
随着AI技术的发展,大量NLP问题得以解决。并且针对不同任务,有了与之对应的模型。然而,这些模型往往需要大量带标注的数据去训练,这导致在很多任务中模型变得难以使用。在项目中,由人工完全标注数据的代价非常高昂。特别是在尚未明确项目是否开展的预研阶段,不适合大规模标注人员的跟进,因此带来的标注数据规模过小的问题使得项目的可行性无法被快速验证。
我发现在很多问题中,大部分的样本都具有肉眼可见的共性(例如新闻分类的任务,体育新闻往往会大规模出现运动类型的名称),把人力花在标注这部分数据上是不划算的。使用一些特定的方法标注数据不仅减少了人工开支,提高标注效率,还可以让标注人员更专注到复杂的样本标注上,从而完善数据集。本文从文本分类和序列标注分别介绍了我在实际工作中用于解决数据标注的工程方法。
准备工作
word2vec和doc2vec是每一个NLP任务都会考虑的技术手段,原因在于它们解决了one-hot编码带来的数据稀疏问题,使词向量的表达能力更强。
自训练(self-training)是指先使用少量带标注的样本训练一个监督模型,然后利用这个模型对未标注样本打标签,把打好标签的样本放入到训练集中,再重新重复这个过程。监督模型可以是LR、GBDT,也可以是深度学习模型。
方法介绍
本文按使用目的把数据标注分为文本分类和序列标注两类。
文本分类
文本分类是指按照要求把文本划分到某个类别下。文本分类作为一个监督问题并且是经典的NLP问题,它依赖大量的高质量的标注数据。很自然地,在对未标注的文本做分类时,首先利用one-hot、word vector或者document vector的编码方式将文本向量化,然后使用无监督算法做文本聚类,把得到每个cluster作为单独的类。但是这个方法往往因为无法控制聚类的结果难以满足实际需要。例如下面三个句子:
(1)这个苹果是甜的。
(2)这个苹果是酸的。
(3)这个梨是甜的。
聚类可能会按照味道把(1)和(3)划为一类,如果业务是给文本打水果标签,得到的结果显然是不符合要求的;也可能按照水果种类把(1)和(2)划为一类,而这时如果业务是给文本打味道标签,得到的结果也是不符合要求的。在实际中,还有可能会得到难以用简单言语去描述的结果。因此根据需要人为地加入一些信息是很有必要的。具体的做法是:首先,观察数据,对数据有大概了解,大致上了解这些文本能提供的标签,并设置需要的标签,例如在新闻分类中,我们需要将文本分为金融、体育、娱乐等种类。然后,利用词向量扩充标签的关键词。最后,使用关键词过滤样本,训练自训练模型。
案例:
在一个基于文本的用户画像项目中,因为在前期尚未明确项目是否有足够的收益,所以也不会有业务专家来提供标注数据。我首先随机抽取并观察了1万条文本,通过各种各样的方式(聚类、TF-IDF、词云等)大致上了解这些文本能提供给业务专家的标签。然后获取标签的词向量,并根据相似度找出了与之相关的关键词,再用关键词的word vector到样本的doc vector的相似度过滤出每个标签的文本。在这里,如何根据相似度获取标签的关键词和把文本划分到标签下需要建模,最简单的方式是设置阈值,当相似度大于某一阈值时,就把该词作为标签的关键词、把文本划到标签下。得到文本后就可以训练一个监督模型。最终用这种方式完成项目的收益分析。
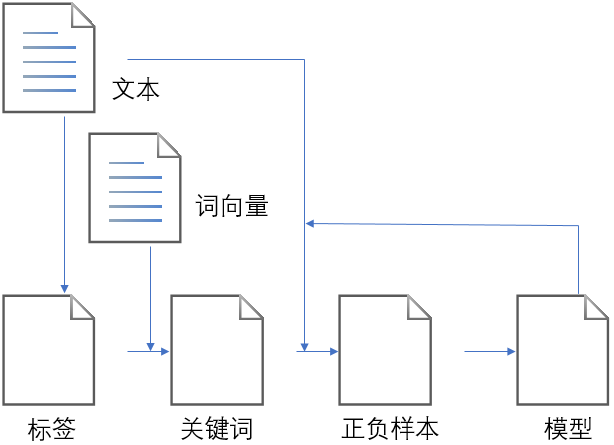

序列标注
在NLP中,序列标注时指对一段文本中的每段元素做标注,例如经典的中文分词和命名实体识别。在实际中,缺乏标注数据导致序列标注在很多问题上难以运用,特别是一些频繁出现的很小众且特殊的序列标注需求,为这些任务准备标注数据的代价更为高昂。遇到这种问题,在标注人员不能够马上跟进或者快速地提供一批高质量的标注样本的情况下,通过一些模板得到第一批标注数据对于整个任务得以开展是至关重要的。通过分析数据,首先可以从抽样数据中大致找到关注内容的表达方式,并分析出覆盖率最大的模板。其次,能够在文本中定位得到关注内容。再者,根据定位内容的上下文判断是否是关注内容,这个过程涉及到建模。最后,在训练集上调整模板、迭代定位算法和判断算法。
案例:
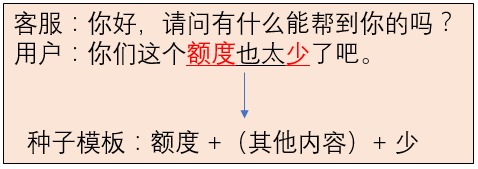
有一个用户满意度的提取任务,这个任务要求判断用户对服务是否满意,但是因为文本由语音转写而来,所以文本内容偏向于口语化。首先,从文本中获取模板,例如上面的例子,可以得到种子模板:“额度”+(其他内容)+“少”;其次,考虑到模板中的“额度”是最关键的要素,首先要定位到这个词;再者,由于缺少变化的模板往往难以应对真实的对话场景,因此我们用词向量拓展种子模板,例如,用户可能是说“额度少”,也有可能说“额度不高”;最后,根据定位点的前后若干个词组放入到模型中判断是否表示对额度不满,这个部分可以直接判断上下文是否满足模板,也可以把符合模板的样本作为正样本,反之为负样本,用这些样本训练模型,这样能得到泛化能力更好的模型。最终满足了项目的需要。
小结
本文分别从文本分类和序列标注介绍了我的一些工作,这其中没有使用奇妙的模型,是结合项目情况做出取舍后使用的工程方案。鉴于目前的认知,这其中必然存在一些缺陷。希望能够给大家一些启示,也希望大家能够与我分享更好的做法。
本文来自信也科技拍黑米,经授权后发布,本文观点不代表信也智慧金融研究院立场,转载请联系原作者。