
近些年,随着业务场景的不断变化,企业对数据服务实时化的需求日益增多。为了满足这一点,需要在分布式文件系统(如HDFS)实现高效且低延迟的数据摄取及数据准备,从而构建面向分钟级延时场景的通用统一服务层。但是在构建准实时场景的服务时,更新数据并不罕见,不同的场景更新频率也不同。除此之外,可能还需要在最新视图、包含所有更新的历史视图甚至最新增量视图上进行分析。
通常的架构是使用流和批处理的双重系统,如下图。


Apache Hudi框架能够满足上述的所有需求。Hudi的设计目标正如其名,Hadoop Upserts Deletes and Incrementals Processing,强调了其主要支持 Upserts、Deletes 和 Incremental 数据处理,其主要提供的写入工具是Spark HudiDataSource API 和自身提供的DeltaStreamer。它除了提供经典的批处理之外,还可以在数据湖上进行流处理。能够使HDFS数据集在分钟级的时延内支持变更,也支持下游系统对这个数据集的增量处理以及查询在某个时间点的增量更改。
Hudi实时同步架构

COW:即Copy On Write,数据仅仅以列文件格式(parquet)存储。每次写操作后做数据的同步merge以更新版本并重写文件,COW表中的数据始终是最新记录,写入性能略差,但是读性能更高,对于需要尽快读取最新数据的场景可首选此模式。
MOR:即Merge On Read,数据以列文件格式(parquet)和基于行的文件格式(avro)组合存储。每次写入操作后将创建增量文件,随后将其compact以生成列文件的最新版本,达到读取时的最新数据。读的时候做merge,读性能差,但是写入数据会比较及时,因而后者可以提供近实时的数据分析能力。
需要说明的是Hudi 设计了HoodieKey,一个类似于主键的东西。内部维护着一个key的索引,用于快速定位Record所在的文件。另外,Hudi以时间轴(Timeline)的形式将数据集各项操作元数据维护起来,用来支持数据集的瞬态视图。
Near Real-Time Ingestion

将上游数据通过Kafka,使用DeltaStreamer工具读取Kafka数据源,不断地写入Hudi DataSet,同步到Hive中。根据场景选择合适的存储类型,基于支持的查询引擎对数据进行近实时查询分析。随着数据不断写入,会有小文件产生。对于这些小文件,DeltaStreamer 可以自动地触发小文件合并的任务。
Incremental ETL
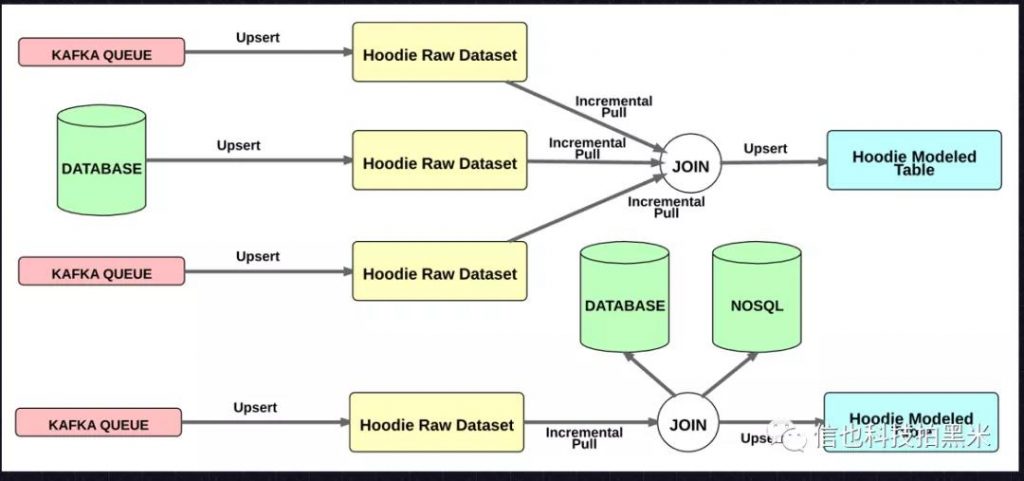
想要构建低延时的数据模型表,那么就要求HDFS数据集能进行记忆性的增量处理,即只处理数据源的更新,增量更新结果,更快地计算出结果,减少延迟,扩展性好。上述提到由于Hudi在元数据中基于Timeline维护了每次commit的时间以及对应的文件版本,这样的话我们在处理数据集时就可以基于startTime和endTime从特定的数据集中提取增量的变更数据集。基于此就可以做双流join和流与静态数据的join从而对存储在HDFS中的数据模型表计算和更新。
案例分享
接下来,基于实际的案例来说明Hudi在实时数仓中的应用。我们借助增量处理来支持流计算框架所支持的流和批的连接。
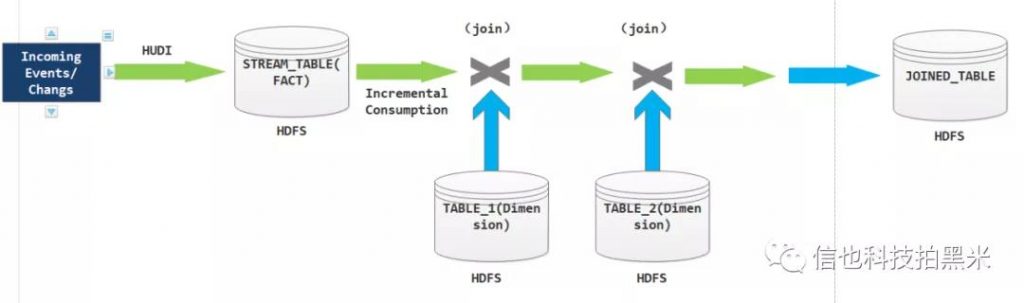
上图的示例是通过Hudi将Kafka数据写入到事实表中,然后将一个事实表连接到多个维度表,最终建立一个Join Table,这个案例可以节省硬件花费的同时显著降低延迟的场景。
Hudi增量处理的具体实现是“增量视图”。下面代码展示了Hudi的实时数据同步和和增量视图的查询:
第一步:使用DeltaStreamer同步数据。
spark-submit –master yarn \
–deploy-mode cluster \
–driver-memory 2G \
–num-executors 6 \
–executor-memory 6G \
–executor-cores 3 \
–conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
–conf spark.sql.parquet.writeLegacyFormat=true \
–conf spark.sql.hive.convertMetastoreParquet=false \
–conf spark.rdd.compress=true \
–conf spark.memory.fraction=0.4 \
–conf spark.storage.memoryFraction=0.1 \
–conf spark.executor.memoryOverhead=2G \
–conf spark.driver.memoryOverhead=1G \
–class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer /test/hudi_jars/hudi-utilities-bundle_2.11-0.6.0.jar \
–continuous \ #这里参数代表的是流式处理,当然也可以选择批处理
–props hdfs://ns1/hudi/properties/hudi_test.properties \ #配置kafka的信息
–schemaprovider-class org.apache.hudi.utilities.schema.SchemaRegistryProvider \
–source-class org.apache.hudi.utilities.sources.JsonKafkaSource \
–target-base-path hdfs://ns1/hudi/warehouse/hudi_test \ #数据存储的路径
–op UPSERT \ #操作类型
–enable-hive-sync \#Hudi DataSet同步到Hive中
–target-table hudi_test \
–table-type COPY_ON_WRITE \
–source-ordering-field inserttime \
–source-limit 100000 \
–hoodie-conf hoodie.metrics.on=true \ #下面主要是开启Hudi监控
–hoodie-conf hoodie.metrics.reporter.type=GRAPHITE \
–hoodie-conf hoodie.metrics.graphite.host=127.0.0.1 \
–hoodie-conf hoodie.metrics.graphite.port=2003 \
–hoodie-conf hoodie.metrics.graphite.metric.prefix=hudi_metrics
上述的这段代码,将Kafka数据源源不断地同步到Hudi数据集(HDFS),关联到Hive的hudi_test表中。我们查看Hive,会发现自动地创建了一张hudi_test表,进一步查看表字段信息,得到如下:
CREATE EXTERNAL TABLE `hudi.hudi_test`(
`_hoodie_commit_time` string,
`_hoodie_commit_seqno` string,
`_hoodie_record_key` string,
`_hoodie_partition_path` string,
`_hoodie_file_name` string,
`actype` int,
`sendos` int,
`recoverable` boolean,
`token` string,
`processno` int,
`ip` string,
`userid` int,
`inserttime` string,
`subtype` string,
`reasoncode` string,
`ext` string,
`sourcetype` int,
`appver` string)
PARTITIONED BY (
`__dt` string)
ROW FORMAT SERDE
‘org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe’
STORED AS INPUTFORMAT
‘org.apache.hudi.hadoop.HoodieParquetInputFormat’
OUTPUTFORMAT
‘org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat’
LOCATION
‘hdfs://ns1/hudi/warehouse/hudi_test’
TBLPROPERTIES (
‘last_commit_time_sync’=’20200820140621’,
‘transient_lastDdlTime’=’1597734434’);
很明显在原有数据schema的基础上增加了以`_hoodie`开头的五个字段,其中增量处理查询就是基于`_hoodie_commit_time`这个字段的。
第二步:Hive查询增量视图。
set hoodie.hudi_test.consume.mode=INCREMENTAL;
set hoodie. hudi_test.consume.max.commits=5;
set hoodie. hudi_test.consume.start.timestamp=20200820134636;
select count(*) from hudi. hudi_test where `_hoodie_commit_time`>20200820134636;
整体来说,上面两步就是创建了一个Hudi表(hudi_test),然后基于该表增量查询在startTime提交时间之后所有变更的记录。基于该查询,可以在批处理数据上创建增量数据管道。
Hudi监控
在Hudi同步数据过程中,监控是非常重要的,我们需要查看Hudi同步数据中的一系列指标,比如CommitTime、Total Records Written、Total Partitions Written、File等。在这里,我们使用Graphite + Grafana工具展示我们关注的的指标,以此来进行管理,预警。

总结
本文首先阐述了传统的Hadoop数仓在数据延迟以及实时性方面遇到的问题,进而介绍了在构建实时数仓中需要具备的两个原语:更新插入和增量处理,并说明Hudi在这方面是如何满足这两个要求的。
然后基于实际的实时数据同步和增量处理案例,简单地阐述了Hudi的实际应用以及对于Hudi的监控。
目前Hudi还只是支持Spark,推荐的Hive版本是2.+以上。但是对于Flink的集成,通过Flink将数据写入Hudi数据湖,社区也在加快这方面的工作,让我们共同期待。