
说起人工智能,你恐怕已经没有太大的好奇心了。谁都听说过深度学习,知道“AlphaGo战胜了李世乭”,甚至还有更早的“IBM Watson赢得了美国著名的Jeopardy答题秀”;每天打开朋友圈、微博、头条、抖音的时候,到处都可以看到AI话题的内容,让你知道了无人驾驶、机器人自动接打电话、智能音箱辅导小孩写作业、以及对着摄像头被机器人面试这些AI应用,并试图说服你相信这些都是在不久的将来,每个人居家旅行、杀人越货之必备神器。你看完文章后的内心想法通常是:“都是吹牛的,真搞定了再来找我吧!”,然后扔下了手机。Yes,you are (almost) right!AI领域还是充满了各种不确定性。但是,话又说回来,AI虽不完全靠谱,我们还是可以在一个限定的条件下,让AI能够靠谱地发挥它的能力。
让我们来到互联网金融行业,并具体到借贷场景下,实际上AI算法已经落地的例子也不少,例如TARS机里的图像识别反欺诈,复杂网络的团案识别,或者是借款APP里的智能客服。AI技术可以助力大数据风控、智能营销 、智能运营等许多业务线,有的甚至成为业务们依赖的主力。所以,当你去拥抱AI技术,并仔细思考了5分钟之后,一定就发现这样一个规律:所谓的“智能”,通常就是以数据为依据的个性化计算。这次你真的说对了!
那么我们就此进入正题吧!今天要聊的话题是我们如何用自然语言处理(NLP)技术,为业务(特别是信贷场景)提供文本特征服务的。下边将通过一些生动的(但不一定是实际业务的)例子,形象地了解到我们的NLP特征抽取算法体系。
文本特征抽取是干什么的
首先,需要弄清楚数据是什么。在大数据时代,网络是有记忆的,人们的许多行为活动都是有记录的。我们可以利用公开的或者是授权的用户数据,分析出反映一个(或一群)人的某些行为特征。举一个简单的例子:从一个用户发表的微博,可以清晰地看到用户的兴趣爱好、所在城市、生活规律等等。假设你是一个化妆品推销员,如果你知道了哪个地方有更多女性或者有很多人经常举行派对,那你今天是不是就有目的地了?
用户的数据有很多种,视频、留下的微博文字,等等。NLP技术会更专注在一个领域的数据,那就是文本数据,包括一部分语音,可以通过ASR技术将语音转写成文本。文本数据的一个最大特点是什么呢?——非结构化。换句话说,机器能读懂程序猿写的代码语言,以及商业分析师小哥哥小姐姐写的SQL脚本语言,但并不能理解人随意写下的文字,即使这些文字多么文辞优美而没有任何语法错误。要让机器能处理文本,就需要将人类用来沟通的语言文字,转换成机器能够读懂的结构化数据,甚至是数字。而NLP技术的核心价值,就是通过一系列的算法,来实现非结构化文本的处理,在下边我们再做展开。
有了文本数据作为输入之后,我们便关心到底是要从中获得哪些特征。顾名思义,特征是指“独特的表现”,它对应的英文“feature”的本义,是指 (眼, 口, 鼻等)脸的一部分,引申为相貌。这样就很明白了吧,我们要找的是能衬托某人“相貌”上的特殊点,当然这个相貌是虚指,就是一个人区别于他人的地方。实际上,这些特征的集合已经有一个众所周知的名字,那就是用户画像。实际上,基于业务的需要,我们归纳了四类比重高且重要的特征类型:
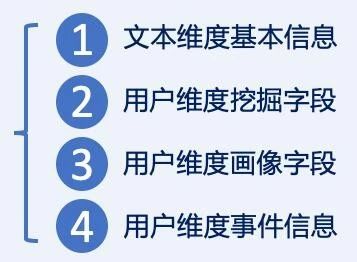

下面将从文本和用户两个维度来分别分析一下:
文本维度的基本特征抽取
首先,有一种用于文本的“古老”但又实用的特征标注方法——序列标注法。这种方法可以把我们对文本中感兴趣的内容加以标注。还是以一个实际的例子来做说明,我从微博上随机找了一句话:
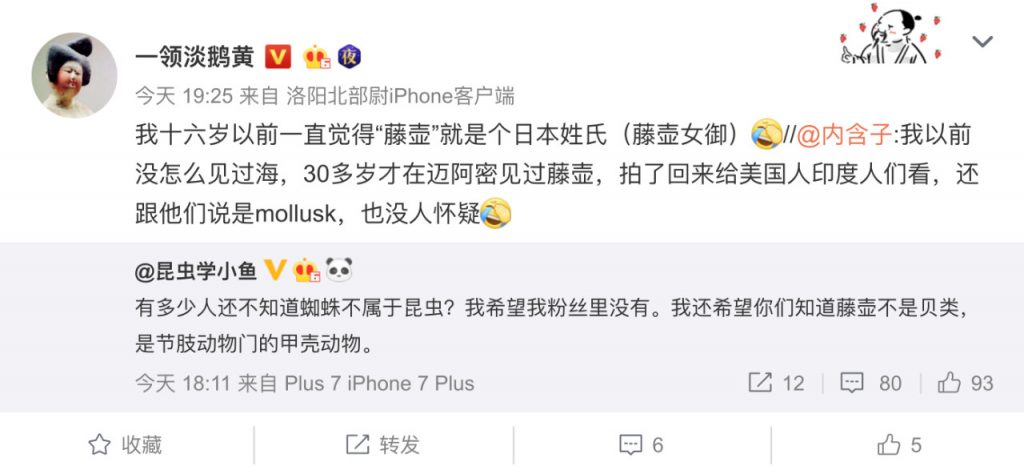
让我们来看第一句话,去掉标点后,它的一个序列标注结果就是如下这样:

句子中被标出来的标签有:num(数字)、age(年龄)、bio(生物)、loc(位置)、per(名、姓)。B-xxx和I-xxx分别代表xxx标签的开头和后续。各标记可以有重叠,但通常最终的标注结果就是如下的没有相互交叠的一个标注序列:

大家一定会觉得这种方法挺土的,不过它确实非常有效,对特定业务来说,可以非常快速地建立起相应的标签,而人工要做的是去梳理相关的词典和基于词典的规则,比如实际业务中,对银行卡账户的抽取,采用规则(部分)就像这样:

其中的num(数字)是由一大堆正则表达式构成的中英文数字抽取,卡还有前缀和后缀分别由一些固定的词汇来定义,而卡号最终就由rule_bankcard这样一条规则来给出,这些规则一般都可以通过Trie树结果存储和执行。
前边例子中,可以注意到同一个词“藤壶”,分别可能出bio和per两种标注。在实际应用中,我们可以用多种方法来解决这个问题:1)在特殊的领域,自定义特定的词典,通常只有其中一个标签会被识别到;2)可以用序列标注算法,比如经典的CRF(条件随机场)算法,不过这就需要有足够多的标注数据。
大家会问,是不是可以有点更厉害的算法?是的,深度学习用来做序列标注也是极其成功,BiLSTM-CRF超过了比传统的最优结果CRF的结果,而后声名大震的BERT则是更胜一筹,我们也用的BERT-NER的一个中文版的实现,在小样本上进行加强后,就可以很准确地识别我们需要的人名、地名、机构名。以下面两条新闻为例:


BERT-NER给出的实体名特征识别结果分别为:
{‘org’: [‘信也科技集团’, ‘NYSE: FINV’, ‘印度尼西亚金融服务管理局’, ‘印尼金管局’], ‘loc’: [‘印度尼西亚’]},
{‘org’: [‘拍拍贷’], ‘per’: [‘张俊’]}]
而我们在实际的工程中,并不拘泥于某一种算法,而是将传统规则、模型和深度学习的结果都融合在一起,给业务以及我们研发自身一个工作的基础,用这些抽取出来的标记特征,去进一步构造更复杂的业务变量。
因此,文本维度的特征抽取就可以简单地理解为在抽取文本中的最底层的特征,它和什么分词、词性标注、以及词向量等一起,构成了后面做复杂文本任务的一个基础,而这一块当然是比较贴近业务本身的,从上边的自定义规则就可以看出来。
用户维度的特征抽取
我们再来更深入一点了解下,如何从基础的文本特征构造用户维度的特征。
首先来看用户维度的特征挖掘。从数据的结构上来看,一般一个用户会有很多关联的文本,因此需要考虑如何将文本特征最终对应到一个用户身上。从这个角度来讲,文本特征是结构化的,而且不同特征之间甚至都有严格的层级和组织关系。所以,通过文本一些特征的组合和再训练,可以得到更为上层的信息,比如一个人是“A:平时只出现在公司和小区”,以及“B:经常点外卖”,那么我们就可以给他加上一个“C:宅男”的标签。同时,这里也会用到比较多的文本聚类和序列挖掘算法,比如可以用最大公共子序列来发现文本中的常见的pattern。在业务中,我们用这些方法对用户的行为特征加以分析,可以对用户的风险控制和额度管理都提供很好的帮助。
用户画像可以用来描述一个人的个人属性、行为特征、社会属性。通常一个用户的特征可以由一些文本的特征组合起来构成。常见的做法是通过人工标注,然后用文本分类方法进行训练,这部分在之前的拍黑米文章中已经介绍过,这里就不再赘述。
最后要再提一下用户事件抽取。事件其实是一类特殊的知识,通过抽取文本中的一些基本的事件要素(时间、地点、人物、事由),来构成一个事件的最基本信息。从比较专业的事件抽取来看,主要由事件发现和论元抽取组成。一般是句子先通过事件的触发词(很多是句子的predicate,即谓词)识别,随之确定事件的类型,再抽取和跟它相关的论元(argument,即相关的时间、地点、参与者等等),这些任务一般都是基于标注和监督学习的方法来实现的,其中不乏大量深度学习的模型。举一个例子说明:“ 11月5日,上海拍拍贷金融信息服务有限公司(以下简称为“拍拍贷”)更名为 ‘信也科技’ ”。这里抽取出的基本特征包括:’data’: [’11月5日’], ‘org’: [‘上海拍拍贷金融信息服务有限公司’, ‘拍拍贷’, ‘信也科技’],以及重要的事件触发词”更名”。就构成了一个事件的基本要素,我们主要以专家规则的形式进行抽取,得到一个企业相关的重大事件:
{‘data’: ’11月5日’,
‘subject’: ‘上海拍拍贷金融信息服务有限公司’,
‘event’: ‘更名’
‘object’:’信也科技’}
抽取得到的事件数据是一种结构化的数据,具有时序性,又有和其它事件的关联,也可以和知识图谱相结合,进行事件的推理等等。我们在后续的拍黑米中会持续更新。
小结
从上边的叙述大家不难看出,文本特征抽取和应用是一个很复杂的工程,而我们也仅仅是为公司业务需要,定制开发(或采用开源的方案)构造了一套可用的工程。这些功能还会随着业务的变更,以及我们出于自身对技术前沿的探索、对更高技术指标的追求,而不断迭代更新。希望大家能从上述的文字中能有点滴收获,并将改进的建议反馈给我们,以促进我们的能力得到更好更快的提高~
本文来自信也科技拍黑米,经授权后发布,本文观点不代表信也智慧金融研究院立场,转载请联系原作者。