
随着智能手机的普及,每个人都享受着手机带给人们的便利。几乎每个手机现在都有着两个甚至三个摄像头。人们对于通过拍照来获取文件信息的需求也越来越大,这也有助于节省用户手动输入信息的时间,提升用户体验。
本文主要探讨OCR (Optical Character Recognition) 技术在识别银行卡上的一些特点和难点,基于两种应用于银行卡的OCR技术,一种是基于传统OCR技术的改进方法,另一种是基于深度学习的OCR技术。


基于传统OCR技术的改进
与传统的OCR相比,银行卡OCR技术有很大的不同,主要出于以下几个原因:
- 银行卡图像背景非常复杂;
- 银行卡种类非常多,卡号的位置和长度(16至19位)也是不固定的;
- 银行卡的压印字符同其他字符相比区别较大,生成样本因此存在一定难度。
为了应对这些难点,传统的OCR设计流程如下:

- 取图:目前主要采用视频预览方式,对视频进行抽帧,取一帧清晰的彩色图像。也就是手机相机扫描界面在实时取图,目前主要的是通过检测边框来判断银行卡是否已经放到指定框内,这样保证能取到质量比较好的图片。
- 图像预处理:这里主要是去噪,通过灰度处理和二值化,最终只留下黑色和白色。
- 行业定位:二值化完成后,需要定位到银行卡号的位置。
- 字符切分:将银行卡号单个数字进行切分(切分是OCR技术中一大难点)。
- 字库比对识别:这一步只有是将切分完成后的单数字与字库中的数值模版进行对比,取置信度最高值。
针对这个流程,智慧金融平台可采取改进措施来提高OCR能力,大致流程如下:
1.对于银行卡卡号定位我们尝试了对银行卡图像进行膨胀运算,膨胀运算使得图像的某些部分或区域按结构元素的大小和形状进行一定的扩充。
因为银行卡号字符相隔较近,膨胀后可以增加卡号范围内的像素点数目,通过用一个等高度的矩形框扫过整个银行卡范围,返回像素点最多的区域,用来获得银行卡号位置。最终我们可以得到三个长条框,如下:
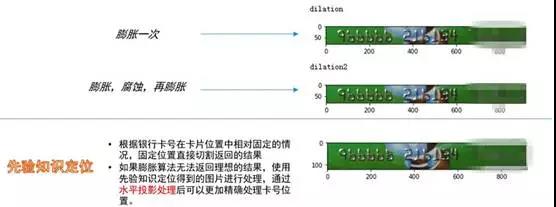
对于得到的长条框使用一个CNN模型来进行分类,CNN模型主要来判断图中的数字是否居中,如果居中的话,输出的分数会越接近于1。
最后,用以下公式来确定我们输入到下一个步骤的长条框:
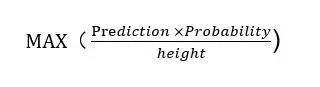
其中,Prediction为0或者1,Probability为CNN模型输出的分数,Height是长条框的高度(以它做分母主要是为了降低选中通过先验知识定位得到的长条框的概率)。
2.对于得到的银行卡长条框,进入第二步字符切割:

对于其中第3步中的背景剔除,进行结果展示:

但是对于背景图案太花或者出黑色字体的银行卡这种处理方法没有显著的效果。
对于字符切割过程中出现字符粘连的问题我们采用更新垂直投影切割阈值的方法来解决:
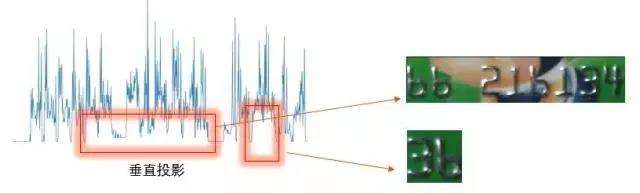
更新后的阈值:

除了更新阈值的方法,我们还基于对图片遍历得到的字符串进行计算得到结果,也可以改善字符粘连的情况。
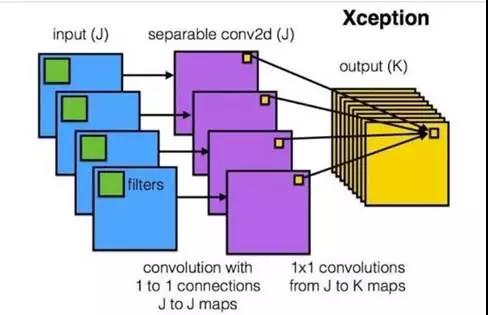
3.对于得到的细分割字符进行识别,使用迁移学习的方法在小数据集上达到高准确率的识别,Base Model选用的是Xception Net,在验证集上的识别准确率很高。
其中,对于小数据集且识别内容和预训练模型差异性很大的时候,训练时建议从前面几层就开始训练,而不是fine tune最后的全连接层。
基于深度学习的OCR技术
通过上面的介绍,基于传统OCR技术的识别中间步骤比较多,且所用时间较长,准确率提升起来代价大、难度很高。随着这几年深度学习的技术突飞猛进,一些基于深度学习的OCR框架被提出,主流技术是文本检测结合序列识别,如下图:

可以看到,基于深度学习的框架不会遇到切割字符等问题,大大提高了准确率。
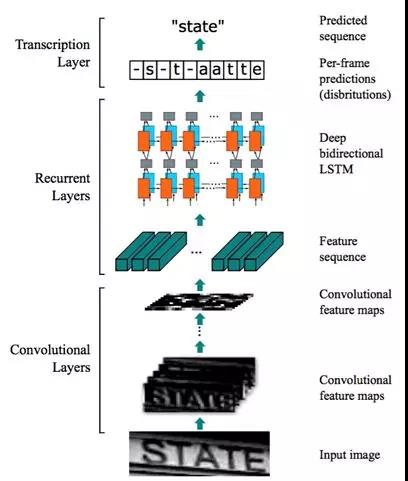
通过对算法得到的结果进行长宽比的筛选即可快速得到卡号区域,使用一种Segmentation-Free的方法CRNN来进行文本行的识别, 即CNN+LSTM+ CTC (Connectionist Temporal Classification),其识别率为最高。
其中,LSTM+CTC是将语音识别的解决方案迁移到文本识别来。首先,将整个图片输入到LSTM层,一列看成一个单词,图片有N列,就会被看成N个单词,然后这列的像素就看成是这个单词的描述。
在OCR的问题上,其实就是图片的每一列都输出各个文字的类别概率。
在这里值得注意的是,输出的类别中需要增加一个Blank类别,代表空白无输出。CTC LOSS的概率求解思路其实很类似于HMM的概率计算,它可以用在任意的序列分类识别的问题上,也是实现语音识别中END-TO-END的关键步骤。而CRNN即在LSTM前面加上了CNN预提去特征,训练采用的数据是由真实样本结合自动生成样本组成的,见下图:
总结与规划
本文对银行卡OCR技术从传统技术到深度学习框架都做了简单的介绍,其中很多技术遗憾未能展开,但是例如LSTM+CTC可以应用在语音领域,迁移学习可以帮助很多业务在缺少大量数据的情况下提供一个效果不错的模型。总之,人工智能的时代已经来了,未来会在各个领域给大家不断地创造惊喜。