
人工智能(AI)面临的一项重要挑战就是教会机器使用人类语言(natural language)与人进行交流。随着自然语言处理技术的不断发展,我们和这一目标之间的距离在不断缩短,而客服机器人也随之成为一个可以快速落地并产生价值的人工智能领域,涌现出一大批成功的创业公司。传统客服聊天窗口在人工智能的助力下,具备了更多功能,成为公司与客户交互的一种重要方式。本文中,我们来简单讨论一下聊天机器人背后的算法。
对话系统算法模块的框架
一个任务导向(task-oriented)的对话系统通常会包含以下几个模块:
1)NLU:全称是“Natural Language Understanding”,将用户发送的文本消息映射为系统内部预先存储的用户意图;
2)Tracker:负责记录和保存对话状态和用户信息,在较复杂的对话系统中,该模块会与数据库中的用户画像做交互;
3)Policy:对话策略,根据当前对话状态和其他用户数据来决定系统的下一个动作;
4)NLG:为用户提供系统反馈。
我们以开源聊天系统框架rasa core【1】为例,简要介绍对话系统算法模块的经典框架:


1)系统收到用户消息,通过NLU解释器(Interpreter)将其转化为用户意图(intent)和实体(entities);
2)对话状态跟踪器(Tracker)负责记录整个对话的状态,此时它记录下用户发送一条新消息;
3)策略模块(Policy)从Tracker中取出对话的最新状态;
4)由Policy来决定系统的下一个动作(Action)是什么,调用某个API或是直接给用户发送一段文字消息;
5)Tracker记录下被选中的Action;
6)系统执行选中的Action,用户收到对话系统的反馈。
目前学术界的研究热点是用端到端(end-to-end)的方式训练整个对话系统【2】【3】,但这种方式存在种种局限,尚未在业界得到广泛应用。当前流行的做法依然是分别训练不同模块,然后组合在一起。
用深度学习处理自然语言
过去的几年时间,深度学习在自然语言处理领域牢牢占据了主流地位,刷新了NLP几乎所有领域的state-of-the-art。对话系统的开发过程同样也大量涉及到各种深度学习算法。文章后面的篇幅,我们会重点讲述用深度学习来处理文本的思路。
- 通用的深度学习框架
自然语言处理领域中的任务多种多样,但用深度学习来处理这些任务的流程却有一定相似之处,这里给大家介绍spaCy作者Matthew Honnibal总结的深度学习NLP四部曲【4】:

第一步:Embed
我们把句子拆解成一个个独立单元(字或是词),然后选用特定的向量(vector)来表示某一类相同的特定单元。选择向量的原则是使意思相近单元所对应的向量拥有尽可能小的空间距离。完成这一步骤的常见算法有word2vec,glove和fasttext等,通过这些算法得到的向量中包含了一定的上下文信息,可以帮助提升模型的效果。另外,也可以将其他数据拼接到向量中,比如分词过程中得到的词性信息等。
第二步:Encode
用上一步骤中的词向量将句子中对应的词替换掉,我们就得到了句子的向量序列。词向量的简单堆砌只是句子最原始的表达方式,并不能高效表征句子意思,需要结合上下文做进一步的编码处理。常用的编码方式有卷积神经网络(CNN),循环神经网络(RNN)或是两者的组合。众所周知,CNN的计算速度快于RNN,因此出于系统性能方面的考虑,业界CNN用得更多。编码的输出是一个有效表征句子意思的矩阵。第三步:Attend
句子矩阵的不同部分,对于模型来讲,其重要性是不同的,这一步骤的主要思想是在训练过程中,让模型自行“划重点”,更多地关注句子中能够解决当前任务的部分。该过程又称为注意力机制(Attention Mechanism),在具体实现形式上表现为特征降维,视模型任务不同,可以是单个句子矩阵,也可以是多个句子矩阵拼在一起进行降维。第四步:Predict
流程的最后,我们利用上一步的输出来完成预测任务,用到的方法通常是全连接前向神经网络。模型输出视prediction target而定,可以是表征概率的实数,也可以是向量。
- 用深度学习来判断用户意图
对话系统的开发中,判断用户意图的方法有很多,而对于较大规模的知识库(knowledge base),出于响应速度和准确率两个方面的考虑,常见做法是先做检索(retrieval),召回少量候选用户意图(candidate),然后做精准排序(ranking),最后选择排名最高的候选意图作为识别结果来决定系统的下一步动作。
在此过程中,有一个重要任务:计算两个句子之间的相似度(sentence similarity)。解决该问题的深度学习算法大致可以分为两类,分别基于句子编码(sentence encoding)和句子交互(sentence interaction)。
下图是一个比较典型的sentence-encoding模型【5】,句子首先被编码成pooled representation,然后拼接各种interaction和non-interaction特征得到joint layer,最后用一个前向神经网络来预测两个句子之间的相似度。这种结构也被称为“Siamese Network”:
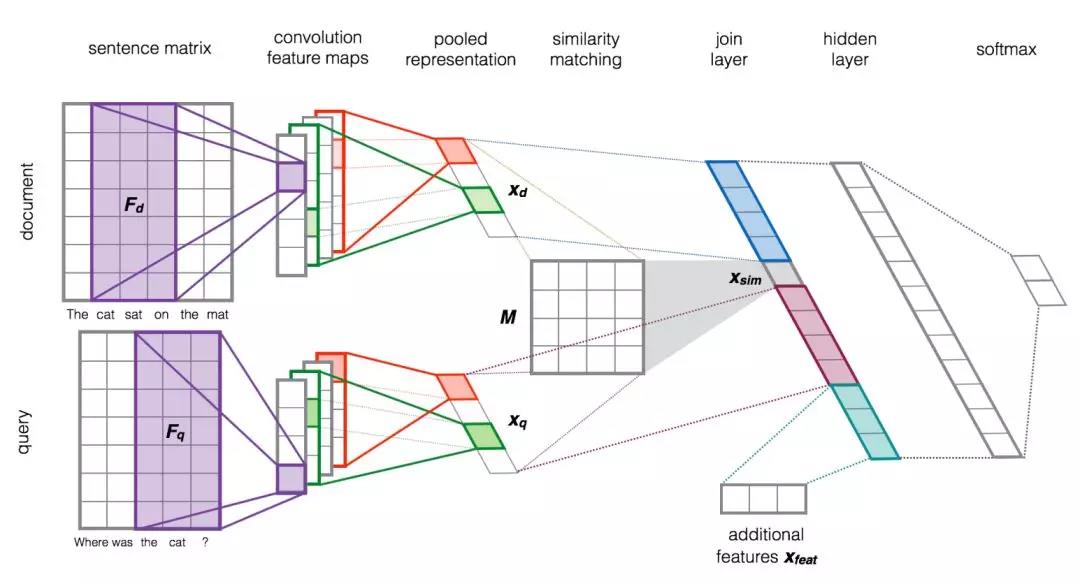
再举一个sentence-interaction模型的典型例子【6】,我们可以认为这个模型跳过了四部曲中的第二步(Encode),后面接了一个广义的Attention:

一般说来,sentence-interaction类模型表达能力更强,在准确率上有一定优势,但sentence-encoding类方法更加适用于需要对knowledge base进行预处理的场景。
另外,与传统方法相结合,可以明显提高模型性能。业界常见的一个做法用Apache Lucene【7】对knowledge base做索引,然后以用户问题作为query计算其与整个KB的相似度,得到的TF-IDF similarity既可以做前期召回(recall)的依据,也可以作为基础feature输入到后续的ranking model。
值得一提的是,计算sentence similarity也可以参见kaggle上的一个比赛“Quora Question Pairs”【8】,选手们解决问题的思路非常有参考价值(虽然数据集的leakage把大家都带到沟里去了)。
后记
过去的一年里,我们拍拍贷的数据研发团队从零搭建起了一套智能客服系统。依托拍拍贷庞大的业务量,小娜机器人1.0版本上线短短数月,已累计服务几十万用户,大大减轻了客服部门的业务压力,同时也为公司节省了大量的人力成本。
目前,我们正在开发2.0版本,为小娜添加更多的功能,让她更加善解人意,给用户提供更多帮助。欢迎有兴趣的同学加入!
参考文献
【1】 https://rasa.ai/products/rasa-core/
【2】 Bordes A, Boureau Y, Weston J, et al. Learning End-to-End Goal-Oriented Dialog. arXiv: Computation and Language, 2016.
【3】Wen T, Vandyke D, Mrksic N, et al. A Network-based End-to-End Trainable Task-oriented Dialogue System. conference of the european chapter of the association for computational linguistics, 2017.
【4】 https://explosion.ai/blog/deep-learning-formula-nlp
【5】 Severyn, Aliaksei, and Alessandro Moschitti. “Learning to rank short text pairs with convolutional deep neural networks.” Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 2015.
【6】 Hu, Baotian, et al. “Convolutional neural network architectures for matching natural language sentences.” Advances in neural information processing systems. 2014.
【7】 https://lucene.apache.org/
【8】 https://www.kaggle.com/c/quora-question-pairs