
背景介绍
企业的营销活动是通过发现或发掘准消费者群体的需求,让消费者了解产品进而购买该产品的过程 [1]。在我司的营销业务场景中,营销人员和智能对话机器人通过和用户电话沟通,主要是向用户宣介产品特点,了解用户的使用意愿,协助用户解决困难、获取额度和成交,便最终达到了营销目的。
在营销中,最为引人关注的指标莫过于成交率了。这个指标不难理解,就是最终成交用户数和被营销总数的比值。聚焦到一个用户身上时,我们把他最终会成交的概率定义为“成交意愿度”;在一个群体上,用户成交意愿度均值和整体的成交率应该是一致的。成交意愿度是用户分群和后续营销策略的一个重要指标。
因此,在营销业务中一个潜在的问题是,是否可以根据一通对话的历史文本信息,辅以其它用户表征信息,通过模型预测用户的成交意愿度呢?虽然用户最终是否成交取决于多种因素,营销只是其中一个环节,但是如果营销对话内容中的信息能对用户的意愿度有一定的区分作用,那么就可以首先利用营销机器人初步筛选出有成交意向的用户,进而让营销客服人员二次跟进,通过人机结合的方式降本提效,产生实际的业务价值。
通过对营销对话历史语料分析发现,数据中的一些特征和成交意愿有明显的关联。比如对于一些成交意愿度低的用户,他们接通后首轮直接挂断比例较高,或者明确地作出了“不需要”这样的表达。另外,还有一些对建模有用的数据特征,比如在单轮对话中,用户平均说话时长较短,而客服人员平均说话时长较长。最后,数据也存在一些噪声,经过自动语音识别(Automatic Speech Recognition, ASR) 转换的对话历史文本数据可能有较多的错别字问题或者根本无法转写文本问题等。
下面我们就展开聊一下如何构建成交意愿度模型。在输入数据X (即对话历史信息和用户表征信息) 和成交标签y (y = 1表示成交;y = 0表示未成交) 的基础上,我们就可以借助于自然语言处理 (Natural Language Processing, NLP) 技术和机器学习模型对X和y建模,达到预测用户成交意愿度的目标。
在此之前,我们首先回顾一下NLP中的一些模型和相关特点。
模型构建
编码器
自从2012年AlexNet模型获得ImageNet挑战赛冠军后 [2],深度学习 (Deep learning) 再次得到广泛关注。与传统统计机器学习 (Statistical machine learning) 相比,深度学习可以自动提取特征,避免了人工的耗时耗力的特征工程。
在NLP领域中,一个通用的模型架构是编码器 (Encoder) – 解码器 (Decoder)结构[3],即编码器处理输入 (文本) 序列,将输入文本编码成稠密向量作为输入的特征表示;解码器接收到编码器的输出,通过不同的解码方式完成各种下游任务,比如文本分类,序列标注和机器翻译等。值得注意的是,为了达到更好的预测效果,解码器一般都会结合使用注意力机制 (Attention mechanism)[4]。
常用的编码器有CNN (Convolutional neural network, 卷积神经网络) [2] (关于在相关业务的应用请参考深度学习在篇章级文本分类中的应用 [5]),RNN (Recurrent neural network, 循环神经网络) [6] 和Transformer [7] 等。因篇幅限制,在这里就不展开介绍每个模型的细节部分,而着重于比较一下它们之间的区别与联系。
1)计算并行度
CNN的多卷积核 (Filter) 和Transformer的多头 (Multi-head) 结构是天然支持并行运算的;而在RNN中,当前时刻的输入依赖于上一时刻的输出,因此只能每个时刻依次串行运算。值得注意的是,最近几年也有学者提出RNN的并行加速变体模型,如Simple Recurrent Units [8] 和 Sliced RNNs [9] 等。
2)长距离依赖
CNN的卷积核只考虑了窗口内的单词依赖信息,为了建模长距离依赖,一种简单做法是加大卷积层数,也有模型变体如Dilated CNNs [10] 来解决此问题。虽然有LSTM (Long short-term memory) [6] 和 GRU (Gated recurrent unit) [11] 等变体的提出,RNN模型也会受限于序列太长的问题。受益于自注意力 (Self-attention)机制,Transformer 模型可以建模序列中任意两个单词的依赖关系。
3)位置信息
对于NLP来说,词语位置信息扮演着重要角色。举例来说,在实际中出现“我吃了香蕉”这句话的概率,远远大于出现“香蕉吃了我”的概率的。RNN的模型结构天然考虑了单词的位置信息。CNN的每个卷积核内只考虑了窗口内的相对词序信息,但是后续池化 (Pooling) 操作会将词序信息丢失。为了显式表示词序信息,Transformer加入了位置编码 (Positional encoding)。
上述部分在三个角度详细地比较了不同的编码器网络结构,那如何有效地利用它们构建营销成交意愿度模型呢?
模型结构
简单回顾一下,模型的输入 X 由两部分组成,即对话历史信息 (文本数据) 和用户表征信息 (结构化数据),考虑到二者属于不同的特征空间,因此在模型设计阶段,采取分别单独处理后再合并的策略,如下图所示:
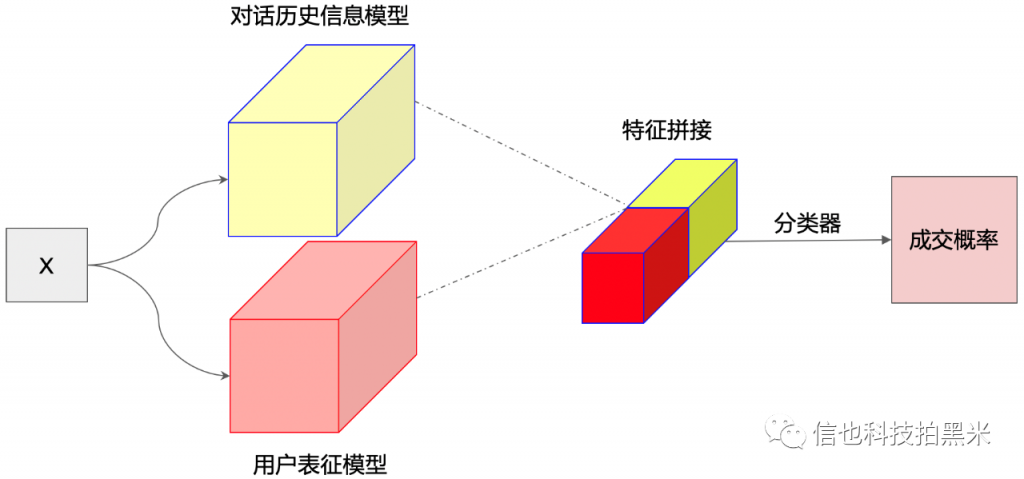

首先我们来设计对话历史信息模型。如何高效地利用对话历史信息呢,一个最简单直接的做法是将每轮对话直接拼接成一个长文本,然后直接使用上一部分介绍的任意编码器 (即CNN,RNN和Transformer) 进行编码,显然这样做并没有把轮次信息考虑进去。轮次信息在一通对话中起着重要作用,因为通常在交谈中,随着对话的推进 (轮次的增加),谈话主题 (Topic) 会发生变化。除了轮次信息之外,模型也需要考虑角色信息 (即区分对话中的两个角色),那么接下来的问题是,如何显式地对轮次信息和角色信息进行编码呢?
记忆网络 (Memory network) 可以对对话上下文 (Contextual) 信息进行有效存储[12]。文献 [13] 提出使用一个RNN建模单轮信息,另外一个RNN建模轮次信息的策略 (同时也隐式地考虑了角色信息),并提出加入记忆模块 (Memory module)。考虑到线上实际对话数据的特点,我们提出以下两个模型结构:
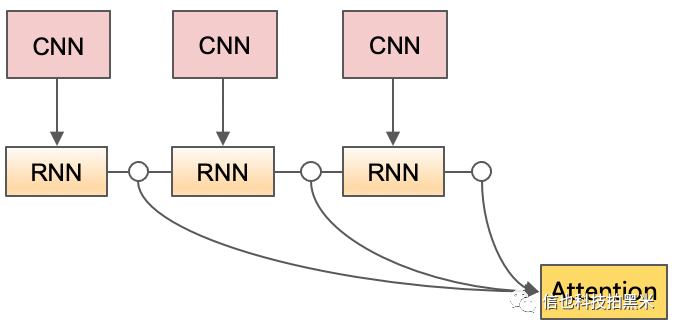
该模型结构使用CNN建模单轮信息 (隐式地考虑了角色信息),RNN建模多轮信息,最后使用注意力机制让模型自动选择显著的关键信息。
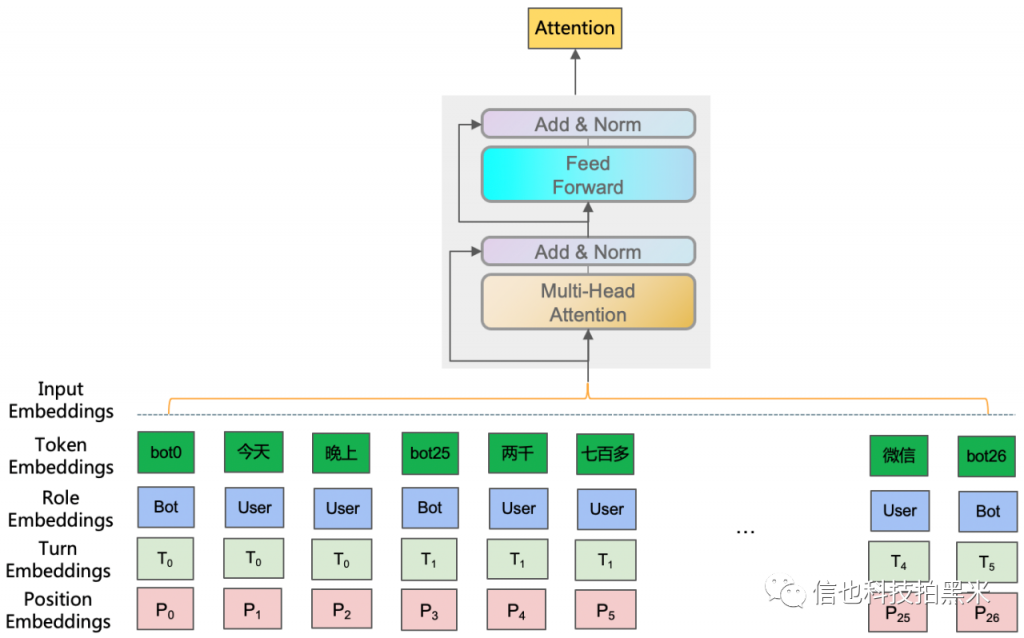
该模型结构输入部分显式地考虑了轮次信息 (Turn Embeddings) 和角色信息 (Role Embeddings),中间使用Transformer进行编码,同样的,最后使用注意力机制让模型自动选择显著的关键信息。
对于用户表征模型,这里直接使用多层感知器 (Multilayer perceptron) 进行编码。同时由于ASR错误问题,我们对对话历史输入进行了简单的纠错和同义词替换等预处理操作。
实验结果
为了验证模型效果,我们在线下测试阶段选取了一段时间内的实际对话历史和对应是否成交标签作为验证数据,结果如下图所示:
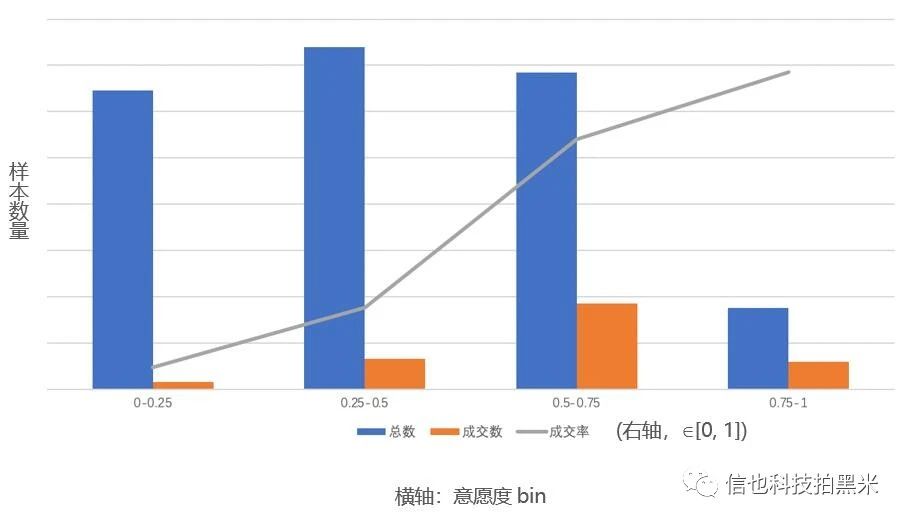
上图将预测的成交意愿度分划分在四个bin中 (即 [0, 0.25), [0.25, 0.5), [0.5, 0.75), [0.75, 1]),每个bin内包含对应的样本总数和成交数,使用成交数除以样本总数便可得到该bin中样本的平均成交率。可以发现,实际成交率和预测的成交意愿度在bin维度上是有很好的正相关关系的。不过意愿度分和成交率的数值上还是存在明显偏差。
借由预测的成交意愿度,营销策略中设置了人机结合组。由机器人先期接触用户并判断用户的成交意愿,随后,由人工坐席跟进意愿度高的用户组。近期的线上业务指标表明,我们的人机结合组表现已经非常接近人工坐席组了, 基本达成了预设的目标。这充分证明在营销业务上,人工智能已经发挥了强大的作用。
总结
本文首先介绍了营销对话预测成交意愿度的业务背景,接着详细介绍了营销成交意愿度预测模型的构建方法和实验结果,线下测试和实际线上业务指标表明该模型在区分用户成交意愿度方面有着良好表现。
与此同时,人工客服人员与用户的通话积累了大量的对话数据,我们也在分析优秀经办与用户对话历史,通过无监督聚类等方法进行优秀话术提取和对话流程构建等,充分挖掘对话历史数据的潜在价值,不断优化升级贷前营销场景和贷后催收场景外呼机器人。
在自然语言处理领域,基于海量数据和强大算力支持,一些大厂不断刷新着SOTA成绩 (如 GPT-3 [14] 等),同时在学术界也不断涌现出fancy的模型架构和技巧。在保持追随的过程中,我们要不断思考如何借助先进的技术手段助力业务场景落地并产生价值。
本文来自信也科技拍黑米,经授权后发布,本文观点不代表信也智慧金融研究院立场,转载请联系原作者。