
背景
信也科技的特征计算平台需要大量使用用户时序数据计算特征值,目前采取的方案是,使用HBase存储数据,通过restful接口按照用户ID维度拉取明细数据,然后在服务器内存中计算结果。但是存在以下问题:
1. 用户时序数据量太大。当拉取数据过万条时,耗时增加非常明显,往往需要数秒钟才能获取完整数据。
2. 特征值计算复杂,需要用到用户ID,手机号,时间范围和关键词等多维度统计汇总。为了满足需求,需要定制很多接口。
3. 大量特征值都要用到关键词匹配,HBase 不擅长基于关键词全文查找,所以目前在拉取所有明细数据后,在代码中使用正则表达式匹配。
为了解决以上问题,我们决定采用Elasticsearch优化特征值的计算。
Elasticsearch介绍
Elasticsearch是基于Lucene的开源搜索引擎,用于存储,搜索和分析数据。其具有如下特点:
1. 分布式的实时文件存储,每个字段都被索引并可被搜索
2. 分布式实时分析搜索引擎
3. 能胜任上百个服务节点的扩展,并支持PB级别的结构化或者非结构化数据
Elasticsearch核心概念主要包括倒排索引,Index和Document等。
倒排索引原理如下图所示:
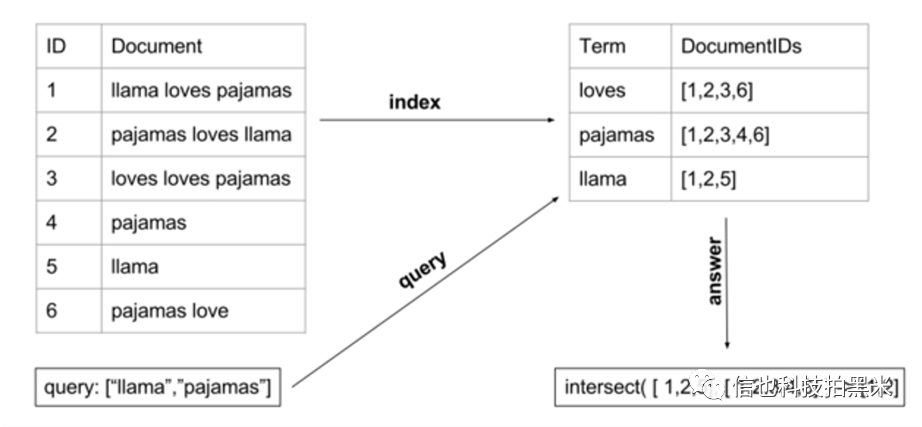

对于多个document,Elasticsearch会在进行分词之后,对每个词建立词项到文档ID的映射,同时词项按顺序排序。查询的时候,使用二分法可快速查找。对于中文内容,可以使用IK分词器进行分词。
Document是一个JSON文档,可以理解成Mysql数据库中的一行。每个Document存放在 Index下面,拥有唯一的ID,可以根据ID查找到对应的文档。
Index可以理解成数据库的表。创建方式如下:
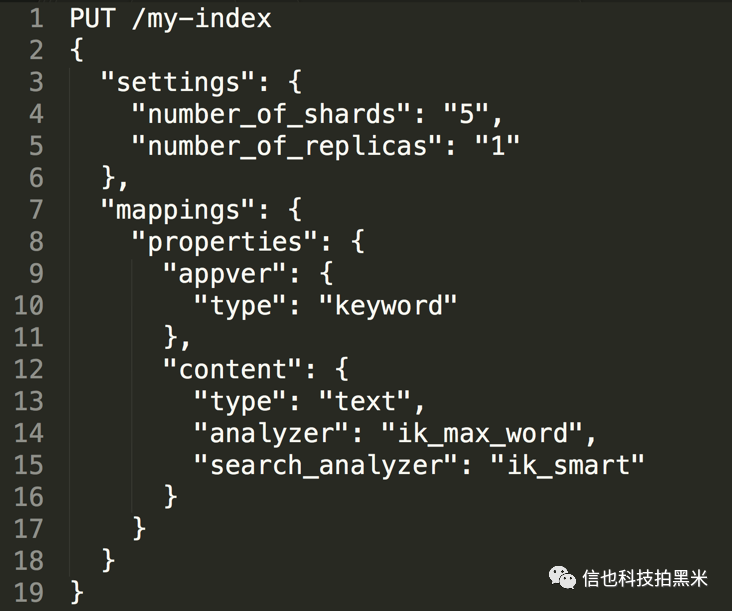
这里,properties下可以指定每个字段的名称和类型。其中类型text支持全文搜索,这里指定了IK分词的方式,keyword则不进行分词,一般用于精确匹配。number_of_shards指定 shard 的数量。每个 shard 是一个Lucene索引,一个Index会有多个shard,分布在不同的节点上,可以提升查询和写入性能。number_of_replicas指定副本的数量,多副本可以提升集群的可靠性和查询性能。
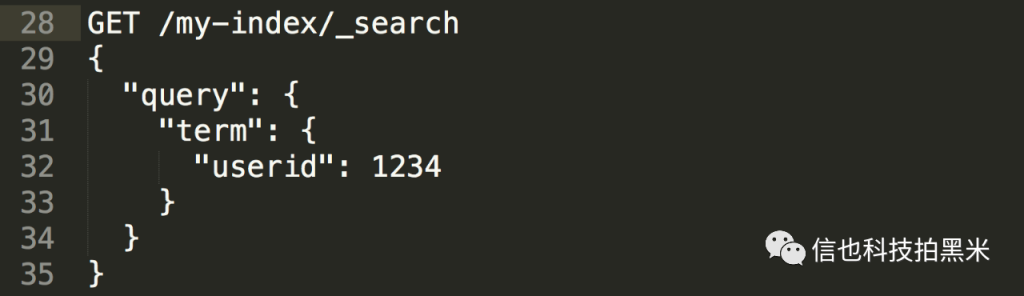
Index创建之后,查询如下:

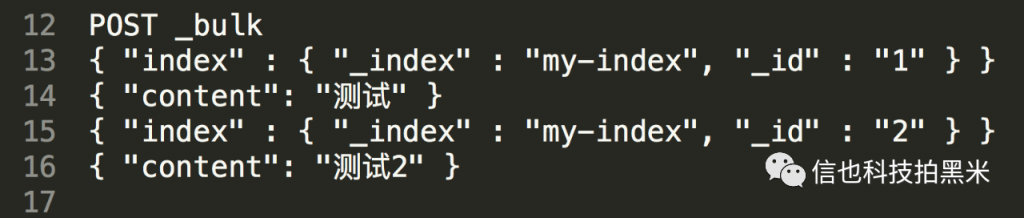
Index数据写入分别单数据写入和批量写入。
单数据写入:

批量写入:
Elasticsearch的查询很复杂,针对字段类型不同,可分为全文搜索和精确搜索。全文搜索会分词后查找,并计算匹配文档的得分,按照得分排序返回结果。简单示例如下:

精确搜索必须要完全匹配才会返回结果,示例如下:
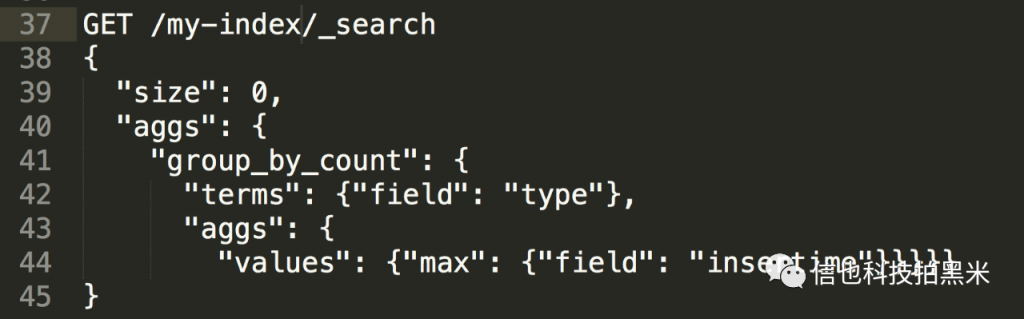
Elasticsearch不仅支持查询明细数据,还可以进行聚合运算。对type字段分组聚合求最大inserttime示例如下:
Elasticsearch不仅支持 /_search API,还可以直接使用sql进行查询。需要注意的是,在sql中,全文搜索需要使用match函数。示例如下:

应用
我们使用Elasticsearch查询和计算用户特征值。具体实现分为配置index,离线导入历史数据,实时导入最新数据,以及查询四个部分。
配置index
考虑到数据量,我们按月分index,每月新建一个index,index后缀为月份。因为所有index配置一样,所以我们首先创建index template,然后根据index template创建具体的index。官方建议每个shard大小在10GB 到 50GB 之间,过大的shard不利于故障恢复,过多的shard 会影响查询性能。综合考虑,我们每个index设置了9个shard。为了保证服务高可用,我们将副本数设置为1。分词方面,我们使用了IK分词器。具体的index template设置如下:
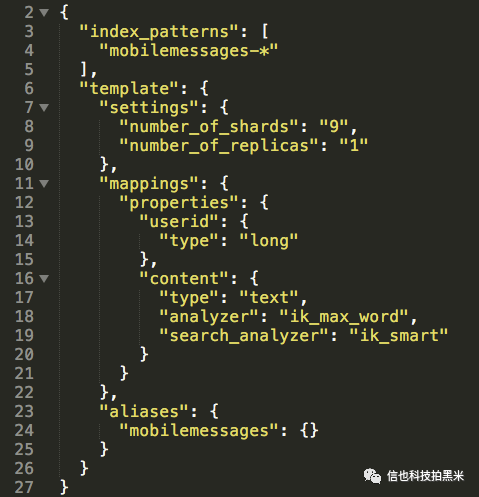
离线导入
离线数据存储在impala中,我们使用Airflow批量导入历史数据。Airflow是一个开源的任务调度平台,使用python代码编写任务,可以方便地编排,管理和监控任务。批量导入Elasticsearch的接口是/_bulk。测试的时候发现,单次调用,数据量达到2000条左右速度较快,平均写入速度达到1万条/秒。但是数据量实在太大,单并发导入远远达不到我们的要求,因此做了如下优化:
1. 在Airflow中, 同时开启多个子任务分别将数据写入不同的index。利用子任务的进程并发提升性能。
2. 设置index.refresh_interval: 120s。Elasticsearch默认每一秒钟执行一次refresh,每次 refresh会生成新的segment,从而让写入数据可读。但是离线导入数据并不需要立即读取,同时较大的segment也可以避免频繁merge。所以设置一个较长的时间。
3. 设置index. number_of_replicas: 0。离线导入期间不需要考虑数据安全性,所以我们设置副本的数量为0。
4. 设置index.translog.durability: async,index.translog.sync_interval: 120s,index.translog.flush_threshold_size: 1024mb。Elasticsearch使用 translog记录所有写操作并fsync刷盘保证数据持久化。默认每次 request 就调用fsync。离线导入可以调整 为每120s fsync一次。
优化之后,速度提升了很多。导入完成后,需要将上述配置改成默认值,保证数据的可靠性。
实时导入
对于实时数据,我们采用kafka+flink实现。具体过程为,生产端写入HBase成功后,将数据写入kafka。由于用户数据的特点是只有新增,没有更新,无需保证消息的有序性,且数据落库可以接受稍微延迟,所以使用kafka是可以接受的。然后flink消费kafka,调用/_bulk接口写入即可。为了去除重复数据,我们使用多个业务字段拼接成唯一文档ID,Elasticsearch写入的时候会根据ID去重。
查询
为方便开发,我们直接使用Elasticsearch的sql进行特征值计算。对于非全文索引,可以直接使用sql查询结果,省去接口调用和代码开发的工作量,加快了开发进度。但是对于全文索引,Elasticsearch的正则表达式计算效率不高。关键词查询的时候,我们首先调用 /index/_analyze查看分词结果,如果分词正确,可以直接用sql计算。如果分词不正确,需要先用match函数全文匹配,筛选出结果集合后,在内存中做正则匹配,计算结果。实践发现,全文匹配可以有效的排除大量无关数据,减少了IO时间。
总结
使用Elasticsearch后,不再需要对特殊查询定制接口,特征值直接用sql计算,无需代码开发,简化了开发过程。同时,不再需要拉取用户明细数据集到服务器内存计算,性能提升了50%以上。
本文来自信也科技拍黑米,经授权后发布,本文观点不代表信也智慧金融研究院立场,转载请联系原作者。