
背景介绍:
人脸检测,解决两个问题:1)识别图片中有没有人脸?2)如果有,人脸在哪?因此,许多人脸应用(人脸识别、面向分析)的基础是人脸检测。
大多数人脸检测采用的流程为两阶段:
1) 找出所有可能是人脸的候选区域
2) 从候选区域中选择出最可能是人脸的区域
本文的主角MTCNN,大致是这种套路,也集成了其优缺点为:准和慢。
MTCNN人脸检测是2016年的论文提出来的,MTCNN的“MT”是指多任务学习(Multi-Task),在同一个任务中同时学习”识别人脸“、”边框回归“、”人脸关键点识别“。相比2015年的CVPR(边框调整和识别人脸分开做)的结构,MTCNN是有创新的。从工程实践上,MTCNN是一种检测速度和准确率都还不错的算法,算法的推断流程有一定的启发性,在这里给大家分享。(以下用“MTCNN”代指这个算法)
本文以Q&A的方式,与你分享一些经验和思考。先列出本文会回答的问题列表:
- MTCNN的推断流程第一阶段:1.1 为什么需要对图片做“金字塔”变换?1.2 MTCNN算法可以接受任意尺度的图片,为什么?1.3 设置合适的最小人脸尺寸和缩放因子为什么可以优化计算效率?缩放因子为什么官方选择0.709?1.4 为什么把图片输入模型的时候要对每个元素做(x – 127.5)/128的操作?1.5 P-NET网络的输出怎么还原成原图上人脸区域坐标?
- 什么叫边框回归?在MTCNN怎么利用边框回归的结果?为什么可以这样做?
- 哪些步骤是影响MTCNN的计算效率的关键?以及有哪些优化思路?
本文参考的代码是David Sandberg的复现,
https://github.com/davidsandberg/facenet/blob/master/src/align/detect_face.py,该复现是github上MTCNN的复现中星星最多,实现得最像原作的版本。代码中包含着大量的Magic Number,初读,令人不知所云。本文通过回答以上的问题,一点点参透它们。
MTCNN的推断流程第一阶段的一系列问题
第一阶段的目标是生成人脸候选框。MTCNN推断流程的第一阶段,蕴含了许多CNN的技巧,个人认为是比较精华也具有启发性的部分。并且MTCNN的推断过程中,第一阶段时间消耗占80%左右,所以如果需要优化和理解MTCNN的读者,在第一阶段投入再多精力都不为过。
1.1 为什么需要对图片做“金字塔”变换?
由于各种原因,图片中的人脸的尺度有大有小,让识别算法不被目标尺度影响一直是挑战;目标检测本质上来说上目标区域内特征与模板权重的点乘操作;那么如果模板尺度与目标尺度匹配,自然会有很高的检测效果。更多详尽的应对方案总结见MTCNN的这篇文章(https://arxiv.org/pdf/1606.03473.pdf)。
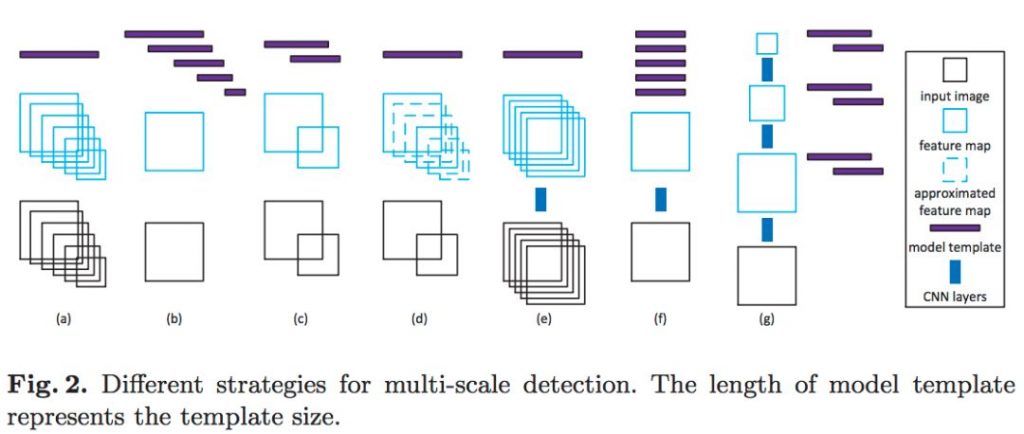

MTCNN使用了上图的(a)图像金字塔来解决目标多尺度问题,即把原图按照一定的比例(如0.5),多次等比缩放得到多尺度的图片,很像个金字塔(如上图a)。
P-NET的模型是用单尺度(12*12)的图片训练出来的,推断的时候,想要识别各种尺度的人脸更准,需要把待识别的人脸的尺度先变化到接近模型尺度(12*12)。
缺点就是:慢。第一,生成图片金字塔慢;第二,每种尺度的图片都需要输入进模型,相当于执行了多次的模型推断流程。
1.2 MTCNN算法可以接受任意尺度的图片,为什么?
因为第一阶段的P-NET是一个
全卷积网络(Fully Convolutional Networks)
(https://arxiv.org/abs/1411.4038)。
卷积、池化、非线性激活都是一些可以接受任意尺度矩阵的运算,但全连接运算是需要规定输入。如果网络中有全连接层,则输入的图片尺度(一般)需固定;如果没有全连接层,图片尺度可以是任意的。
当然也有既包含全连接层也能接受任意尺度图片的结构:Kaiming He等提出的SPP(Spatial Pyramid Pooling,空间金字塔池化)就是做这个的(https://arxiv.org/abs/1406.4729)。本文不作过多说明。
1.3 设置合适的最小人脸尺寸和缩放因子为什么可以优化计算效率?缩放因子为什么官方选择0.709?
minsize是指你认为图片中需要识别的人脸的最小尺寸(单位:px)。factor是指每次对边缩放的倍数。
我们已经知道,第一阶段会多次缩放原图得到图片金字塔,目的是为了让缩放后图片中的人脸与P-NET训练时候的图片尺度(12px * 12px)接近。怎么实现呢?先把原图等比缩放`12/minsize`,再按缩放因子`factor`(例如0.5)用上一次的缩放结果不断缩放,直至最短边小于或等于12。根据上述算法,minsize越大,生成的“金字塔”层数越少,resize和pnet的计算量越小。
这里以一个例子说明:如果待测图片1200px*1200px,想要让缩放后的尺寸接近模型训练图片的尺度(12px*12px)。
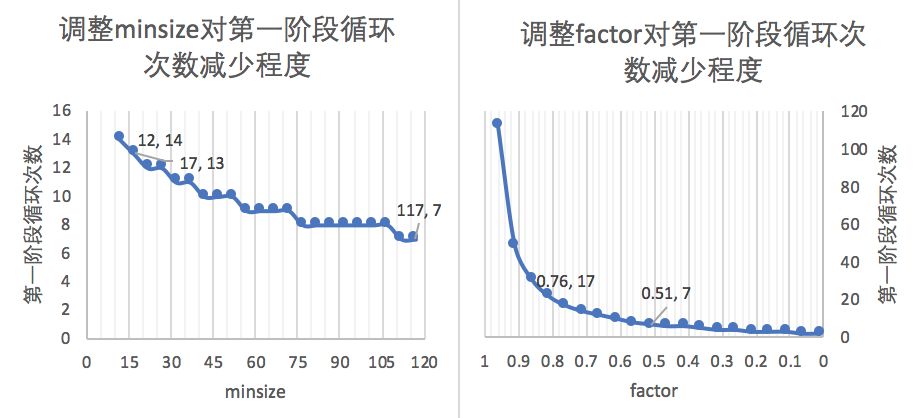
为什么缩放因子factor官方选择0.709?图片金字塔缩放时,默认把宽,高都变为原来的1/2,缩放后面积变为原来的1/4;如果认为1/4的缩放幅度太大,你会怎么办?把面积缩放为原来的1/2。对的,这是很直观的想法,所以这里的缩放因子0.709 ≈ sqrt(2)/2,这样宽高变为原来的sqrt(2)/2,面积就变为原来的1/2。并且从比MTCNN更早提出的级联人脸检测CVPR2015_cascade CNN(http://users.eecs.northwestern.edu/~xsh835/assets/cvpr2015_cascnn.pdf)的实现中也能找到端倪。
从实际意义上看,factor应该设置为小于1,数值越大第一阶段计算量越大,但可能找出更多的候选框。
1.4 为什么把图片输入模型的时候要对每个像素做(x – 127.5)/128的操作?
归一化操作,加快收敛速度。
由于图片每个像素点上是[0, 255]的数,都是非负数,对每个像素点做(x – 127.5)/128,可以把[0, 255]映射为(-1, 1)。具体的理论原因可以自行搜索,但实践中发现,有正有负的输入,收敛速度更快。训练时候输入的图片需要先做这样的预处理,推断的时候也需要做这样的预处理才行。
1.5 P-NET网络的输出怎么还原出原图上人脸区域坐标?
这时需要看下P-NET的网络结构:
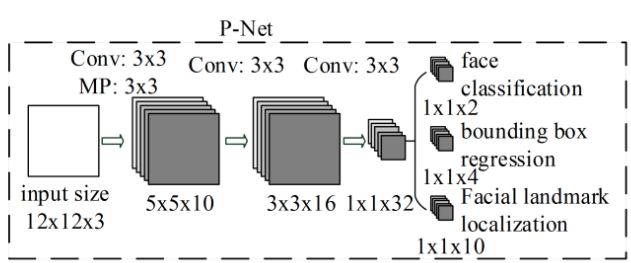
注意观察上图的特点:
- 3次卷积和1次池化操作后,原来12*12*3的矩阵变为1*1*32
- 利用这个1*1*32的向量,再通过一个1*1*2的卷积,得到了”是否是人脸”的分类结果(我们先聚焦于分类任务)
总结起来就是,输入一个12*12*3的区域到P-NET网络,可以输出“有人脸”的概率。
再联系卷积、池化操作是在输入的矩阵上滑动的特性。(见下图)
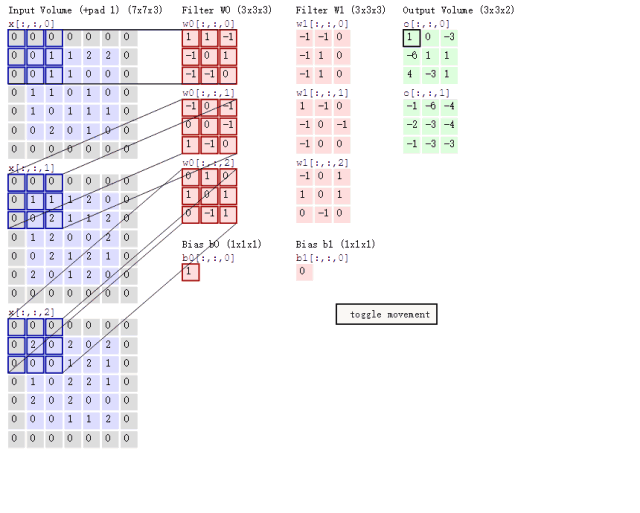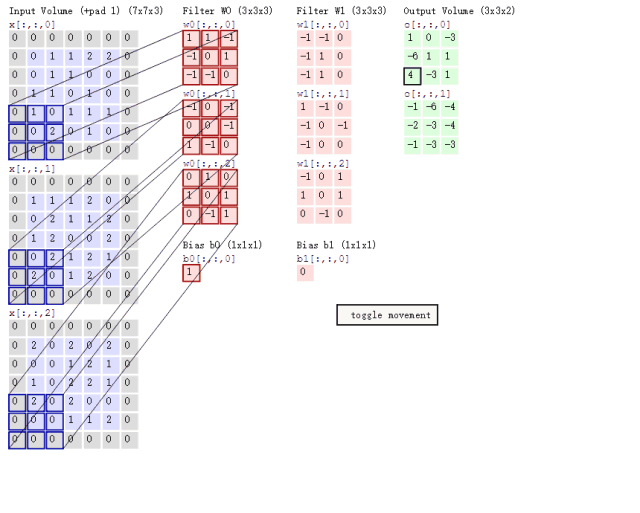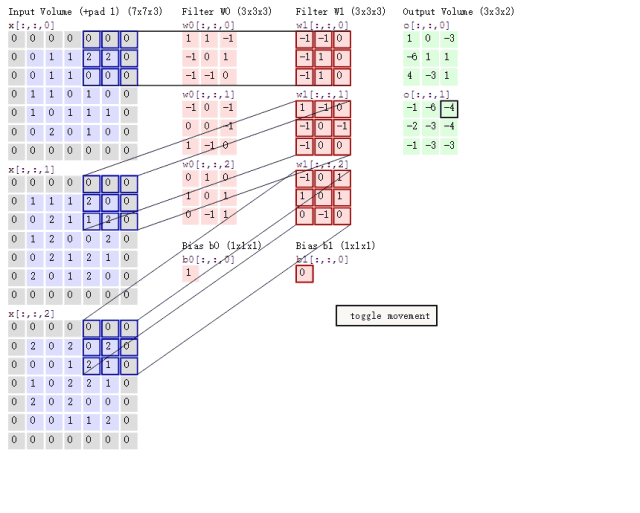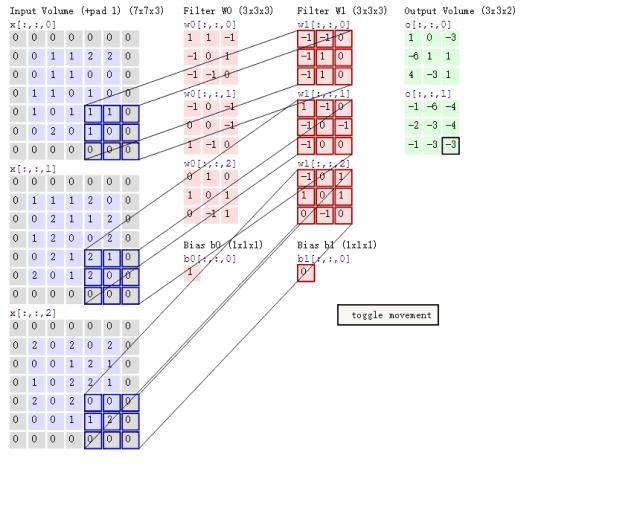
可以联想到下面这样的场景,我们令输入图片矩阵为A,卷积核在原图矩阵A上滑动,把每个12*12*3区域的矩阵都计算成该区域有无人脸的得分,最后可以得到一个二维矩阵为S,S每个元素的值是[0, 1]的数,代表有人脸的概率。即A通过一系列矩阵运算,变化到S。
根据P-NET的网络结构,我们可以计算输入矩阵A上一个左上角坐标(X, Y)、宽和高都是12的区域,经过P-NET的卷积和池化操作,对应于了S上的(X/2 – 5 , Y/2 – 5)。反过来,就可以把S的得分信息,还原成输入图片的各区域有无人脸,伪代码是:
令:
(x1, y1),(x2, y2)分别是输入矩阵中一个矩形区域的左上角和右下角坐标
(x, y, s)中(x,y)是得分矩阵上任意一点坐标,s是这个坐标上的值,表示有人脸的概率。
x1 = x * 2
y1 = y * 2
x2 = x1 + 12
y2 = y1 + 12
这样我们就得到输入矩阵A上的一个区域有人脸的概率。由于输入矩阵A是通过原图缩放scale倍得到的,还原到原图上就是
x1_origin = x1 / scale
y1_origin = y1 / scale
x2_origin = x2 / scale
y2_origin = y2 / scale
至此,我们就解释清楚如何根据P-NET的输出S,还原到原图上的各区域上有人脸的概率。
当然,一方面我们可以通过切threshold,过滤一些得分低的区域;另一方面可以通过NMS算法,过滤重叠度高的区域。这些都能够在MTCNN的推断代码中找到对应。这里就不过多说明。
什么叫边框回归?在MTCNN怎么利用边框回归的结果?为什么可以这样做?
前文完整地解释了P-NET识别候选框的过程了吗?没有。前文只讲清楚了如何使用人脸分类任务的结果。MTCNN的多任务特性还没有体现。我们可以利用边框回归的结果,来修正前面得到的边框区域位置。
类似于前文1.5的过程,一个输入矩阵A,P-NET还能得到4个二维矩阵dx1, dy1, dx2, dy2,每个的尺寸与上述S一样,分布代表人脸区域的左上角和右下角坐标的”相对值”。我们类似于前文1.5的过程,将结果还原成应该对原图的哪个区域修正;如何修正,将在下文解释。
参考南有乔木ICT
(https://blog.csdn.net/zijin0802034/article/details/77685438)的解释,对于窗口一般使用四维向量(x,y,w,h)来表示,分别表示窗口的中心点坐标和宽高。我们的目标是寻找一种映射,使得输入原始的窗口 P(下图红框) 经过映射的结果跟真实窗口G(下图绿框)更接近。

假设这种映射是线性映射,那么我们可以先做平移
(Δx,Δy),Δx=Pwdx(P),Δy=Phdy(P),
这是R-CNN论文提出的:
Gx=Pwdx(P)+Px,Gy=Phdy(P)+Py
然后再做尺度缩放
(Sw,Sh),Sw=exp(dw(P)),Sh=exp(dh(P))
对应论文中:
Gw=Pwexp(dw(P))
Gh=Phexp(dh(P))
我们学习的就是映射关系dx(P),dy(P),dw(P),dh(P)。而上面的这几个公式,就是在做线性变换。学习这些映射关系的过程就是在线性回归求解参数矩阵的问题。所以称之为边框回归。
为什么可以假设是线性映射?因为窗口P和真实窗口G的尺寸差异不大。
南有乔木ICT
(https://blog.csdn.net/zijin0802034/article/details/77685438)解释得比较精彩,感兴趣的可以参考之。我们从P-NET的边框回归训练数据的准备过程可以找到对size的限制,保证窗口的尺度缩放程度不大。
根据上面的解释,P-NET得到的4个二维矩阵的值,并不是真实的坐标,而是把原坐标映射到更接近真实坐标的映射关系。MTCNN的映射关系与上文的这种有一点点区别,下面展示如何从P-NET得到的边框坐标,修正原图上的边框坐标的算法:
令
(x1, y1),(x2, y2)分别是输入矩阵中一个矩形区域的左上角和右下角坐标
(x, y, dx1)是边框回归结果上一点,dx1表示对左上角点的横坐标x1的修正值
(x, y, dy1)是边框回归结果上一点,dy1表示对左上角点的纵坐标y1的修正值
(x, y, dx2)是边框回归结果上一点,dx2表示对右下角点的横坐标x2的修正值
(x, y, dy2)是边框回归结果上一点,dy2表示对右下角点的纵坐标y2的修正值
则根据上面1.5的坐标还原算法:
x1_origin = x * 2 / scale
y1_origin = y * 2 / scale
x2_origin = (x * 2 + 12) / scale
y2_origin = (y * 2 + 12) / scale
下面是修正:
上面这个区域,宽和高是 w = h = 12 / scale
x1_calibration = x1_origin + w * dx1
y1_calibration = y1_origin + h * dx1
x2_calibration = x2_origin + w * dx1
y2_calibration = y2_origin + h * dx1
至此,我们讲清楚了怎么利用边框回归的结果。
从实现层面,3层模型,P-NET, R-NET, O-NET,每个流程都能同时输出分类的结果,以及修正的值。我们会对所有分类得分高于阈值,且重叠率不高的框进行这样的修正。
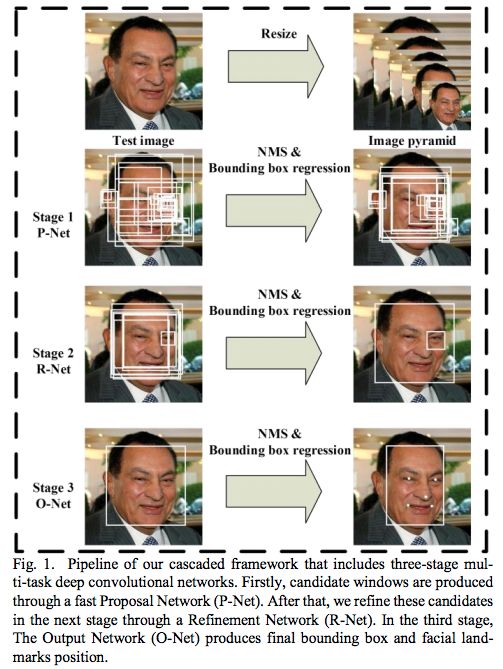
现在再来看原文中的Fig1,是不是恍然大悟?
哪些步骤是影响MTCNN的计算效率的关键?以及有哪些优化思路?
这个部分因为机器性能、参数设置、输入图片尺寸,都对实际的计算效率有很大影响,仅提示一些关键点。
3.1 三个阶段的时间占比如何?
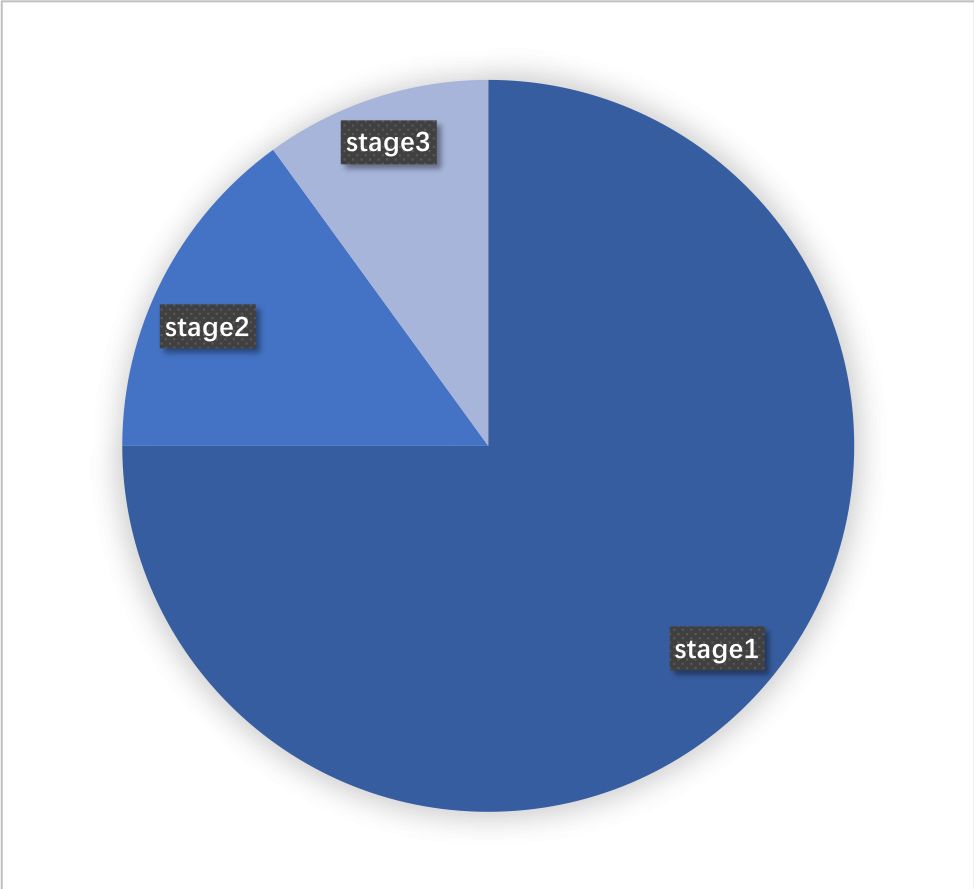
3.2 有什么优化方案?
MTCNN的推断是CPU密集型运算,如果是图片超过1080,生成图像金字塔的过程可能是流程中最耗时的过程。因为金字塔结构,第一阶段需要地计算很多尺度的图片。但超过1080的图片中,你需要识别的最小人脸真的需要12*12吗?minsize是不是也变大了?另外,如果你事先已经知道图片中人脸的大小,是不是可以调整一下minsize?结合你的实践场景可以思考下。
以耗时最大的第一阶段为主要优化的关键点,以下说明一些我尝试过的办法:
- 第一阶段受输入图片尺寸影响较大,可以让minsize随图片尺寸而改变,大图用大minsize
- 图片金字塔的生成过程,对上一次的resize结果进行resize而不是对全图resize
- 并行化第一阶段,收益不大,不如少resize几次。
3.3 推断过程中,网络模型真的那么耗时吗?
谈这个,是为了谈一下这个模型的计算量。当我们发现resize的耗时占比惊人的时候,反观模型发现网络都比较浅。下面展示了mtcnn各阶段的计算量和参数量,以作参考。


参数量和计算量估计参考科普帖:深度学习中GPU和显存分析(https://zhuanlan.zhihu.com/p/31558973)提到的方法,仅仅是近似估计(没有计算Relu的参数量和计算量,没有计算baises的参数量等)。从参数量来看,R-NET和O-NET比P-NET复杂很多。但还是很浅,最复杂的网络O-NET参数量为0.38M个,相比VGG16的参数量138M个,相差近千倍。复杂度和存储消耗不是问题。
实际上计算量也不高,即使使用特别大的图片,p-net一次计算量也仅9G FLOPs,什么概念?1张GTX 1080TI处理能力10T FLOPs,p-net的计算量相对于显卡的处理能力也是相差近千倍。计算量也不是问题。
所以,本人认为这个模型的推断不太耗时,从本人的测试结果看,对于输入200*200左右的图片,每个模型执行一次的时间在CPU和GPU都仅几ms。个人认为用GPU来为MTCNN推断很不划算,下表给出一些测试结果:

我们可以从上表得,网络越复杂,GPU相比CPU的提升越明显。MTCNN的三阶段都是很弱的网络,GPU的提升不太大。另外,MTCNN的第一阶段,图像金字塔会反反复复地很多次调用一个很浅层的P-NET网络,导致数据会反反复复地从内存COPY到显存,又从显存COPY到内存,而这个复制操作消耗很大,甚至比计算本身耗时。
感兴趣的读者可以自己做一下测试。这里引用阿里云云栖社区的一批文章”揭秘GPU”的测试结果(https://zhuanlan.zhihu.com/p/43144460):
我尝试了以下三件事:
- 做一个200×200矩阵乘以numpy,一个高度优化的CPU线性代数库。
- 使用PyTorch cuda张量在GPU上进行200×200矩阵乘法运算。
- 使用PyTorch cuda张量在GPU上进行200×200矩阵乘法运算,每次都来回复制数据。
正如预期的那样,GPU只运行得更快,这一次大约是6倍。有趣的是,1和3几乎花费了相同的时间。GPU操作的效率几乎完全被数据传输的低效所平衡!
这里对性能方面的研究做一些总结:
- MTCNN的推断流程性能优化从第一阶段入手,关键是降低迭代次数,可以利用minsize;
- MTCNN的推断流程中,模型计算耗时没有想象中那么大,反而可能是不断显存和内存之间来回复制数据导致效率不高;
原作者认为的MTCNN
写到这里,仅是本人站在使用者、站在2018年末对MTCNN的一些理解。但是2016年发表这篇文章的时候还是有挺多启发意义的,但从Github上能找到的复现repo数量,就能窥见端倪。用心找找,能找到mxnet、pytorch、tensorflow、caffee的多个实现,有人嫌慢还用c改写。可见MTCNN还是一个比较成功的模型。
马上我们就要抛弃MTCNN,拥抱更好、更快的state-of-the-art人脸检测模型。在这样的时刻,以此文告别MTCNN。
最后以原作者总结的MTCNN的优点结尾:
The major contributions of this paper are summarized as follows:
(1) We propose a new cascaded CNNs based framework for joint face detection and alignment, and carefully design lightweight CNN architecture for real time performance.
(2) We propose an effective method to conduct online hard sample mining to improve the performance.
(3) Extensive experiments are conducted on challenging benchmarks, to show the significant performance improvement of the proposed approach compared to the state-of-the-art techniques in both face detection and face alignment tasks.
本文来自信也科技拍黑米,经授权后发布,本文观点不代表信也智慧金融研究院立场,转载请联系原作者。