
文本分类是NLP领域最经典同时也是最基础的应用场景之一,有很多种方法可以实现这个任务。我们常见的是对句子进行分类,而篇章级别的分类则会更复杂一点。常见的篇章级别分类有针对文档或文章进行分类;在最近的业务场景中,我们遇到的是对多轮的通话录音转写文本进行分类。在篇章级文本分类下,传统的机器学习方法如TF-IDF就会略显不足,因为无法去学习到一些深层次的信息;而基于深度学习的方法,如FastText、TextCNN等,主要针对句子做分类,需要做一些改进才能满足篇章级分类的要求。
准备工作
为了方便理解,本文使用矩阵的形式去描述。一个句子,我们可以看作是一个三维的矩阵(batch_size, sequence_length, embedding_dim): 其中batch_size为一次训练所选取的样本数量;sequence_length为句子的长度,通常句子长度是固定的,如果超过该长度则需要做截断,不足则需要做padding;embedding_dim为词向量维度,或者特征维度。在篇章级别的场景下,我们的输入则是一个四维的矩阵(batch_size, round_length, sequence_length, embedding_dim):这里多出来的round_length可以理解为“一篇文章中有几个段落”或者“一通对话中有多少个轮次”,通常这个值也是固定的。而我们最终的输出是(batch_size, num_class),所以我们的任务就可以简单描述为:把一个三维或者四维的矩阵变换成二维,同时抽取出其中的语义信息。
模型介绍
TextCNN变型
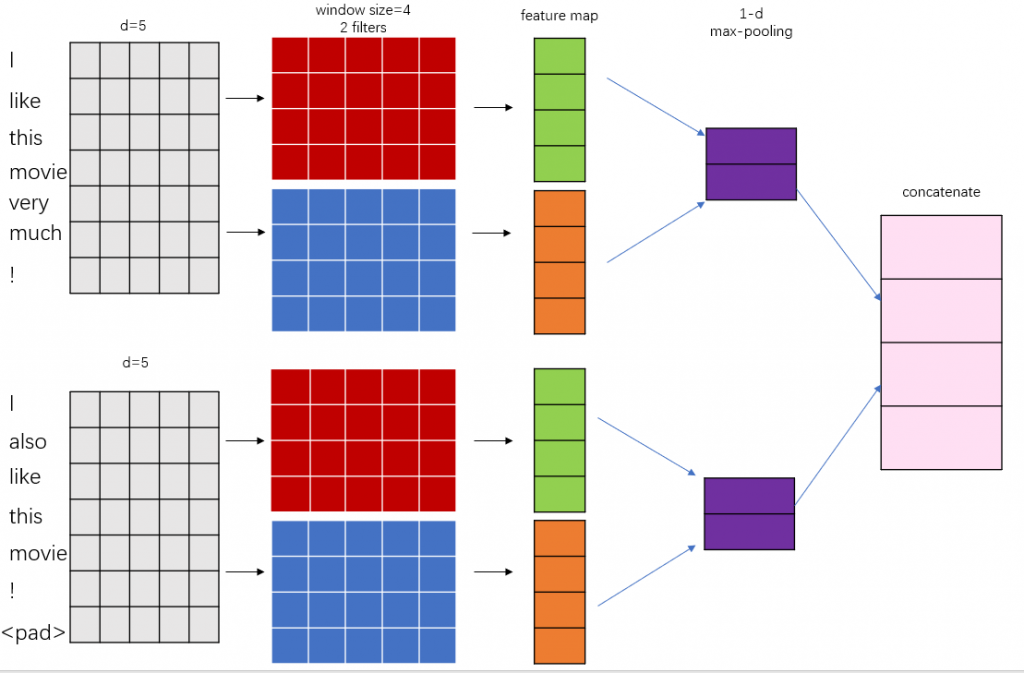
我们先简单地回顾一下TextCNN。TextCNN中的特征抽取采用的是一维卷积,每个卷积核的大小为h*k(h为卷积核的窗口大小,常用的窗口大小为2、3、4;k为embedding_dim)。卷积核从第一个词滑动到最后一个词,就形成了((sequence_length-h)+1, 1)的特征向量,多个卷积核num_filter则形成多个特征向量。在此基础上会经过1d max pooling层,这样不同长度的特征向量经过pooling层之后都能变成定长的表示。最后接一层全连接层。
在篇章级场景下,我们对TextCNN做了一些改动:round_length会被展开,篇章中的每一个句子都会经过上述的conv-pool流程,最终把每个句子的特征向量做横向的拼接,形成篇章的文本特征表示,最后接一层全连接层,如图1所示。
这种改动的主要思想是,使用每个句子各自的特征向量构建整个篇章的特征向量。在实际使用中,这种方法简单有效,能快速地得到一个baseline,可解释性强;但同时也有一定的弊端,比如会丢失句子之间的信息。

Attention类
注意力机制:Attention,其核心思想可概括为四个字:加权求和。按计算区域,Attention可分为soft Attention、hard Attention以及local Attention,在NLP领域,soft attention用的最多;按层次结构,Attention可分为单层Attention、多层Attention以及多头Attention;按模型结构,Attention的使用方式有CNN+Attention、RNN+Attention以及纯Attention等。还记得我们篇章级文本的的输入是(batch_size, round_length, sequence_length, embedding_dim)吗?在Attention的框架下,我们要做的就是在sequence_length中注意到重要的词,在round_length中去注意到最要的句子,然后加权求和,这样就得到了最终的二维矩阵(batch_size, num_class)了。
- 多层Attention
在篇章场景下的多层Attention的思想来自论文Hierarchical Attention Networks for Document Classification,如图2所示。首先获得词的embedding表示并将词向量输入词编码器即双向GRU,得到词级别的隐向量;然后对隐向量做更高层的表示,这里通过了一个单层感知机并选择tanh做非线性变换;接着初始化一个上下文的向量,和前面的隐向量做softmax得到权重;最后以权重对原始隐向量加权求和。这样就完成了词级别,即sequence_length维度上的attention,加权求和后我们得到了一个三维矩阵(batch_size, round_length,, embedding_dim),相当于获得了句向量。以同样的方法,将Attention应用到round_length的维度上,最终我们得到了篇章级别的特征表示(batch_size, embedding_dim),接一层全连接层,得到(batch_size, num_class)。
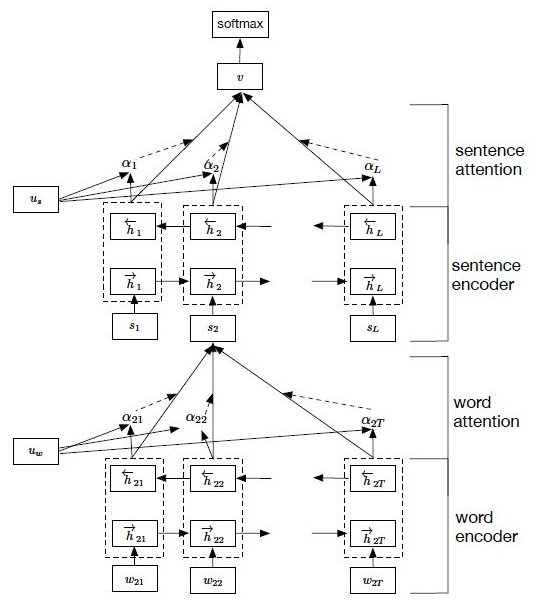
在实际应用中,多层Attention的方法能有效抽取词间和句间的关联;但是这两层Attention都依赖于RNN,训练速度慢,需要学习大量的参数。
- 单层Attention与其他模型结合
上一小节我们讲到了多层Attention中的第一层本质是获得篇章中句向量的表示,所以这一层我们完全可以使用其他的模型去替代。
还记得在2.1中我们将TextCNN的句向量进行了拼接,那在这里我们就可以不去拼接,保留round_length这一维度,直接在(batch_size, round_length, embedding_dim)上去应用Attention:也就是说,我们使用TextCNN获得篇章中每一句话的表示,然后运用Attention对每句话的特征进行加权求和,最后接一层全连接进行分类。
更进一步地,NLP领域大火的BERT模型也是可以获得句向量,得到(batch_size, round_length, embedding_dim)这样的表征的,同样的,我们可以在这一基础上去应用Attention。在实际业务中,我们发现在一些样本量较少的case下做篇章级文本分类,使用BERT+Attention的效果很好,这是由于BERT模型能很好地对句子进行编码,不需要从0开始去学习词向量的参数;在此基础上,结合Attention机制能获得较高的分类精度。
总结
本文主要和大家分享了在篇章级文本分类下,如何使用深度学习的一些思路。可以发现结合Attention机制,我们有非常多的建模方式去选择;但同时需要注意的是,不论选择什么方法,前提是理解业务背景、了解你的数据,在此基础上选择合适的模型才是最优解。
本文来自信也科技拍黑米,经授权后发布,本文观点不代表信也智慧金融研究院立场,转载请联系原作者。