
这不是一篇纯技术文章,仅仅是个人对埋点经验的分享,希望通过浅显易懂的说明,让非技术的伙伴能快速了解这些埋点概念。
埋点是什么
在业务逻辑中嵌入数据采集代码的过程,就是“埋点”。它是数据采集的一种方式,主要用来记录和收集终端用户的行为。
埋点价值
移动互联网企业越来越重视用户行为数据价值。通过行为数据分析,掌握用户行为路径,行为习惯,用户偏好等,用于运营策略优化,渠道效果评估,产品功能迭代,风险决策等等。

如何埋点

1.埋点需求
由业务方提出埋点需求。需要慎重思考采集的埋点数据是用来分析什么指标?以便后续对指标进行拆分。
如何提交一个难以被拒绝的埋点需求 ?

2.埋点设计
产品经理将业务需求转化为埋点设计方案。这个过程要先了解业务流程及用户交互方式。然后再进行埋点事件和属性设计。
最初我们采用excel来管理埋点设计文档。但随着埋点版本一次一次迭代,很难管理全量埋点的修改记录。因此,我们联合借款项目研发,搭建了一个埋点设计平台,帮助业务提升埋点设计效率和准确率。
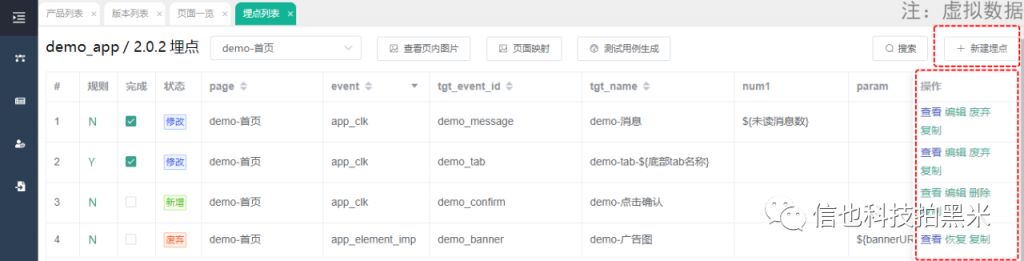

3.数据采集
数据采集是指对特定行为或事件进行采集和上报。
常见的采集方式主要有:代码埋点,可视化埋点,无埋点(也称全埋点)。

三种采集方式比较如下:
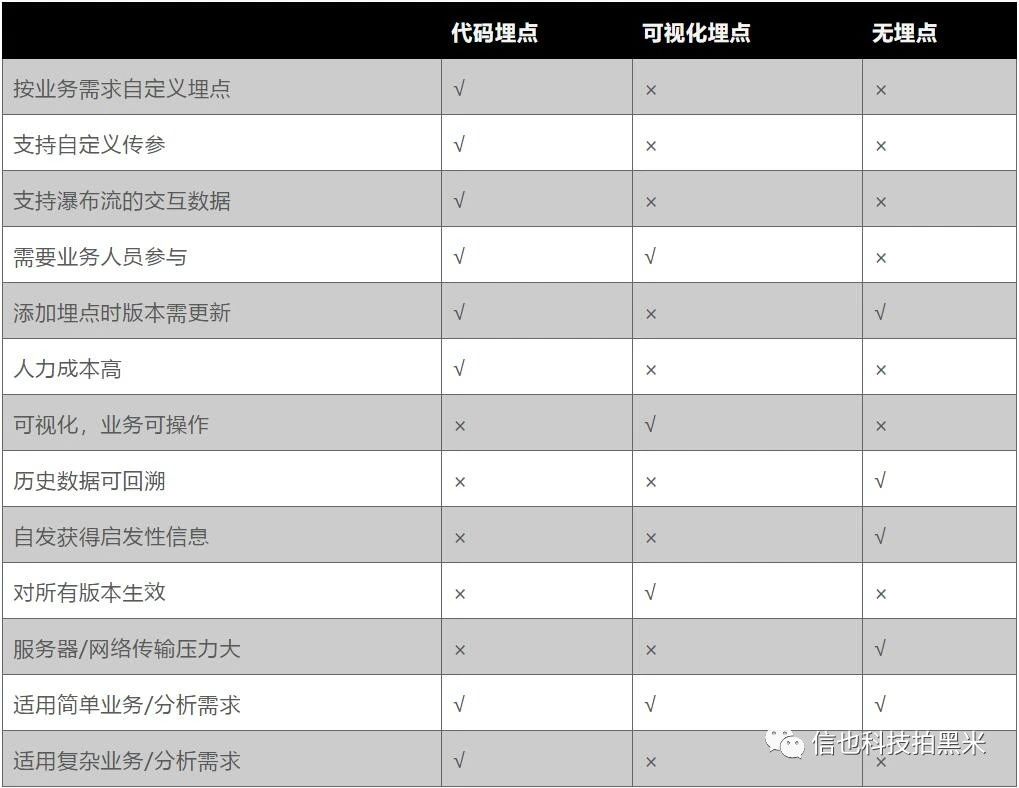
没有最好的采集方式,只有最适合业务需求的。我们业务主要采用的是代码埋点+无埋点方式。
常见的采集对象主要有:前端操作行为,后端日志,设备/浏览器信息等。

4.数据处理
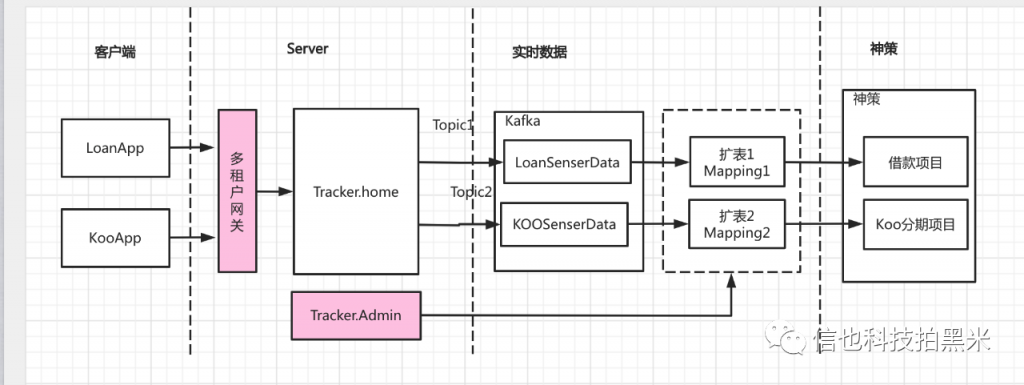
将采集的数据进行处理。我们采购的神策私有化服务,会对数据类型错误、重复数据,时间过期等异常数据进行校验和拒绝入库。
同时,为了满足行为数据和行为发生时业务标签结合在一起分析(如,用户点击借款行为和历史借款次数),我们在这个环节中,将会给埋点数据拼接上用户ID和实时业务标签,页面映射等。拼接流程如下图:
5.数据分析和挖掘
埋点数据怎么应用?
实时分析:主要使用神策分析后台工具,它提供多种分析模型。可视化页面,操作简单,基本满足产品和分析师日常实时分析需求。
注:下面分析模型的数据来源于神策Demo
【事件分析】:对数据进行筛选,分组和聚合统计分析。可以从多维度进行细分下钻。
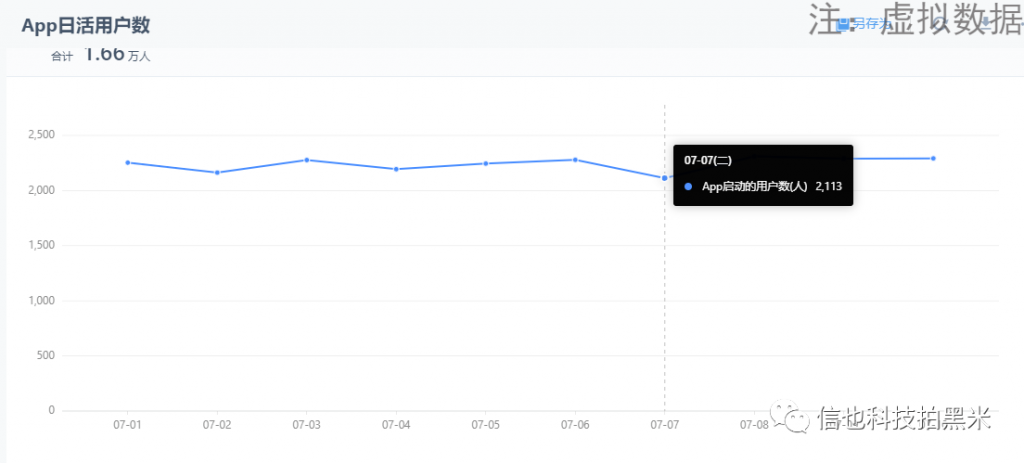
例1:App日活用户数
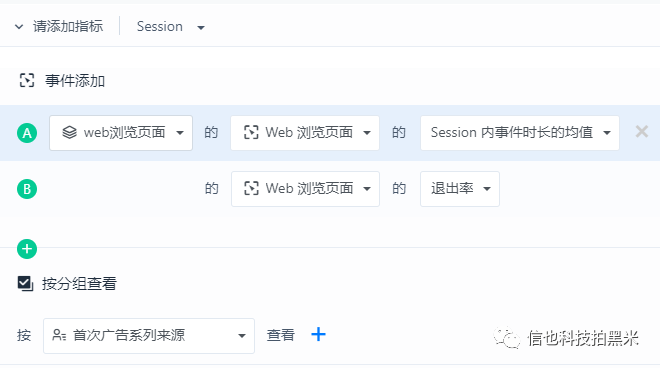
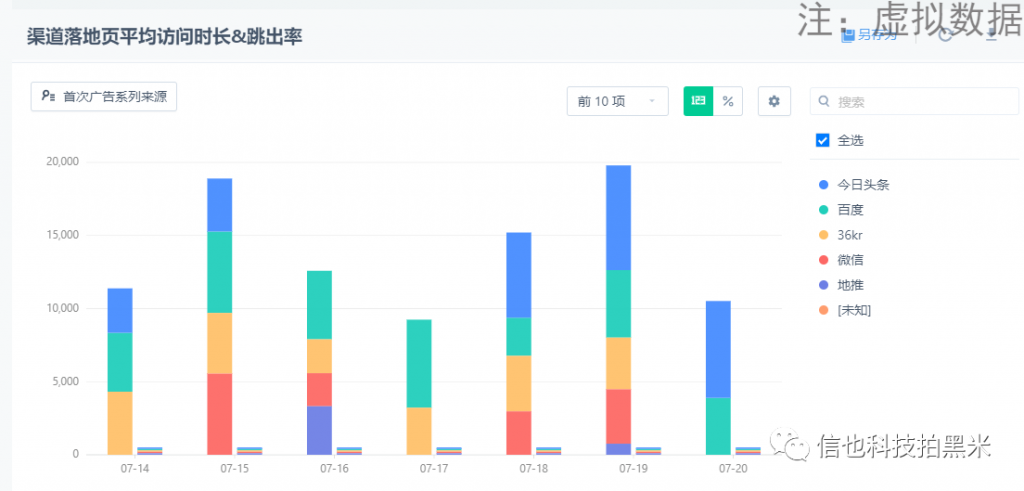
例2:渠道落地页平均访问时长&跳出率
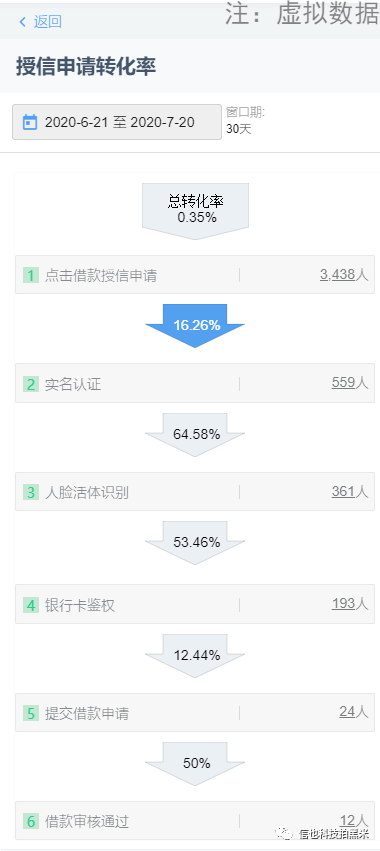
【漏斗分析】:用来分析多步骤行为之间的转化与流失。可以聚焦流程中最有效转化路径,找到可优化的短板,从而降低流失。
例3:授信流程的转化漏斗
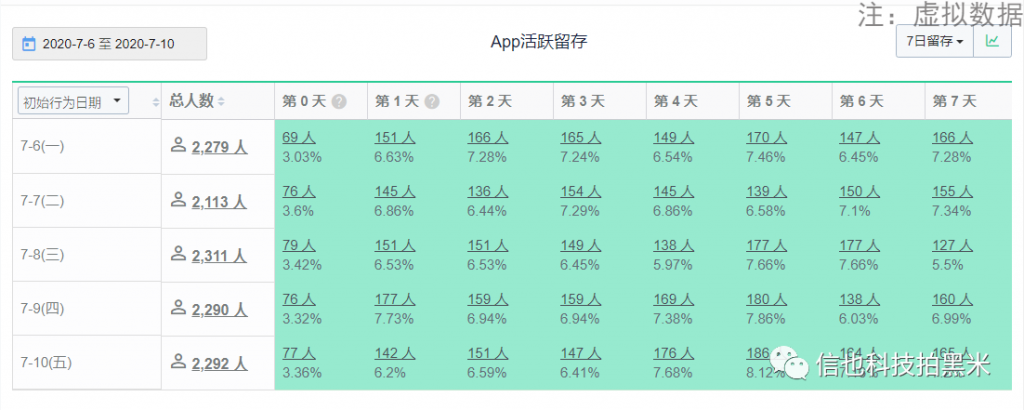
【留存分析】:分析用户参与情况与活跃度。考察进行初始行为中,有多少人会进行后续行为。这是用来衡量产品对用户价值高低的重要方法。
例4:APP活跃留存情况
其他分析模型【分布分析】【用户路径】【归因分析】【间隔分析】就不一一列举了,大家可以去神策官网的Demo体验,功能还是很强大的。
离线分析:我们将神策数据T+1同步到大数据平台,并根据事件类型解析出不同离线数仓表。商业分析师或数据挖掘工程师直接使用离线行为表和业务表结合,制作报表、建模分析等。
实时/离线决策:
【实时决策】:在数据处理后,神策会将埋点先写入Kafka中,各个业务可以去实时消费kafka的埋点数据,开发实时行为变量,用于线上实时营销、风险授信决策、风险模型打分等 。
例5:当用户进入首页,根据用户搜索的内容、商品浏览和点击等行为,去分析用户偏好,从而进行个性化商品推荐。
【离线决策】:使用离线行为数据发批量开发行为变量,用于离线策略分析、运营决策等。
例6:用户过去7天激活过APP,但没有完成注册。可以通过App消息Push“新注册用户可领取100元优惠券”进行再次唤醒。
常见问题
在数据统计分析时,业务常常会对数据的准确性产生怀疑,或发现采集到的行为数据和后端业务数据对不上,偏差比较大。这主要有以下几种原因:
a.网络异常。比如我们使用APP时,由于网络异常,导致用户的行为数据没有被上报或者请求丢失等。APP 端采集数据的丢失率一般在 1% 左右,而 H5 采集数据的丢失率一般在 5% 左右。
b.统计口径不同。比如说如何定义一个新用户?用户数的统计口径?用户页面的cookie被清理后如何处理等。
c.代码质量问题。比如埋点的研发对曝光触发时机设置错误,或者遗漏某些行为事件的采集。
d.无效请求。比如竞争对手的恶意攻击,spider等进行抓取操作,都会导致数据的异常。
总的来说,我们并不能保证数据的绝对准确,但可以采用一些策略提升数据准确性:
① 采集关键行为,推荐后端埋点;
② 有明确指标统计口径;
③ 加强埋点测试,实时导入监测。
总结
在这个大数据时代,在这个数据驱动产品运营和决策的时代,做好数据埋点,获取精确的数据,是做好数据分析的基础。本文针对公司内部埋点流程,分享了个人的经验和想法,当然埋点道路上还有很多问题(坑),希望本篇文章能帮你带来更多的思考。
参考资料:《数据驱动:从方法到实践》
本文来自信也科技拍黑米,经授权后发布,本文观点不代表信也智慧金融研究院立场,转载请联系原作者。