被处理,避免重复计算
s.@tricnt += COUNT(t.@nb2 INTERSECT s.@nb1) //求smp一阶邻居和其二阶邻居的交集的个数
END
;
//从smp集合出发,按照被叫(linked_by)边收集二阶邻居信息
tmp = SELECT s
FROM smp:s-(Linked_by)->:t
ACCUM
IF NOT t.@flag THEN //有些节点已经在前面主叫的迭代中处理过了,因此需要过滤掉
s.@tricnt += COUNT(t.@nb2 INTERSECT s.@nb1)
END
;
//输出smp集合中每个顶点的ID和对应的三角计数到CSV
PRINT smp.user_id,smp.@tricnt TO_CSV f1;
}
Benchmark:全局无向图三角计数
CREATE QUERY tri_count() FOR GRAPH social {
# Compute the total number of triangles in the GRAPH. No input parameters are needed.
SumAccum<int> @@cnt; //全局累加器,用来保存整图的三角计数
SetAccum<VERTEX> @self;//局部累加器,用来保存自身ID
//选中所有节点
all = {User.*};
all = SELECT s
FROM all:s
ACCUM s.@self += s;
# For each edge e, the number of triangles that contain e is equivalent
# to the number of common neighbors between vertices s and t
tmp = SELECT t
FROM all:s -() -:t
WHERE getvid(s) > getvid(t) //避免存在双向边时重复计算
ACCUM INT c = COUNT((s.neighbors() MINUS s.@self) INTERSECT (t.neighbors() MINUS t.@self)),
@@cnt += c;
# Each triangle is counted 3 times for each edge, so final result is divided by 3
PRINT @@cnt/3 AS num_triangles;
}
算法性能对比
背景图及实验环境:背景图顶点1.1亿,边5.3亿。前景点12万。主机48核心、512G内存。图数据库Tigergraph。
结果:FD-Triangle Count算法整体运行时间为37秒;全局无向图算法2小时内没有返回。
总结
本文介绍了FD-Triangle Count——前景有向图三角计数算法的工程应用,并与经典的全局无向图算法进行了对比实验。
图算法的性能往往决定了其应用的上限,因为在大规模图上运行图算法会造成运算时间和资源的几何级增长:动辄需要运行几个小时,并且也有可能因为占用内存较多造成OOM的情况发生。因此在设计算法时需要充分考虑图的性质和规模,对于算法的计算复杂度和空间复杂度有一定的评估,在分布式环境下还需要考虑网络通信量。三角计数算法及其变种可以解决两条范围内的遍历、筛选及社区发现等问题,在实践中有着重要的意义。
参考文献
https://docs.tigergraph.com/tigergraph-platform-overview/graph-algorithm-library#triangle-counting