
【导语】客户是上帝的时代,服务质量对任何一家2B或2C企业而言都至关重要,如何对人力密集型行业的呼叫中心部门做高效的服务质量监控和优化是一个巨大的挑战。 在这样一个要求质检效率的背景下,拍拍贷孵化了一款服务质检人员的智能产品–——质检机器人,本文就对产品的功能和算法框架做一个简要介绍。
– 【背景与现状】 –
金融科技服务行业的许多环节需要专业人员以电话形式向用户提供定向服务,如客服、贷前运营和贷后管理等部门。坐席的通话质量、服务的专业性会直接或间接影响到客户体验和满意度。传统的人工质检方法需要质检人员通过抽检的方式进行测听给出结论,这种方式存在如下几个问题:


质检机器人的诞生,正是为了攻克以上问题,通过算法和工程的方式对录音数据进行自动化质检点检测,助力实现质检全覆盖,规则定制化,质检结果可视化,复检监控一体化的功能。

– 【质检机器人的质检范围】 –
在介绍算法流程前,首先需要搞明白质检员都要质检什么?
在拍拍贷的各类业务场景中,经常会碰到很多奇形怪状但又至关重要的质检点,从业务和算法实现角度,我们罗列了四类较为典型的场景:
1.规则类:可以通过关键词和关联逻辑进行描述的质检点,如业务禁语或违规词;
2.场景类:需要根据上下文,假设出现了A类场景的情况下(关键词/第几通电话/提了某问题),在后续的多长时间内,需要有B类应答,如客服是否给出有效回答;
3.情绪类:需要根据声音、情绪、以及文本进行综合性判断,如判断坐席服务态度是否友好;
4.交互类:场景类需求的前提下,需要进一步核对后台数据,进行判断,如坐席对身份核身的准确性。
– 【质检机器人的算法流程】 –
那么质检机器人到底可以做什么呢?
质检机器人主要运用语音和自然语言处理方法,对电话语音中的内容进行多角度的分析,模型技术主要涉及到模式匹配、文本相似度识别、语音情绪识别等方法。现有的智能质检流程如下:

1.输入层:运用语音转写技术将需要质检的录音转化成文本,对文本和语音数据进行预处理。
2.算法层:常规的质检算法流程主要集中在规则配置和正则匹配上,例如,质检员需要检查坐席小A在和客户问候时是否有提及“拍拍贷”,解析成规则即“是否包含关键词-拍拍贷”, 算法层面即会转换成对应的正则模式“.*拍拍贷.*”,进行模式匹配。这种单一算法在场景拓展和准确性提升上存在很大的局限性。
不同于常规的质检算法,除了正则方法的模式匹配外,我们会将文本和声学模型结合,建立相关的LSTM网络模型进行模型融合,集成后的模型结果在准确度和稳定性上都有一定的优势。
3.前端层:罗马非一日建成,为了保证结果的准确性和稳定性,在产品前端层面,前期需要建立相应的人工复检和反馈机制,为模型的在线迭代更新提供更多样本积累。
– 【质检机器人的模型功能】 –
在类智能产品的算法开发过程中,通常不会拘泥于单一问题的解决方案,而是会从多个维度衡量算法对场景的适应性和延展性,在质检机器人的开发过程中遇到类似问题时,我们启动了hard模式。
模式一:规则算法的可延展性
在针对规则类和场景类问题的算法应用上,传统的方式是:关键词的模糊匹配、正则表达式、语义匹配等方法。这些方法存在两个明显的缺陷:
- 人为的规则制定是无法穷举实际对话中所有的关键词或规则表达式;
- 复杂难解释的规则匹配较难适应质检标准的多变性和灵活性。
为了解决这些问题,我们进行了两种改进:
1.文本LSTM预测:
在规则模式匹配的基础上,我们尝试添加针对短文本的标签分类算法,来适应更多的语义组合。这里采用了LSTM(Long Short Term)算法,其原理和RNN相似,RNN网络能够把前置输入的信息往后传播,适合处理时间序列的数据以及需要结合前后信息的数据。LSTM是RNN的升级版,本质上能更好的保存多级且长期的输入样本特征。
在质检的文本对话场景里,在对分割好角色的文本进行分词和切词等预处理工作后,我们需要对文本做一个字符到数字的映射,这里我们会将真实对话场景中的所有词汇根据词频进行排序编码,对应的编码最终映射到每一句对话的短文本上。
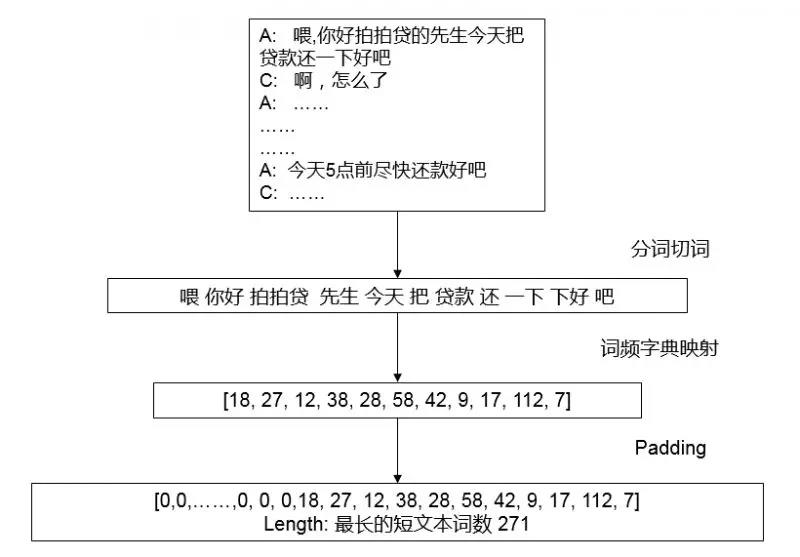
短文本数据预处理
对预处理后的数据会建立Embedding词向量矩阵,将每一个词初始化成N维的词向量,进行LSTM模型训练。
如下是网络结构,多层的LSTM训练效果经尝试被证明比单层的分类效果更优,模型最终的结果反映了每句话触碰到相应规则的概率。相较于单一的规则匹配,LSTM算法能更好地考虑前后词的关系,可以覆盖更多形式的文本样例,帮助提高模型的召回率(Recall)。
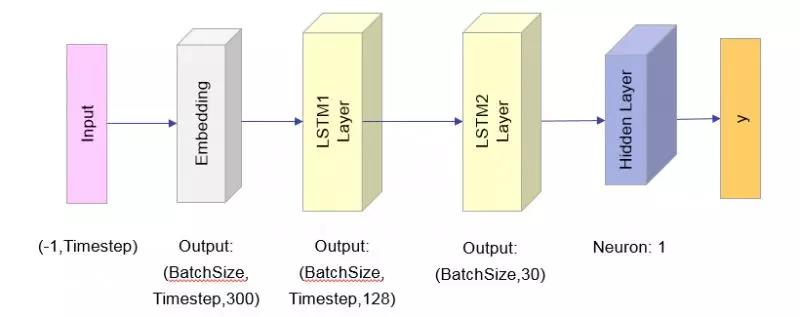
网络结构
2.规则配置管理:
有的质检小伙伴可能会说:“这个正则规则好复杂呀,我不会写怎么办,还有我想修改一下上个星期提交的质检规则是否可以呢?
为了满足质检标准的多变性,我们设立了规则编辑功能,让质检员可以自主编辑关键词和规则运算符,相较于难懂的逻辑运算符(&&, ||, !), 我们将其具象成对应的链接符号和图标,帮助业务人员自主进行任意的规则配置。除此之外,相关的同义词联想功能的建立可以帮助缓解同一语义不同形式的问题。

规则编辑示意图
另外,在面对更为复杂的场景类问题时,一条标准通常会包含多个质检点,我们提供了场景分割和规则命名功能,对业务场景(如是否借款用户本人来电)、质检角色(坐席还是客服)、质检范围(如第一句到第三句)都可做相应设置。这样,一个标准的规则编辑流程会将质检员眼中关于质检标准的自然语言解析拆分成模型算法可以读懂的逻辑语言,满足了场景拓展的灵活性。

场景分割和规则配置流程
模式二:声学模型的应用
质检的输入数据实际是语音而非文本,对语音数据的直接处理能力的效果会比单纯使用文本模型果更胜一筹,增加声学模型可以帮助我们:
- 弥补语音转写造成的错误率;
- 针对解决情绪类问题的质检点。

五类情绪分
情绪识别是声学模型的一个应用,通过人的声音提取时域频域序列特征,构建五类有标签的情绪分类模型。如下图所示,我们会对每一句话进行情绪打分,在检测服务态度违规的案例中,会发现情绪分(Anger)的分布和正常对话相比有显著的差异:
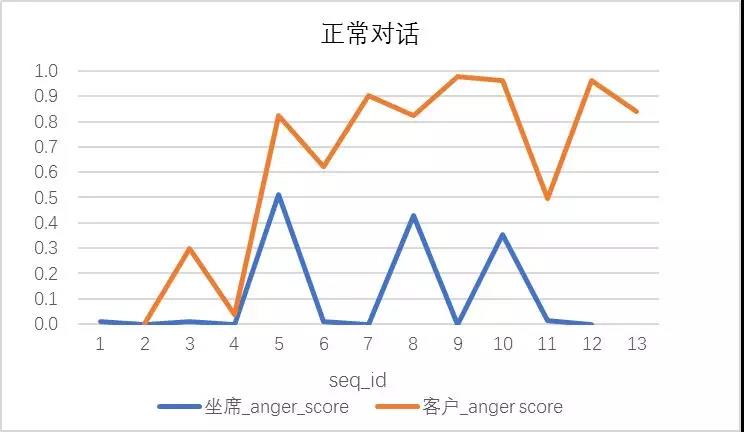

在实际应用中,我们将声音和文本分输出,额外考虑语速、时长等聚合变量进行模型融合,有效解决了正则规则的不灵活和文本的翻译质量问题,准确度(Precision)和召回率(Recall)都有所提升。

模型聚合变量维度和融合后的Precision和Recall效果

质检模型优化流程
– 【后记】 –
质检机器人产品内部测试上线后,日均覆盖录音量2万通,和人工的2000通相比,已经达到了10倍的效率提升,准确度提升了25%,大大扩大了质检范围,提高了质检效率,并且带动提升了整体的服务质量,并且这些数字还在不断增长迭代。
本文主要是针对智能质检在各类场景中的模型应用做了简要的介绍,由于质检机器人本质是一款服务产品,有关算法和产品功能的融合,智能质检和人工质检的关系等问题还有很大的探索空间,我们后续仍会在场景功能和算法工程上做更多尝试,致力于可以“给质检员一件武器,让他们变成超级质检员”。