
【导语】机器学习离不开模型变量,就像鱼离不开水一样。在信也科技这样的互联网金融科技公司,各个模型团队每天都要面对不同的业务线去建立不同的模型,如新客、老客、贷后、风控等等,如何能在海量数据中快速找到有效的变量,如何能提高效率方便团队共享或复用已有高质量多维度变量,如何解决变量生产时的内生关联问题等等是玄策这个神秘系统解决的问题。
背景与现状
随着信也科技业务量的飞速增长,模型团队日益壮大,对模型变量的需求也在与日俱增,模型团队的同学每天训练得风生水起,然而找变量和准备模型数据常常使大家非常头疼:
1. 多个团队各自开发变量,造成许多重复冗余工作;
2. 逻辑没有集中管理,元数据字段缺失;
3. 变量确定后,需要大量时间做历史回溯;
4. 变量上线后,执行和监控任务非常分散,占用大量人力资源,不便于管理…
为了解决上述诸多痛点,我们想到既然数据库可以有元数据字典,为何不研发一款兼顾计算功能的变量字典,基于此构想,玄策,一款数据产品应运而生。
何为玄策?这个词出自于《后汉书》,本意指神妙的谋略。只要把玄策用得溜,超神上王者…哦不,躺着模型跑分不再是梦。
目前它已成为信也科技自动化机器学习平台的组件之一,肩负着线下变量计算和管理的重要任务。
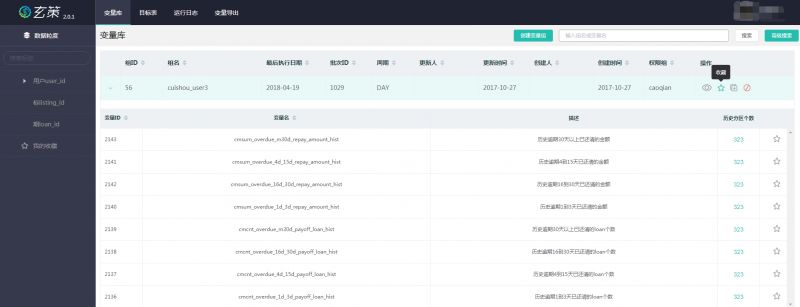

作为数据字典的玄策
玄策是一个web应用,友好简洁的前端界面,具备以下特点:
1. 可以让用户便捷地在变量库通过浏览不同主题或感兴趣的关键词查看相关变量;
2. 可以通过高级搜索功能快速查找和定位变量;
3. 在查阅变量后用户可自由收藏自己关注的变量,在我的收藏页中轻松选中变量一键创建对应宽表,作为模型训练的输入;
4. 可以随时创建和修改变量逻辑,为变量库添砖加瓦。
近期玄策还上线了批量修改模式。统一集中的交互界面让用户快速了解变量逻辑和对应的owner,有任何问题摸不着头脑的时候再也不用苦苦追寻那个ta了,同时更加有效和规范地复用已有逻辑,极大地避免重复工作。
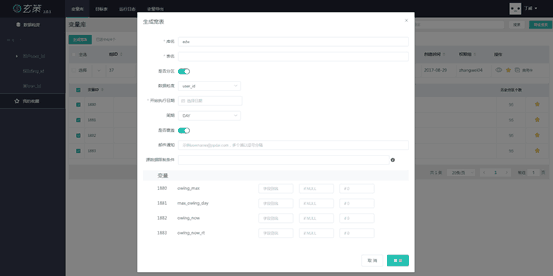
作为变量仓库的玄策
变量底层数据存储在Hadoop分布式文件系统上,对于海量数据的容量大小已无需担心,在设计表结构时我们使用了键值对的方式提高横向扩展性和灵活性,满足了不断增长和随时变化的业务需求,任意动态地增加或删减变量对上下层来说都透明。
玄策在接收到数据刷新请求时会提前检测是否已存在对应分区,若已存则在会自动跳过,避免了重复的执行和人工筛查,因此在做变量计算历史回溯时,只需关注日期区间,无需担心无用的重复刷新。为适应不同应用场景,刷新条件也可设置强制执行,忽略历史分区检查的步骤。
部分常用变量已预加载近半年分区数据,大大减少用户自行回溯历史数据的时间,随着时间推移和玄策上支持业务量的增加,变量仓库中可供使用的历史数据会持续增加,进一步减少额外地回溯时间。同时用户在前端界面也可以直接查看每个变量的已存储的历史分区。
由于玄策键值对的表结构设计,所有变量值统一设置为String格式,这样的设计也带来了变量数据类型丢失的问题,为此后端增加了数据类型自动爬取功能,根据Hive解析用户录入的变量逻辑,从执行计划中预判其对应的数据类型,减少了人工操作,提高了玄策的自动化程度。
在变量的使用上,玄策提供宽表的字段初步预处理,数据范围筛选,多数据库导出,多种数据文件格式等。
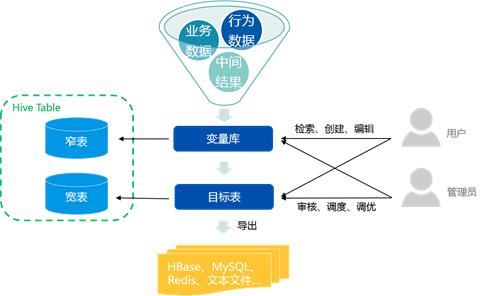
作为变量计算系统的玄策
除了管理逻辑的变量字典功能和计算功能,玄策还有强大高效的计算能力。由于存储了数以千计的变量,能够做到高并发和高扩展成了架构设计的重中之重。
为提升性能并且有效利用集群资源,针对不同变量的不同场景,玄策使用了批次作为其刷新单位,而批次的内容可以自由定义,从同一个业务主题,同一个模型项目,到单独的一个变量都可以成为批次,以提高其灵活性。在不同粒度上可独立设置调优参数,调节并发数,使用优先级配置以确保重要任务的时效问题。
玄策不光支持任意数仓中现有表作为变量输入,更支持将现有变量作为其他变量输入的一部分,在做此依赖检查时还解决了内部失败而造成依赖死循环问题。对维护玄策的人员来说不用再关心变量的底层逻辑,所有变量计算已转化成统一的ETL任务,在前端页面也可监控每个变量的刷新状态。
后记
玄策作为机器学习平台中的一员上线时间还非常短暂,但在模型团队的大力支持下,目前已贡献的变量有3000+个,每日运行上线使用当中的变量近千个。
因其高并发性,计算变量的时效较过去有明显提高,同时有效减少变量开发和维护的工作量。但是革命尚未成功,玄策还有许多不足之处,比如在版本控制,和模型训练系统耦合等功能还有待开发,目前仍在迭代上线中。
除了模型跑分的用户,我们也希望它能为业务分析的团队提供应用场景,使玄策能更健壮,更多效。欢迎交流。
感谢共同开发和维护的小伙伴们,后续迭代敬请期待~
本文来自信也科技拍黑米,经授权后发布,本文观点不代表信也智慧金融研究院立场,转载请联系原作者。