
第一章 前言
延续了大数据海洋生物的产品系列,海象在海水中靠着流线型的身体、发达的肌肉以及强有力的鳍状肢,行动自如,大而不笨。就如同我们的海象系统一样,在承载了成千上万的文件之后依然可以稳定,高效的运行。我们的目标是秒接入,秒传!
第二章 系统简介
随着我们部门系统不断增加,对文件存储的需求也越来越大。上传完视频和图片之后我们还有实时预览的需求,所以用传统的ftp保存就不能满足我们了。由于我们这边需要保存大量的图片和视频,使用第三方阿里云,七牛云,腾讯云这些存储服务,要提前走流程审批,提预算,费用较贵,使用第三方的服务也不利于后期我们其他系统的接入和存储。我们就有了做个自己的分布式存储系统的想法,海象由此而生。海象可以快速接入,只需管理员后台开通账号,对接接口即可。海象目前提供了restful接口上传和js直连上传。根据我们的接口文档要求对接即可享受秒传服务。
第三章 分布式存储对比
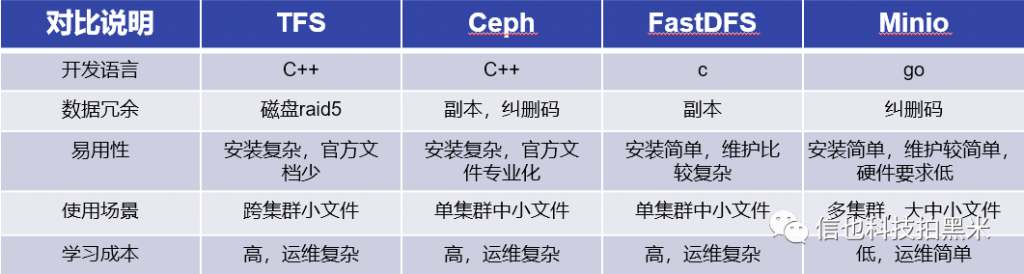
目前主流的分布式存储服务有: TFS, Ceph, FastDFS, Minio。
- TFS :是淘宝开发的一个高可扩展、高可用、高性能、面向互联网服务的分布式文件系统,主要针对海量的非结构化数据
- Ceph: 是加州大学Santa Cruz分校的Sage Weil(DreamHost的联合创始人)专为博士论文设计的新一代自由软件分布式文件系统
- FastDFS: 是一个轻量级的开源分布式文件系统,主要解决了大容量的文件存储和高并发访问问题,文件存取时实现了负载均衡
- Minio: 是GlusterFS创始人之一Anand Babu Periasamy发布新的开源项目。Minio兼容Amason的S3分布式对象存储项目

经过对比发现MinIO 对象存储系统是为海量数据存储、人工智能、大数据分析而设计,基于Apache License v2.0 开源协议的对象存储系统,它完全兼容 Amazon S3 接口,单个对象的最大可达 5TB,适合存储海量图片、视频、日志文件、备份数据和容器/虚拟机镜像等。
Minio采用去中心化设计,摒弃复杂的大规模集群调度管理去除对第三方组件zookepper,kafaka等的依赖,减少风险因素与性能瓶颈,打造高可靠的集群、灵活的扩展能力以及超高的性能。
Minio集群安装简单,监控完善,易于维护,对linux运维要求很低。Minio采用的是建立众多的中小集群组成集群联盟,减少集群之间出错互相影响。
第四章 海象系统架构
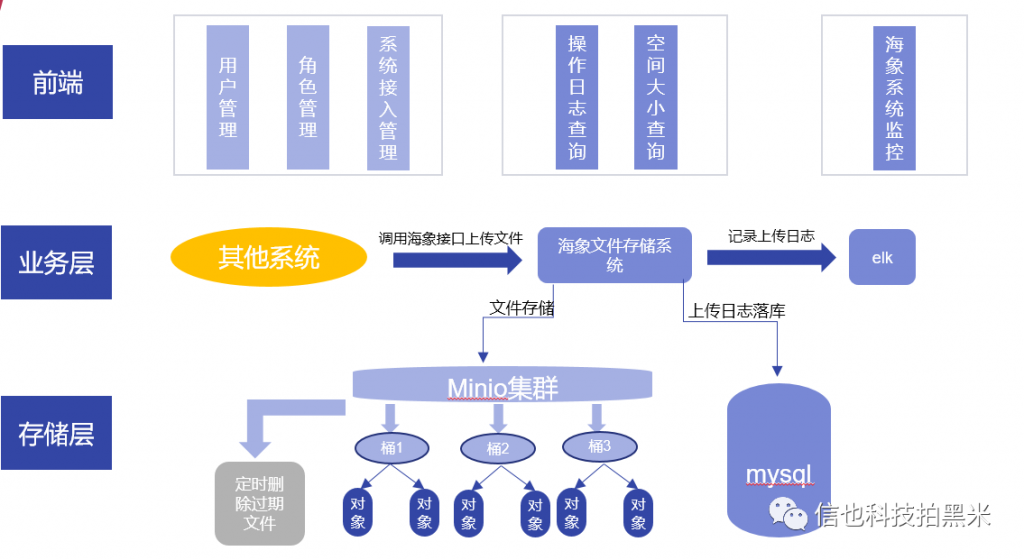
海象系统总体分为两大部分web端管理系统,底层Minio存储系统。Web端主要功能:
- 用户角色权限管理
- 系统接入权限开通管理
- 文件夹占用空间查看,文件下载,删除操作
- 海象整体监控
目前minio集群由两台机器构成的,每台机器创建两个data目录。其他系统调用接口上传文件时,minio会把这个文件平均分成两份放到两天不同的机器中。当一台的某个文件损坏时,minio会自动检测并恢复此文件。
第五章 minio工作原理分析
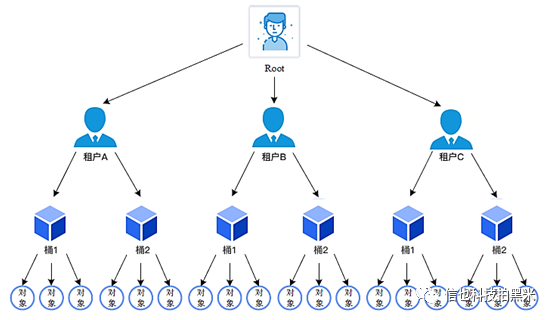
对象:类似于hash表中的表项:它的名字相当于关键字,它的内容相当于“值”。桶:是若干个对象的逻辑抽象,是盛装对象的容器。租户:用于隔离存储资源。在租户之下可以建立桶、存储对象。用户:在租户下面创建的用于访问不同桶的账号。可以使用MinIO提供的mc命令设置不用用户访问各个桶的权限。
上传一个文件后minio会生成两个文件part.1和xl.josn 其中xl.josn中存放的是这部分文件的详细信息(文件大小,桶位置,纠删码信息等),part.1中会存放纠删码或者文件信息。下载一个文件时,minio会根据存储的纠删码和文件部分组合合成一个完整的文件。
Minio中引入了纠删码技术,纠删码的具体作用是:
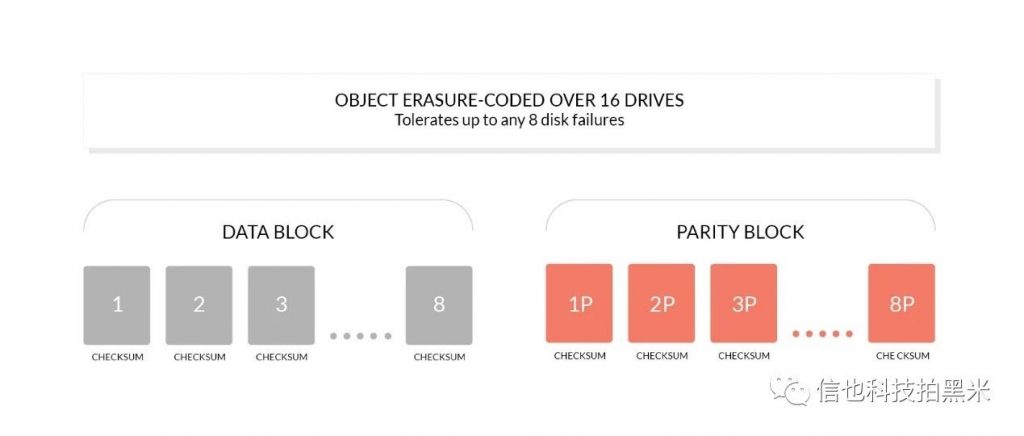
纠删码是一种恢复丢失和损坏数据的数学算法, Minio采用Reed-Solomon code将对象拆分成N/2数据和N/2 奇偶校验块。这就意味着如果是12块盘,一个对象会被分成6个数据块、6个奇偶校验块,你可以丢失任意6块盘(不管其是存放的数据块还是奇偶校验块),你仍可以从剩下的盘中的数据进行恢复
纠删码的工作原理和RAID或者复制不同,像RAID6可以在损失两块盘的情况下不丢数据,而Minio纠删码可以在丢失一半的盘的情况下,仍可以保证数据安全。而且Minio纠删码是作用在对象级别,可以一次恢复一个对象,而RAID是作用在卷级别,数据恢复时间很长。Minio对每个对象单独编码,存储服务一经部署,通常情况下是不需要更换硬盘或者修复。Minio纠删码的设计目标是为了性能和尽可能的使用硬件加速。
MinIO对象存储系统从设计之初就考虑到修复静默错误,从被修复的目标来说,按照大小可以分为以下三种类型的修复:某个对象、某个桶、整个集群。当文件由磁记录磨损、磁盘幻象写(phantom writes)、磁盘指向错误导致损坏时,在控制台上执行mc命令即开始进行数据修复。该命令一方面向minio发送数据修复的HTTP请求,另一方面不断地接收minio服务进程返回的修复进度信息,而后输出到控制台,直到修复工作完毕。如前面所述,每个对象都被分成多个分片,然后存储于多台主机的磁盘上。数据修复可以分为正常、深度两种模式,正常模式下只是简单地检查分片状态信息,深度模式下会使用hash算法来校验分片的内容,找出比特位错误,同时也更耗费资源。
Minio集群不支持对单个集群进行扩展,MinIO对象存储系统的这种设计,使得系统的很多模块更加简单(比如从一个对象转换到它所在的纠删组,只用简单的哈希即可。)降低了整个系统出错的概率,使得MinIO对象存储系统更加可靠、稳定。当容量不够需要扩容时,minio支持联盟集群的形式,再创建一个minio集群和原来的集群形成联盟。当有文件上传到联盟集群时minio会判断哪个集群容量大,就向大的集群存储,以达到容量均衡的目的。
第六章 线上运行情况及监控
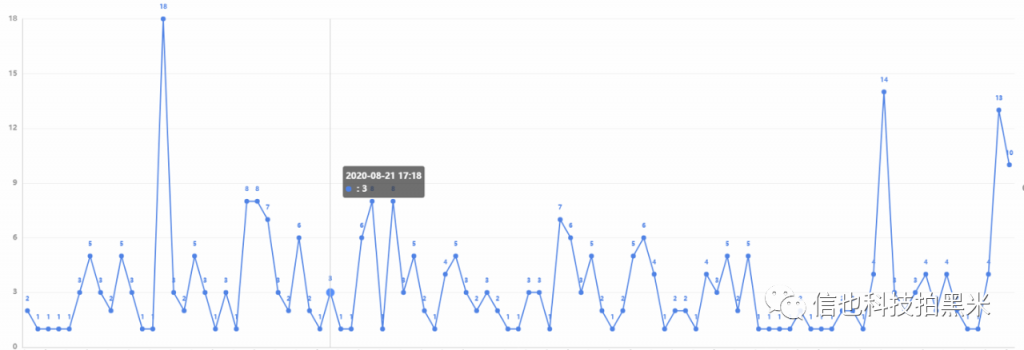
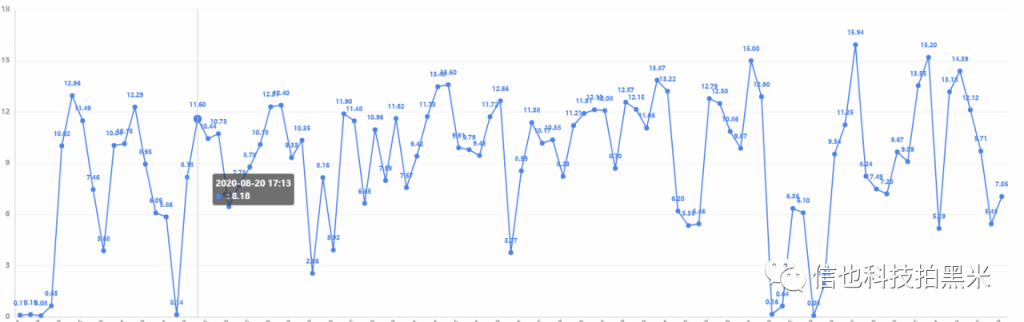
线上目前已稳定运行。
参考文献:《MinIO技术白皮书》https://blog.csdn.net/liuben/article/details/101529892
本文来自信也科技拍黑米,经授权后发布,本文观点不代表信也智慧金融研究院立场,转载请联系原作者。