
前言
相信每家互联网公司的每个程序猿都离不开在系统内使用redis,redis是一款高性能的key-value数据库。平时大家使用最多的命令应该是GET和SET,使用最多的数据结构应该是字符串类型,用于解决应用的性能瓶颈或临时性数据存储的场景需求。但是在一些大数据量存储的场景情况下,使用字符串数据类型进行存储,会极大的占用redis的存储空间,导致运维成本增高,且当发生扩容、备份、灾备转移等操作时,会导致这类操作时间极为漫长和集群不稳定的情况发生。
信也科技内部就有遇到需要使用redis存储超过50亿+条目的项目,在项目初期调研时预估只需要存储大约6亿条目的数据量,所以前期做系统设计时并没有考虑到redis存储容量这一块,当时的测算是300G左右的容量是足够的。但当项目上线半个月后,发现当初预估的数据量级与实际数据量级有严重偏差,实际的数据量到后续已增长到50亿+,且每天保持3000W左右的增长量,redis集群从最初的200G扩容到了1.5T。随之而来的是项目成本飙升,redis集群自动备份失败,因为需要备份的数据量级过大导致拉取超时,扩容时间超长,超过3小时+,同时还容易偶发长查询等问题。此时此刻迫切需要一个方案去解决redis的大数据量级存储压缩方案。
1 redis存储压缩方案简介
经过研发团队的小伙伴们各种调研后,最后我们选定使用redis的hash数据结构+ziplist内部编码+protobuf序列化value的方案进行数据存储,在经过项目实战检验后,同等数据量级和value内字段不变的情况下,相比较字符串数据类型可以节省80%+的存储空间。
原存储方案:key(string),value(多字段,采用json string)
新存储方案:key(hash数据结构,key-feild,ziplist编码),value(protobuf序列化) 节省存储空间:80%+
2 redis存储压缩方案实现
2.1 优化数据结构和内部编码,利用ziplist来替代key-value
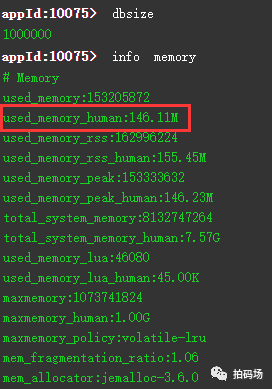

首先我们来采用key-value实现存储100W条数据,key为常规的MD5字符串,value同样为该MD5值,存储好后我们使用info memory命令查看下当前redis的空间占用情况:
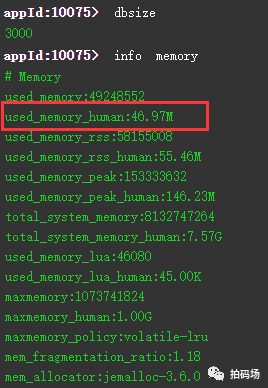
可以看到,经过实测,采用字符串key-value方式直接存储,100W条数据占用了大概146MB的存储空间。同样一批数据,我们换hash+ziplist存储方式,先来看下结果:
在我们利用hash+ziplist后,100W条数据占用了大概47MB的存储空间,大约减少了68%的存储空间,这是怎么做到的呢?
2.2 redis底层存储数据结构和编码方式剖析
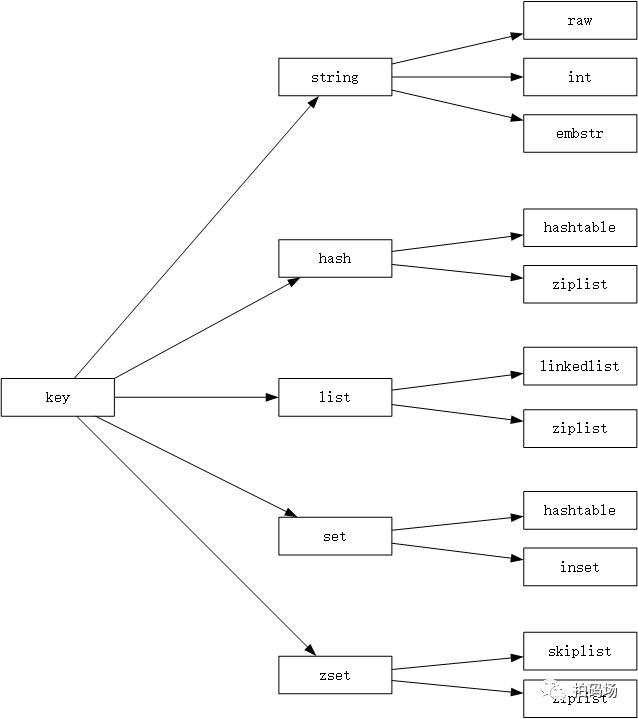
我们先来看一下redis底层存储数据结构和编码方式的简要图:
2.2.1 redis如何存储字符串
首先我们要了解redis是如何存储字符串的,为什么字符串存储会占用较多的空间。string是redis里最常用的数据结构,redis的默认字符串和C语言的字符串不同,它是自己构建了一种名为“简单动态字符串SDS”的抽象类型:

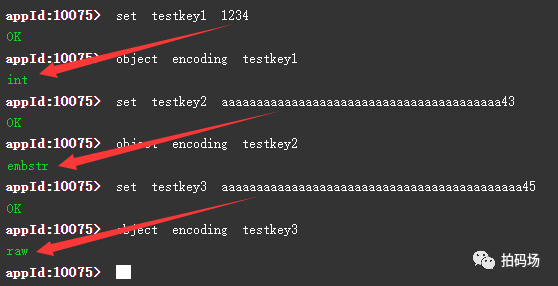
具体到string的底层存储,redis共用了三种编码方式,分别是int、embstr和raw。
比如set testkey1 1234,采用int编码方式;set testkey2 aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa43,采用embstr编码方式;set testkey3 aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa45,采用raw编码方式。当value的长度大于44(或39,不同版本不一样)个字节时,会采用raw。
而在redis里面,int是一种定长的结构,占8个字节(注意,相当于java里的long),只能用来存储长整型。embstr是动态扩容的,每次扩容1倍,超过1M时,每次只扩容1M。raw用来存储大于44个字节的字符串。
具体到我们的案例中,key和value是32个字节的字符串(embstr),所以如果能将32位的md5 key变成int,那么在key的存储上就可以直接减少3/4的内存占用。此为第一个优化点。
2.2.2 redis如何存储hash
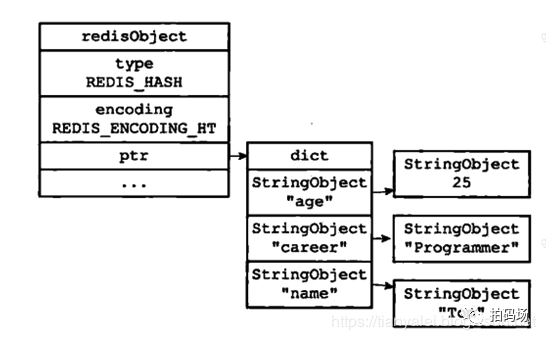
从2.1的redis数据结构图上我们可以看到hash数据结构,在编码方式上有两种,一种是hashtable,另一种是ziplist。
hashtable大家很熟悉,和java里的hashMap很像,都是数组+链表的方式。java里hashmap为了减少hash冲突,设置了负载因子为0.75。同样,redis的hash也有类似的扩容负载因子。这里的细节不提,只需要留个印象,用hashTable编码的话,则会花费至少大于存储的数据25%的空间才能存下这些数据,它大概长这样:
而ziplist,压缩链表,它大概长这样:
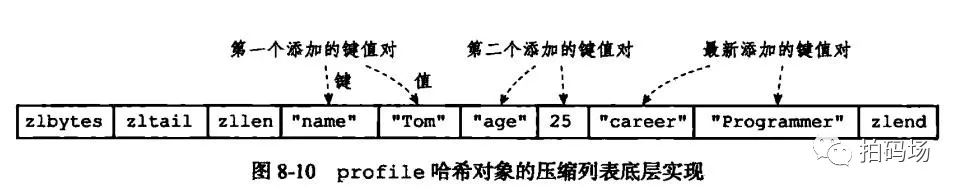
可以看到,ziplist最大的特点就是,它根本不是hash结构,而是一个比较长的字符串,将key-value都按顺序依次摆放到一个长长的字符串里来存储。如果要找某个key的话,就直接遍历整个长字符串就好了。所以很明显,ziplist要比hashtable占用少的多的空间,但是同时会耗费更多的cpu来进行查询。
那么何时用hashtable、ziplist呢?我们通过redis.conf文件中可以找到,或者直接命令获取:
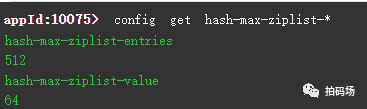
就是当这个hash结构的内层field-value数量不超过512,并且value的字节数不超过64时,就使用ziplist。通过实测,value数量在512时,性能和单纯的hashtable几乎无差别,在value数量不超过1024时,性能仅有极小的降低,很多时候可以忽略掉。而内存占用,ziplist可比hashtable降低了极多。此为第二个优化点。
2.2.3 使用ziplist来替代key-value
通过上面的知识,我们得出了两个结论。用int作为key,会比string省很多空间。用hash中的ziplist,会比key-value节省巨大的空间。那么我们就来改造一下当初的100W个key-value。
第一步:
我们要将100W个键值对,放到N个bucket中,每个bucket是一个redis的hash数据结构,并且要让每个bucket内不超过默认的512个元素(如果数据量级极大,比如上百亿等场景,可以更改hash-max-ziplist-entries的配置,如1024,此时每个bucket内的元素个数则不能超过修改后的值),以避免hash将编码方式从ziplist变成hashtable。
100W / 512 = 1953。由于将来要将所有的key进行哈希算法,来尽量均摊到所有bucket里,但由于哈希函数的不确定性,未必能完全平均分配,以及可能存在的正常数据增长量,所以我们要预留一些空间,譬如这里分配3000个bucket。
第二步:
选用哈希算法,决定将key放到哪个bucket。这里我们采用高效而且均衡的知名算法crc32,该哈希算法可以将一个字符串变成一个long型的数字,通过获取这个md5型的key的crc32后,再对bucket的数量进行取余,就可以确定该key要被放到哪个bucket中。
private static int KEY_COUNT = 3000;private static String hashkey(String key) {CRC32 crc32 = new CRC32();crc32.update(key.getBytes(Charset.forName("UTF-8")));return crc32.getvalue() % KEY_COUNT + "";}
第三步:
通过第二步,我们确定了key即将存放在的redis里hash结构的外层key,对于内层field,我们就选用另一个hash算法,以避免两个完全不同的值,通过crc32(key) % COUNT后,发生field再次相同,产生hash冲突导致值被覆盖的情况。内层field我们选用bkdr哈希算法(或直接选用Java的hashCode),该算法也会得到一个long整型的数字。value的存储保持不变。
private static int BKDRhash(String str) { // 31 131 1313 13131 131313 ...找个质数
int seed = 131;
int hash = 0;
for (int i = 0; i < str.length(); i++) { hash = (hash * seed) + str.charAt(i); }
return (hash & 0x7FFFFFFF); }
第四步:
装入数据,原来的数据结构是key-value,2c0c903b2df742be86f8264c13780225 → 2c0c903b2df742be86f8264c13780225。现在的数据结构是hash,key为778,field是17276529,value是2c0c903b2df742be86f8264c13780225。
通过实测,将100W数据存入3000个bucket后,整体hash比较均衡,每个bucket下大概有300多个field-value键值对。

通过上图查看目前的编码方式还是为ziplist,因为目前一个key内的元素数量还只有339个,没有超过hash-max-ziplist-entries=512的配置值,此时我们可以尝试再多写入100W的数据,因为200W/512=3906,已经超过了当时我们设计的3000个bucket,所以单个bucket中的元素个数已经超过了hash-max-ziplist-entries=512的默认配置,redis会自动改为hashtable的内部编码,不再使用ziplist,而如果按ziplist存储100W的数据占用47MB来计算,理论上200W的数据量只会占用100MB不到的内存,但编码被改成hashtable后,我们可以看到内存占用一下增长到了256MB,进一步实际证明了hashtable比ziplist会占用更多的存储空间:
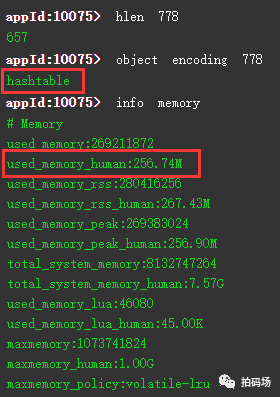
采用hash的重点在于,理论上只要不发生两次hash算法后,均产生相同的值,那么就可以完全依靠key-field来找到原始的value,这一点可以通过计算总量进行确认。实际上,在bucket数量较多时,且每个bucket下,value数量不是很多,发生连续碰撞概率极低,实测在存储50亿情况下,未发生明显碰撞。但我们在经过110亿+的数据验证后,发现有6个碰撞情况产生,所以对于数据量级极大且精度要求极高的场景,需要注意这一点:
采用key-value型和hash型,分别查询100W条数据,看一下两者在查询性能上的优劣。
key-value耗时:10653、10790、11318、9900、11270、11029毫秒。hash-field耗时:12042、11349、11126、11355、11168毫秒。
可以看到,整体上采用hash存储后,查询100万条耗时,也仅仅增加了500毫秒不到,对性能的影响极其微小。但内存占用从146MB变成了47MB,带来了接近68%的内存节省。
2.2 对大字符串value做序列化或压缩
前面我们已经采用变更存储的数据结构和内部编码来达到节省redis内存空间的目的,但此时还只节省了约68%的空间,我们在想是否还能继续优化呢?我们在实际项目中存储的value是个多字段属性的对象,所以在最初设计时,为了使用方便,直接采用了json序列化成字符串进行了存储,但通过了解redis的数据结构后,发现字符串会额外浪费较多的存储空间,所以此时就要对value也进行存储优化。
具体优化方式我们想到了两种:压缩或序列化。最终通过一系列的调研和比对,选用了google的protobuf序列化进行value处理,可以达到极致性能和节省大量空间的目的。
2.2.1 序列化
比如经过测试,同样的一个对象,在经过JSON序列化成字符串后,占用约178字节,但经过protobuf序列化之后,只占用了约53字节,节省了约70%的存储空间。
而我们知道,即使采用hash数据结构,在value长度超过hash-max-ziplist-value默认配置64字节后,redis会采用存储空间占用较大的hashtable编码方式,不再使用ziplist,而protobuf序列化之后的53字节,是没有超过64字节的,刚好符合ziplist编码方式的要求,即使以后还需要在此对象上扩展字段,可能会超过64字节的场景下,我们也可以去调整hash-max-ziplist-value的配置改到128字节,即使再多扩展几个字段,相信也不会超过此配置值。但跟元素个数配置(hash-max-ziplist-entries)一样,不宜改得太大,这样对cpu的压力会更大,对查询时的性能影响肯定更大,需要在存储空间和性能上取其平衡。
JSON序列化示例:
{ "app": {
"device": 1,
"os": 2
},
"medias": [
{
"exposure": null,
"name": "asdfgh",
"no": 67056402,
"total": 67056402,
"yes": 0
},
{
"exposure": 1777,
"name": "qwerty",
"no": 5058,
"total": 5058,
"yes": 0
}
]
}
protobuf序列化示例:
Proto源文件:
syntax = "proto2";package com.bobe.test.entity;option java_outer_classname = "RtaredisProtos";message Rtaredis { enum AppOS { OS_IOS = 1; OS_ANDROID = 2; } enum AppDevice { OS_IDFA = 0; OS_IMEI = 1; OS_ANDROIDID = 2; OS_OAID = 3; } message App { //系统类型 optional AppOS os = 1; //设备类型 optional AppDevice device = 2; } optional App app = 1; message Media { optional string name = 1; optional int32 yes = 2; optional int32 no = 3; optional int32 total = 4; optional int32 exposure = 5; } repeated Media medias = 2;}
protobuf序列化代码示例:
private byte[] getProtoBufBytes() { RtaredisProtos.Rtaredis.Builder builder = RtaredisProtos.Rtaredis.newBuilder(); RtaredisProtos.Rtaredis.App.Builder builderApp = RtaredisProtos.Rtaredis.App.newBuilder(); builderApp.setOs(RtaredisProtos.Rtaredis.AppOS.OS_ANDROID); builderApp.setDevice(RtaredisProtos.Rtaredis.AppDevice.OS_IMEI); builder.setApp(builderApp); RtaredisProtos.Rtaredis.Media.Builder builderMedia1 = RtaredisProtos.Rtaredis.Media.newBuilder(); builderMedia1.setName("qwerty"); builderMedia1.setYes(0); builderMedia1.setNo(5058); builderMedia1.setTotal(5058); builderMedia1.setExposure(1777); builder.addMedias(0, builderMedia1); RtaredisProtos.Rtaredis.Media.Builder builderMedia2 = RtaredisProtos.Rtaredis.Media.newBuilder(); builderMedia2.setName("asdfgh"); builderMedia2.setYes(0); builderMedia2.setNo(67056402); builderMedia2.setTotal(67056402); builderMedia2.setExposure(0); builder.addMedias(1, builderMedia2); RtaredisProtos.Rtaredis rta = builder.build(); return rta.toByteArray(); }
2.2.2 压缩
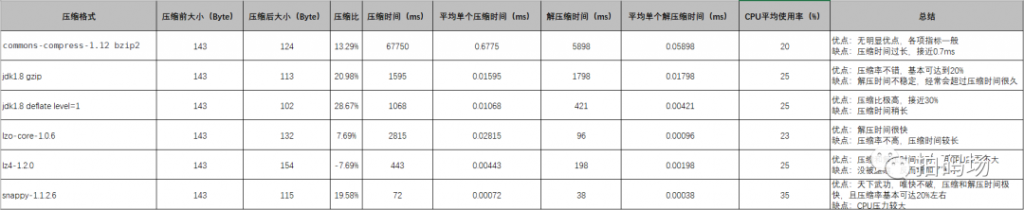
同时我们也调研了市面上常见的一些压缩算法,最终没有选压缩算法的方案是因为发现在对象较小的场景下,压缩算法的压缩比不高,且性能上也有一定的损耗。如果在有较大字符串的场景下,推荐使用google的snappy压缩算法,经过实测后发现此压缩算法在性能、压缩比、资源消耗等上有明显优势。这里我们就不再具体详细去介绍每个压缩算法的调研情况了,仅附上我们调研的压缩算法实际情况,可供大家后续在实际项目中参考使用:
3 总结
- 大量的key-value,占用过多的key,redis里为了处理hash碰撞,需要占用更多的空间来存储这些key-value数据。
- 如果key的长短不一,譬如有些40位,有些10位,因为对齐问题,那么将产生巨大的内存碎片,占用空间情况更为严重。所以,保持key的长度统一(譬如统一采用int型,定长8个字节),也会对内存占用有帮助。
- string型的md5,占用了32个字节。而通过hash算法后,将32降到了8个字节的长整型,这显著降低了key的空间占用。
- 要善于利用redis的各种数据结构,不要仅限于string类型。比如ziplist比hashtable明显减少了内存占用,它的存储非常紧凑,对查询效率影响也很小。所以利用ziplist,避免在hash结构里,存放超过512个field-value元素,即使遇到大数据量极端场景,也可以考虑更改配置支持到1024个元素。
- 如果value是字符串、对象等,应尽量采用byte[]来存储,同样可以大幅降低内存占用。譬如可以选用google的protobuf序列化,或者google的snappy压缩算法,将字符串转为byte[],非常高效,压缩率也较高。
- 为减少redis对字符串的预分配和扩容(每次翻倍),造成内存碎片,不应该使用append,setrange等。而是直接用set,替换原来的。
4 方案缺点
- hash结构不支持对单个field的超时设置,但可以通过代码来控制删除,对于那些不需要超时的长期存放的数据,则没有这种顾虑。
- 存在较小的hash冲突概率,对于对数据量极大,要求极其精确的场合,应谨慎采用该压缩方案。
5 信也使用情况
字符串key-value存储方案的redis集群情况:

50亿数据时,redis集群占用了1.2T的内存

hash+ziplist+protobuf存储方案的redis集群情况:此时我们可以看到,整个集群从1.5T降到了100G,且目前仅使用了30G不到,我们使用ziplist的方式存储1亿的数据预估仅使用了1G的内存空间,因业务上也有数据量级优化,实际上现在并没有去存储50亿的数据,但即使是需要存储50亿的数据,100G的内存也是足够,比当时的1.2T节省约90%的存储空间。
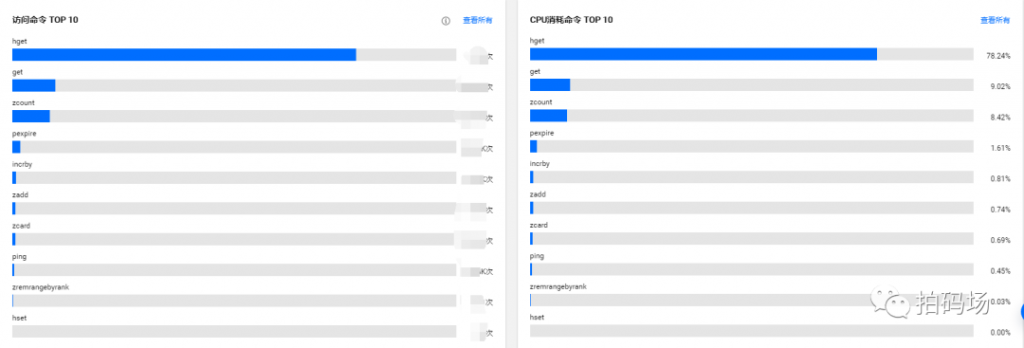
新集群命令和CPU消耗情况,我们可以看到不仅仅只有set和get命令了,这其中除了使用hash,我们还在其他数据上面使用了list数据结构等,如果大家有兴趣也可以随时交流:
本文来自拍码场,经授权后发布,本文观点不代表信也智慧金融研究院立场,转载请联系原作者。