
前言
Waterdrop 是一个模型服务管理平台,它有以下功能:
- 自动服务化: 自动将模型代码封装为 API 服务
- 容器服务: 使用 Docker 镜像封装环境依赖与模型服务代码,支持主流的容器编排工具 Swarm / Kubernetes
- 反向代理: 支持在同一个域名下,使用不同的 endpoint 来调用不同模型服务的不同版本
- 服务发现: 当模型服务进行迭代时,模型调用方不必重新发版来调用新 URL
- 弹性伸缩: 根据模型服务的 Worker 繁忙率等指标,自动对模型服务进行扩容或缩容
- …
本文主要介绍 Waterdrop 的弹性伸缩功能。
为什么要做弹性伸缩
当访问量激增时,传统的服务扩容流程非常繁琐且耗时,需要经历设备申请、装机上架、依赖安装、服务部署、健康检查、流量切换等过程,每一步都需要人工去干预,时间成本较高,且在这期间,服务将持续处于不健康甚至不可用的状态,而服务不健康甚至不可用意味着…
而当业务高峰过后,还需要及时进行缩容,否则会造成不必要的资源浪费,缩容时则需要经历一遍相反但同样繁琐且耗时的流程。
因此,弹性伸缩功能就必不可少了。
弹性伸缩的实现 – 确定监控指标
要实现弹性伸缩,首先需要确定,我们要根据哪个或哪些指标来判断应用服务是否需要扩容或者缩容。
我们首先想到的指标是应用服务的 QPS,直接根据应用服务的 QPS 来判断是否需要伸缩容岂不是美滋滋,那么问题来了:
- 不同应用服务能承受的并发量不一致:比如,在拥有同样的副本数的情况下,服务A承受100的 QPS 毫无压力,服务B承受10的 QPS 可能就 GG 了,这就意味着,每次新上一个服务,都要对这个服务进行一遍完整的压测,以确定弹性伸缩时的 QPS 阀值
- 无法根据 QPS 来确定目标副本数:比如,服务A在副本数为2的情况下,能承受的 QPS 阀值为10,而假设现在 QPS 突增到了20,服务A的副本数扩容到多少合适?扩容到4个就一定能承受住20的 QPS 么
然后我们想到了使用应用服务的响应时间等等来作为指标,发现问题和 QPS 类似。
最后,我们决定使用 CPU 利用率、内存利用率和 uwsgi 的 worker 繁忙率来作为供弹性伸缩使用的监控指标。
弹性伸缩的实现 – 指标采集方式
确定了供弹性伸缩使用的监控指标后,我们需要确定指标采集方式,而这又可以拆分为两个部分:
- 如何获取指标
- 如何存储指标
经过调研之后,我们采用了uwsgi-stats + uwsgi-exporter sidecar + prometheus-operator 的技术栈来获取和存储指标。
架构图如下:
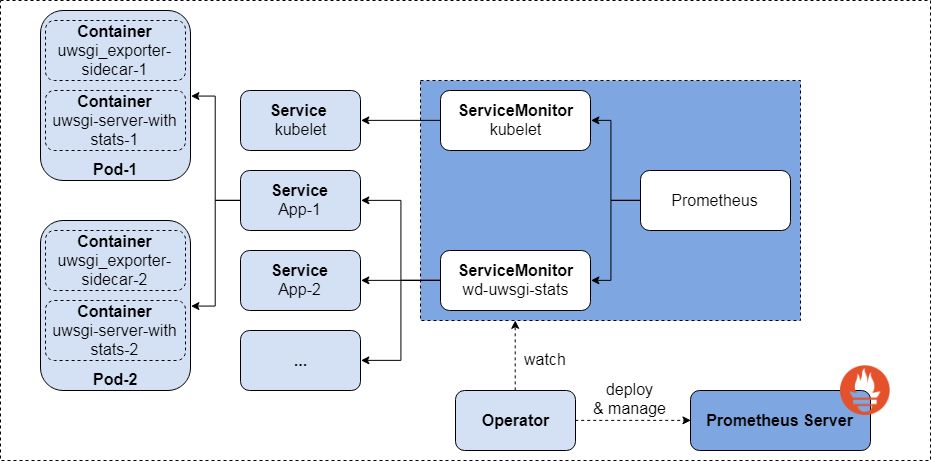

获取 CPU 使用率和内存使用率
首先是 CPU 使用率和内存使用率。
我们在安装了 prometheus-operator 之后,会自动建立一个名为`kubelet`的 ServiceMonitor(ServiceMonitor 为 prometheus-operator 创建的自定义资源定义,通过 Selector 来依据 Labels 选取对应的 Service 的 endpoints,并让 Prometheus Server 通过 Service 进行拉取指标),它监控位于 kube-system 命名空间的名为`kubelet`的 Service,可以采集到各个 pod 和各个 container 的 CPU 和内存使用情况,再通过简单的计算就可以得到各个应用服务的 CPU 使用率和内存使用率。
> CPU 使用率示例

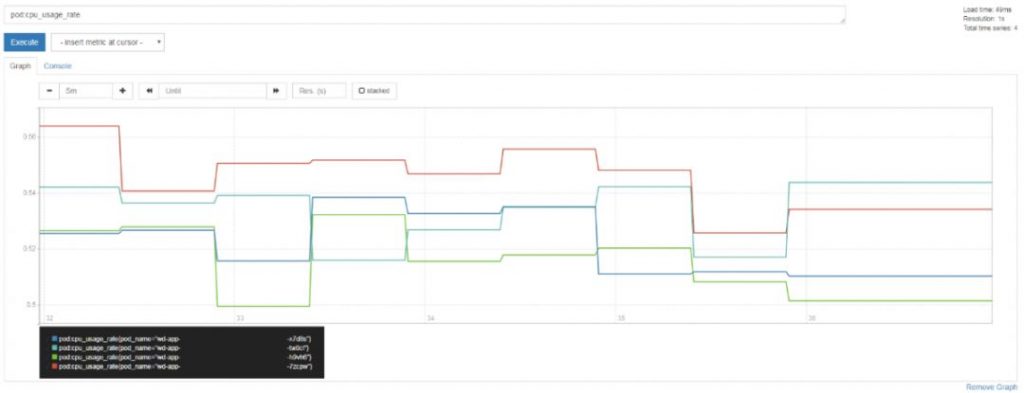
> 内存使用率示例


获取 uwsgi 的 worker 繁忙率
uwsgi 启动时,在启动命令中可以添加`–stats`相关参数,就可以将 uwsgi 运行过程中的指标 – 如是否正常运行、worker 是否繁忙等信息暴露出来,格式为 json,再通过在 pod 中放入 uwsgi-exporter 这一 sidecar 来将 json 格式的 stats 转换为 Prometheus 需要的格式,并以接口的形式暴露出来,再建一个 ServiceMonitor ,就可以将 worker 繁忙信息存储到 Prometheus 中,通过简单的计算就可以得到各个应用服务的 worker 繁忙率。
>Worker 繁忙率示例

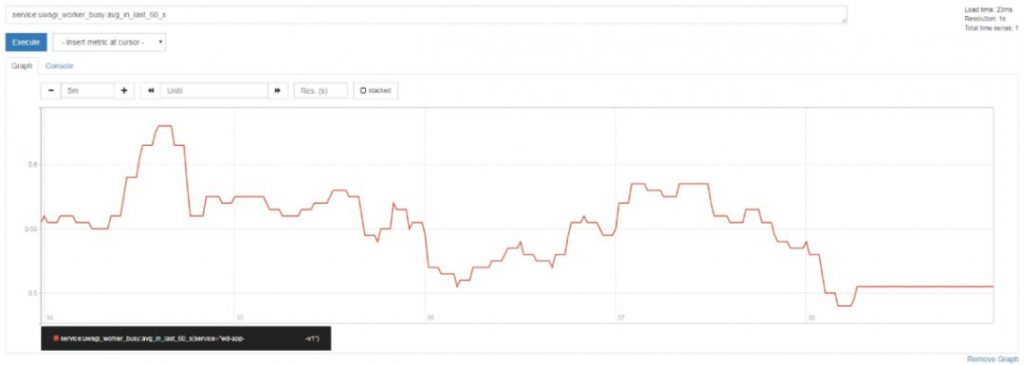
弹性伸缩的实现 – 告警触发流程
将我们需要的指标信息存储到 Prometheus 这个时序型数据库中之后,我们就可以定期检查这些指标的情况,并设置阀值,当指标达到阀值时触发告警,通知 Waterdrop,这样,Waterdrop 就可以调用 Kubernetes API 来对服务进行伸缩了。
> 比如,我们设定了一条规则,定时检查模型服务A近30s内的 worker 繁忙率的平均值,当 worker 繁忙率大于75%或小于25%时触发告警,然后设定了模型服务A的目标 worker 繁忙率是50%。
> 假设在某个时刻,模型服务A近30s内的 worker 繁忙率平均值突增到了80%,触发了 Prometheus 的告警,并通知到了 Waterdrop,Waterdrop 根据告警信息中的 service_id 找到了这个模型服务,并找到了它的目标繁忙率为50%,当前副本数为2,经过简单的计算得到目标副本数为4,于是调用 Kubernetes API,将副本数调增至为4。
当然,实际的配置相比上面这条示例会稍微复杂一些,比如需要考虑告警阀值的计算、弹性伸缩时的容忍值、两次伸缩之间的冷却时间等。
弹性伸缩的实现 – 示例
该示例中,以 worker 繁忙率为弹性伸缩指标,目标 worker 繁忙率为50%。
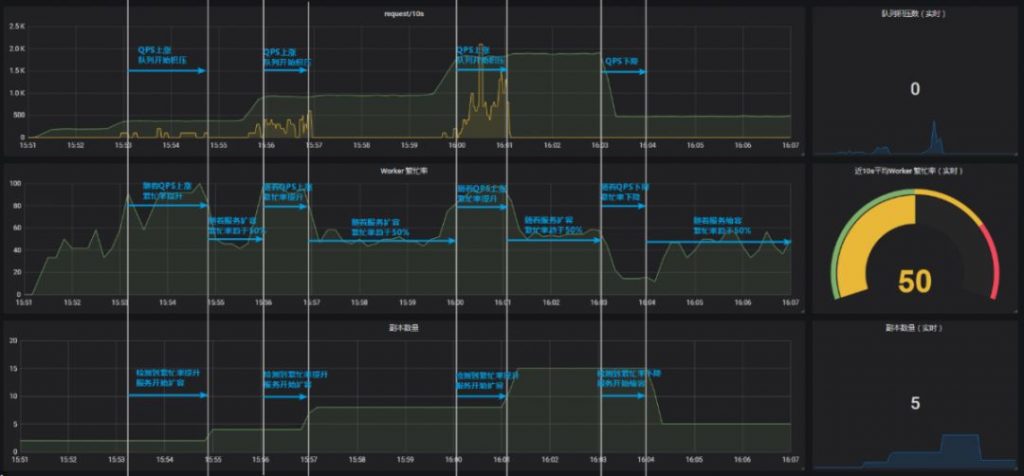
- 第一阶段,QPS 为20,副本数为2,繁忙率稳定在50%左右,不做伸缩。
- 第二阶段,QPS 由20暴涨至40,副本数为2的情况下,繁忙率上涨,远高于50%,触发告警,服务副本数由2自动扩容至4,随后,繁忙率再次稳定在50%左右。
- 第三阶段,QPS 由40暴涨至80,副本数为4的情况下,繁忙率上涨,远高于50%,触发告警,服务副本数由4自动扩容至8,随后,繁忙率再次稳定在50%左右。
- 第四阶段,QPS 由80暴涨至160,副本数为8的情况下,繁忙率上涨,远高于50%,触发告警,服务副本数由8自动扩容至16,随后,繁忙率再次稳定在50%左右。
- 第五阶段,QPS 由160下降至50,副本数为16的情况下,繁忙率下降,远低于50%,触发告警,服务副本数由16自动缩容至5,随后,繁忙率再次稳定在50%左右。
本文来自信也科技拍黑米,经授权后发布,本文观点不代表信也智慧金融研究院立场,转载请联系原作者。